- 开始
- Array includes 方法
- 求幂运算符(**)
- Async Functions
- SharedArrayBuffer
- Object.values 和 Object.entries
- String padding
- 结尾逗号
- 对象的 Rest /Spread 属性
- Asynchronous iteration (异步迭代)
- Promise.prototype.finally()
- 正则扩展—先行断言以及后行断言
- 正则扩展—命名捕获组
- 正则扩展—Unicode转义
- Array的 flat()方法和flatMap()方法
- String的trimStart()方法和trimEnd()方法
- Object.fromEntries()
- 参考
开始
- ES7(2016)
- Array includes方法
- 求幂运算符
- ES8(2017)
- Async Functions
- SharedArrayBuffer和Atomics
- Object.values 和 Object.entries
- String padding
- Object.getOwnPropertyDescriptors()
- 函数参数列表和调用中的尾逗号
- ES9(2018)
- 对象的Rest以及Spread
- Asynchronous iteration
- Promise.prototype.finally()
- 正则扩展—先行断言以及后行断言
- 正则扩展—Unicode转义
- 正则扩展—命名捕获组
- ES10(2019)
- Array的flat()方法和flatMap()方法
- String的trimStart()方法和trimEnd()方法
- Object.fromEntries()
Array includes 方法
includes() 方法用来判断数组中是否包含一个特定的值,如果包含 ,返回true,若不包含,返回false。
- 简便的判断
includes() 方法返回值是布尔值可以直接在if判断,而indexOf返回的是值类型 -1,判断时候更加冗余。
const ary = [0];if (ary.indexOf(0) !== -1) {console.log("存在")}if (ary.includes(1)) {console.log("存在")}else{console.log("不存在")}
indexOf 无法对NaN进行准确的判断,includes 可以对于进行正确判断。
当数组值为空,indexOf 判断空为 -1,includes则会进行正确的判断。
- 对于 NaN、underfind 、null 的判断
const ary = [null,NaN];console.log(ary.indexOf(null)) //0console.log(ary.includes(null)) //trueconsole.log(ary.indexOf(NaN)) //-1console.log(ary.includes(NaN)) //trueconsole.log(ary.indexOf(undefined)) //-1console.log(ary.includes(undefined)) //false
求幂运算符(**)
很简单的语法糖 Math.pow的替代品,Math.pow(2,3) 等同于 2 ** 3。
Async Functions
谷歌中默认启用异步函数,我们可以利用 async/await 像编写同步代码一样的编写基于Promise的代码,当您使用await某个Promise 时,函数暂停执行,直到Promise执行返回结果,这种暂停不会阻塞主线程,如果Promise执行,则返回值,如果拒绝,则返回错误值。
async/await 会提高代码的可读行,去掉层层回调。
function logFetch(url) {return fetch(url).then(response => response.text()).then(text => {console.log(text);}).catch(err => {console.error('fetch failed', err);});}
