Python 有很多内置的模块和函数可用于文件的操作处理,这些函数都分布在几个模块上:如 os,os.path,shutil 和pathlib 等等。本文收集了许多您需要知道的函数,以便在 Python 中对文件执行最常见的操作。
通过本教程,你可以:
- 检索文件属性
Retrieve file properties - 创建目录
Create directories - 基于文件名的模式匹配
Match patterns in filenames - 遍历目录树
Traverse directory trees - 创建临时文件和目录
Make temporary files and directories - 删除文件和目录
Delete files and directories - 拷贝、转移、重命名文件和目录
Copy, move, or rename files and directories - 创建和提取 ZI P和 TAR 打包
Create and extract ZIP and TAR archives - 使用
fileinput模块打开多个文件
Open multiple files using the fileinput module
Python 读写数据到文件
使用 Python 读取和写入文件数据非常简单。 为此,我们必须首先以适当的模式打开文件。 以下是如何打开文本文件并读取其内容的示例:
with open('data.txt', 'r') as f:data = f.read()
open() 接受文件名和模式作为参数。 r 是以只读模式打开文件。如果要将数据写入文件,请将w作为参数传入:
with open('data.txt', 'w') as f:data = 'some data to be written to the file'f.write(data)
在上面的示例中,open() 打开用于读取或写入的文件,并返回文件句柄(在本例中为 f),该句柄提供可用于读取或写入文件数据的方法。 更多有关如何读取和写入文件的更多信息,参考:Working With File I/O in Python 。
获取目录列表
假设您当前的工作目录有一个名为 my_directory 的子目录,其中包含以下内容:
.├── file1.py├── file2.csv├── file3.txt├── sub_dir│ ├── bar.py│ └── foo.py├── sub_dir_b│ └── file4.txt└── sub_dir_c├── config.py└── file5.txt
内置的os模块有许多有用的功能,可用于列出目录内容并过滤结果。 要获取文件系统中特定目录下的所有文件和文件夹的列表,请在旧版本的 Python 中使用os.listdir();或在 Python 3.x 中使用os.scandir()。 如果你还想获取文件和目录属性(如文件大小和修改日期),则os.scandir()是首选方法。
在传统 Python 版本中获取目录列表
在 Python 3 之前的 Python 版本中,os.listdir() 是用于获取目录列表的方法:
>>> import os>>> entries = os.listdir('my_directory/')
os.listdir() 返回一个 Python 列表,其中包含 path 参数下目录中的文件和子目录的名称:
>>> os.listdir('my_directory/')['sub_dir_c', 'file1.py', 'sub_dir_b', 'file3.txt', 'file2.csv', 'sub_dir']
像这样列出的目录列表不容易阅读。使用循环打印出对os.listdir()的调用输出,有助于(后续的目录和文件)清理:
>>> entries = os.listdir('my_directory/')>>> for entry in entries:... print(entry)......sub_dir_cfile1.pysub_dir_bfile3.txtfile2.csvsub_dir
在现代 Python 版本中的获取目录列表
在现代版本的 Python 中,os.listdir()的替代方法是使用os.scandir()和pathlib.Path()。
os.scandir() 是在 Python 3.5 中引入的,并在 PEP 471 中有记录。os.scandir()在调用时返回一个迭代器(iterator)而不是列表:
>>> import os>>> entries = os.scandir('my_directory/')>>> entries<posix.ScandirIterator object at 0x7f5b047f3690>
ScandirIterator 对象指向当前目录中的所有条目。我们可以遍历迭代器的内容并打印出文件名:
import oswith os.scandir('my_directory/') as entries:for entry in entries:print(entry.name)
在这里,os.scandir()与with语句一起使用,因为它支持上下文管理器协议(the context manager protocol)。 使用上下文管理器可以关闭迭代器并在迭代器耗尽后自动释放获取的资源。 结果是打印出 my_directory 中的文件名,就像在os.listdir()示例中看到的那样:
sub_dir_cfile1.pysub_dir_bfile3.txtfile2.csvsub_dir
获取目录列表的另一种方法是使用pathlib模块:
from pathlib import Pathentries = Path('my_directory/')for entry in entries.iterdir():print(entry.name)
Path 方法返回的对象是 PosixPath 或 WindowsPath 对象,具体取决于操作系统。
pathlib.Path()对象具有.iterdir()方法,用于创建目录中所有文件和文件夹的迭代器。 由.iterdir()生成的每个条目都包含有关文件或目录的信息,例如其名称和文件属性。pathlib最初是在 Python 3.4 中引入的,是 Python 的一个很好的补充,它为文件系统提供了面向对象的接口。
在上面的示例中,我们调用pathlib.Path()并将路径参数传递给它。接下来是调用.iterdir()来获取 my_directory 中所有文件和目录的列表。
pathlib提供了一组类,它们以简单,面向对象的方式展现了基于路径的大多数常见操作。 使用pathlib比使用os中的函数更有效。 使用pathlib 相比于os的另一个好处是它减少了操作文件系统路径时所需的导入数量。更多相关信息,请阅读:Python 3’s pathlib Module: Taming the File System。
运行上面的代码会产生以下结果:
sub_dir_cfile1.pysub_dir_bfile3.txtfile2.csvsub_dir
使用pathlib.Path()或os.scandir()而不是os.listdir()是获取目录列表的首选方法,尤其是在处理需要文件类型和文件属性信息的代码时。 pathlib.Path()提供了os和shutil中的大部分文件和路径处理功能,它的方法比这些模块中的方法更有效。 接下来我们将讨论如何快速获取文件属性。
以下是目录列表功能:
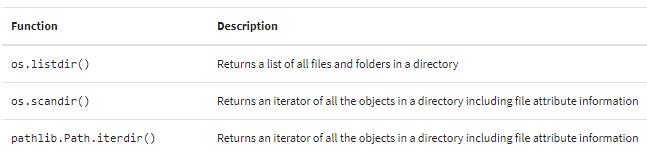
这些函数返回了一个包含了目录中所有内容的列表,包括子目录。这些操作可能并不总是您想要的。下一节我们将介