使用async/await改写:
async function logFetch(url) {try {const response = await fetch(url);console.log(await response.text());}catch (err) {console.log('fetch failed', err);}}
使用async/await 构建 api模块: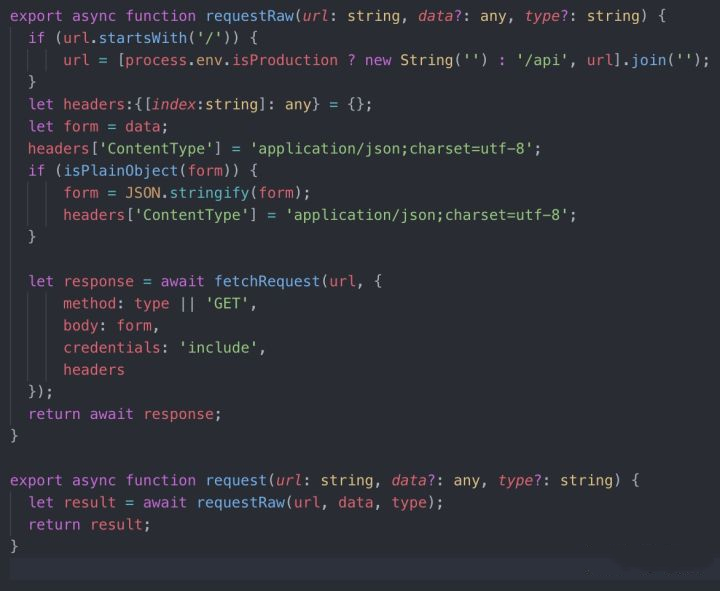
SharedArrayBuffer
在了解SharedArrayBuffer之前我们首先要了解一下内存之类的知识。
假如我们要将一个数字放进内存中,我们会首先将它转化为32位或者64位字大小,如果要放入一个非数字,JS Engine会通过编码器运行该值,然后通过编码方式,例如UTF-8,获取该值得二进制表示。JS引擎会在内存中找到可以存放此二进制的位置,进行分配内存,之后js引擎会持续跟踪该变量是否仍可从程序中的任何位置访问。如果无法再访问该变量,则将回收内存,以便JS引擎可以在其中放置新值。如果无法在访问到它们,则进行清除,此过程称为垃圾回收。JS类语言称为内存管理语言,它并不会直接操作内存,自动管理内存会使管理人员更加轻松,但是会产生一定的性能开销。
但是,例如C等手动管理内存语言,C没有JavaScript在内存上做的那个抽象层。相反,你直接在内存上运行。您可以从内存加载内容,并可以将内容存储到内存中。假如React使用C写出来,那么它可以借助WebAssembly来进行内存管理,关于什么是WebAssembly?
WebAssembly是一种新的编码方式,可以在现代的网络浏览器中运行 - 它是一种低级的类汇编语言,具有紧凑的二进制格式,可以接近原生的性能运行,并为诸如C / C ++等语言提供一个编译目标,以便它们可以在Web上运行。它也被设计为可以与JavaScript共存,允许两者一起工作。对于网络平台而言,WebAssembly具有巨大的意义——它提供了一条途径,以使得以各种语言编写的代码都可以以接近原生的速度在Web中运行。在这种情况下,以前无法以此方式运行的客户端软件都将可以运行在Web中。
WebAssembly被设计为可以和JavaScript一起协同工作——通过使用WebAssembly的JavaScript API,你可以把WebAssembly模块加载到一个JavaScript应用中并且在两者之间共享功能。这允许你在同一个应用中利用WebAssembly的性能和威力以及JavaScript的表达力和灵活性,即使你可能并不知道如何编写WebAssembly代码。
那么,我们为什么需要ArrayBuffers?ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。ArrayBuffer 不能直接操作,而是要通过类型数组对象或[DataView](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/DataView)对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容。
即使你在JS中也可以通过ArrayBuffer对内存数据进行处理,你为什么需要进行处理?正如前面所说的自动内存管理语言对于内存处理都有一种权衡,增加一些开销,某种程度会导致性能问题。JS对于新创建的变量,因为引擎会对其进行分析,所以可能需要要为它进行预留大约2倍以上内存空间,这可能导致内存大量的浪费。
var buffer = new ArrayBuffer(8);console.log(buffer.byteLength);// expected output: 8
除了使用ArrayBuffer时,您不能将任何JavaScript类型放入其中,如对象或字符串。您可以添加的唯一内容是字节,实际上并没有将这个字节直接添加到ArrayBuffer中。就其本身而言,这个ArrayBuffer不知道该字节应该有多大,或者不应该将不同类型的数字转换为字节。ArrayBuffer本身只是一堆零和一行。ArrayBuffer不知道该数组中第一个元素和第二个元素之间的除法位置。
为什么我们需要SharedArrayBuffer?
ArrayBuffers可以减少主线程必须完成的工作量。更加高效的做法是分开进行工作,在其他语言中使用线程来进行分解工作,在JS中使用Web Worker,但是他们不像其他语言一样,它们是不共享内存的,也就是你干你的,我干我的。如果我们想要共享某些数据就必须进行复制,通过函数postMessage来进行。postMessage接受放入的其他对象,对其进行序列化,将其发送给其他Web工作者,然后将其反序列化并放入内存中。对于某些类型的数据,如ArrayBuffers,您可以执行所谓的传输内存。这意味着移动特定的内存块,以便其他Web工作者可以访问它。但是第一个Web工作者再也无法访问它了。
使用SharedArrayBuffer,两个Web工作者(两个线程)都可以写入数据并从同一块内存中读取数据。这意味着他们没有使用postMessage的通信开销和延迟。两个Web工作人员都可以立即访问数据。但是,同时从两个线程立即访问存在一些危险。它可以导致所谓的竞争条件。
Object.values 和 Object.entries
这两个api就比较简单了。
Object.values()方法返回一个给定对象自身的所有可枚举属性值的数组,值的顺序与使用for…in循环的顺序相同 ( 区别在于 for-in 循环枚举原型链中的属性 )。
var obj = { foo: 'bar', baz: 42 };console.log(Object.values(obj)); // ['bar', 42]// array like objectvar obj = { 0: 'a', 1: 'b', 2: 'c' };console.log(Object.values(obj)); // ['a', 'b', 'c']
Object.entries()方法返回一个给定对象自身可枚举属性的键值对数组,其排列与使用for…in 循环遍历该对象时返回的顺序一致(区别在于 for-in 循环也枚举原型链中的属性)。
const obj = { foo: 'bar', baz: 42 };console.log(Object.entries(obj)); // [ ['foo', 'bar'], ['baz', 42] ]// array like objectconst obj = { 0: 'a', 1: 'b', 2: 'c' };console.log(Object.entries(obj)); // [ ['0', 'a'], ['1', 'b'], ['2', 'c'] ]
String padding
padStart()方法用另一个字符串填充当前字符串(重复,如果需要的话),以便产生的字符串达到给定的长度。填充从当前字符串的开始(左侧)应用的。
padEnd() 方法会用一个字符串填充当前字符串(如果需要的话则重复填充),返回填充后达到指定长度的字符串。从当前字符串的末尾(右侧)开始填充。
'abc'.padStart(10); // " abc"'abc'.padStart(10, "foo"); // "foofoofabc"'abc'.padStart(6,"123465"); // "123abc"'abc'.padStart(8, "0"); // "00000abc"'abc'.padStart(1); // "abc"'abc'.padEnd(10); // "abc "'abc'.padEnd(10, "foo"); // "abcfoofoof"'abc'.padEnd(6, "123456"); // "abc123"'abc'.padEnd(1); // "abc"
结尾逗号
自我认为此新特性唯一好处就是代码结构更加明了,易读。当你需要再次增加属性时候,方便许多。。。。。
let obj = {first: 'Cat',last: 'Dog',};let arr = ['red','green','blue',];
对象的 Rest /Spread 属性
在ES6数组中,我们引入了 Rest /Spread属性。
// Restvar numbers = [1, 2, 3, 4, 5][first, second, ...others] = numbers// Spreadvar numbers = [1, 2, 3, 4, 5]var sum = (a, b, c, d, e) => a + b + c + d + evar sum = sum(...numbers)
在ES9中可以在对象中使用此属性。
// Restvar { first, second, ...others } = { first: 1, second: 2, third: 3, fourth: 4, fifth: 5 }first // 1second // 2others // { third: 3, fourth: 4, fifth: 5 }// Spreadvar items = { first, second, ...others }items //{ first: 1, second: 2, third: 3, fourth: 4, fifth: 5 }
Asynchronous iteration (异步迭代)
新的for-await-of构造允许您使用异步可迭代对象作为循环迭代:
for await (const o of array) {console.log(o)}
Promise.prototype.finally()
finally()允许您运行一些代码,无论 promise 的执行成功或失败。
fetch('xxx').then(console.log('成功')).catch(error => console.error(error)).finally(() => console.log('结束'))
正则扩展—先行断言以及后行断言
先行断言(lookahead):您可以使用 ?= 匹配一个字符串,该字符串后面跟着一个特定的子字符串,?!执行逆操作,匹配一个字符串,该字符串后面没有一个特定的子字符串。
先行断言(lookahead)使用?=符号。
/a(?= b)/.test('a c b') //false/a(?= b)/.test('a b c') //true/a(?! b)/.test('a c b') // true/a(?! b)/.test('a b c') // false
上面例子表示的是 a 的后面是 b 采用的是先行断言。
/(?<=a) b/.test('c b') //false/(?<=a) b/.test('a b') // true/(?<!a) b/.test('c b') //true/(?<!a) b/.test('a b') // false
上面例子表示的是 b 的前面是 a 采用的是后行断言。
正则扩展—命名捕获组
在 ES2018 中,可以为捕获组分配一个名称,而不是仅在结果数组中分配一个 slot(插槽):
const re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/const result = re.exec('2019-05-30')// result.groups.year === '2019';// result.groups.month === '05';// result.groups.day === '30';
正则扩展—Unicode转义
Unicode 标准为每个符号分配各种属性和属性值,比如希腊字母π在 Unicode 中有独特的属性和属性值,在ES9之前,我们是无法直接匹配这种独特的属性,只能借助一些正则表达式的库,例如 xregexp 这种正则表达式的库,来创建增强型的正则表达式。
const regexGreekSymbol = XRegExp('\\p{Greek}', 'A')regexGreekSymbol.test('π') // true
这种库是运行时的依赖,不利于性能要求较高的web应用,并且 当Unicode 标准更新时,必须要更新 xregexp 才能使用新数据,至于π 为什么是Greek,需要参看 Unicode编码表。
在新功能中使用 \p{} 匹配所有 Unicode 字符,否定为 \P{}。
任何 unicode 字符都有一组属性。 例如,Script确定语言系列,ASCII是一个布尔值, 对于 ASCII 字符,值为true,依此类推。 您可以将此属性放在花括号中,正则表达式将检查是否为真。
/^\p{ASCII}+$/u.test('eee') // true/^\p{ASCII}+$/u.test('EEE1@') // true/^\p{ASCII}+$/u.test('WWW🙃') // false
我们可以在Unicode字符数据库找到所有对应的属性,例如还有ASCII_Hex_Digit,Uppercase,Lowercase,White_Space,Alphabetic,Emoji 等,ASCII_Hex_Digit是另一个布尔属性,用于检查字符串是否仅包含有效的十六进制数字。以及可以检查语言例如希腊语以及印度语。
/^\p{ASCII_Hex_Digit}+$/u.test('555ABCDEF') // true/^\p{ASCII_Hex_Digit}+$/u.test('h') // false/^\p{Lowercase}$/u.test('a') // true/^\p{Uppercase}$/u.test('A') // true/^\p{Emoji}+$/u.test('B') // false/^\p{Emoji}+$/u.test('🙃🙃') // true^\p{Script=Greek}+$/u.test('η?') // true/^\p{Script=Latin}+$/u.test('hey') // true
优点:
- 不需要运行时依赖
- 正则表达式不需要使用 Unicode 区间来判断特点的内容
- Unicode 属性转义自动保持最新,每当 Unicode 标准更新时,ECMAScript 引擎更新其数据即可
Array的 flat()方法和flatMap()方法
flat() 方法会按照一个可指定的深度递归遍历数组,并将所有元素与遍历到的子数组中的元素合并为一个新数组返回。flat()方法主要作用有两个方面:
- 扁平化数组,并且可以指定扁平化的层级depth
- 移除数组中的空项
- 不改变原数组
var arr1 = [1, 2, [3, 4]];arr1.flat();// [1, 2, 3, 4]var arr2 = [1, 2, [3, 4, [5, 6]]];arr2.flat();// [1, 2, 3, 4, [5, 6]]var arr3 = [1, 2, [3, 4, [5, 6]]];arr3.flat(2);// [1, 2, 3, 4, 5, 6]//使用 Infinity 作为深度,展开任意深度的嵌套数组arr3.flat(Infinity);// [1, 2, 3, 4, 5, 6]// 移除空项var arr4 = [1, 2, , 4, 5];arr4.flat();// [1, 2, 4, 5]
这里涉及到一个前端面试题,如何扁平化数组?在没有api支持之前,我们是这样做的:
var arr1 = [1, 2, [3, 4]];arr1.flat();方法一:// 反嵌套一层数组arr1.reduce((acc, val) => acc.concat(val), []);// [1, 2, 3, 4]方法二:// 或使用 ...const flatSingle = arr => [].concat(...arr);方法三:递归function flatten(arr) {var result = [];for (var i = 0, len = arr.length; i < len; i++) {if (Array.isArray(arr[i])) {result = result.concat(flatten(arr[i]))}else {result.push(arr[i])}}return result;}方法四:toString()function flatten(arr) {return arr.toString().split(',').map(function(item){return +item})}
flatMap()
flatMap() 方法首先使用映射函数映射每个元素,然后将结果压缩成一个新数组。它与map 和 深度值1的 flat 几乎相同,但 flatMap通常在合并成一种方法的效率稍微高一些。 返回一个新的数组,其中每个元素都是回调函数的结果,并且结构深度depth值为1。
注意:只会将 flatMap 中的函数返回的数组 “压平” 一层
var arr1 = [1, 2, 3, 4];arr1.map(x => [x * 2]);// [[2], [4], [6], [8]]arr1.flatMap(x => [x * 2]);// [2, 4, 6, 8]// 只会将 flatMap 中的函数返回的数组 “压平” 一层arr1.flatMap(x => [[x * 2]]);// [[2], [4], [6], [8]]let arr = ["今天天气不错", "", "早上好"]arr.map(s => s.split(""))// [["今", "天", "天", "气", "不", "错"],[""],["早", "上", "好"]]arr.flatMap(s => s.split(''));// ["今", "天", "天", "气", "不", "错", "", "早", "上", "好"]
String的trimStart()方法和trimEnd()方法
String.trimStart()可用于从字符串的开头去掉空白,trimLeft()是此方法的别名。注意:trimStart()方法返回的是一个新的字符串,并不改变原来的字符串。并且新字符串的长度会改变。
var text = ' Hello world! ';console.log(text); //" Hello world! "console.log(text.trimStart()); // "Hello world! "console.log(text) //" Hello world! "// lengthvar str = ' foo ';console.log(str.length); // 8str = str.trimStart();console.log(str.length); // 5console.log(str); // 'foo '
String.trimEnd()可用于从字符串的尾部去掉空白。trimRight()是此方法的别名。注意:返回一个新字符串,表示从其(右)端剥去空白的调用字符串。同样,新字符串长度会改变。
var text = ' Hello world! ';console.log(text); // " Hello world! "console.log(text.trimEnd()); // " Hello world!"var str = ' foo ';console.log(str.length); // 8str = str.trimEnd();console.log(str.length); // 6console.log(str); // ' foo'
Object.fromEntries()
Object.fromEntries()创建一个对象或将键值对转换为一个对象。注意:它只接受Iterable迭代 例如:Object.fromEntries(Iterable)。 返回值是一个新对象,其属性由iterable的条目给出。
// 情况一:将Map为Objectlet entries = new Map([["name", "deep"], ["age", 26]]);console.log(Object.fromEntries(entries));// { name: 'deep', age: 26 }// 情况二:将一个转换Array为一个Objectconst arr = [ ['0', 'a'], ['1', 'b'], ['2', 'c'] ];const obj = Object.fromEntries(arr);console.log(obj); // { 0: "a", 1: "b", 2: "c" }// 情况三: 使用Object.fromEntries其反向方法Object.entries()和数组操作方法const object1 = { a: 1, b: 2, c: 3 };const object2 = Object.fromEntries(Object.entries(object1).map(([ key, val ]) => [ key, val * 2 ]));console.log(object2);// { a: 2, b: 4, c: 6 }
参考
- ES7 ES8 ES9 ES10 新特性总结思考 - deep的文章 - 知乎 https://zhuanlan.zhihu.com/p/67492465

若有收获,就点个赞吧
0 人点赞
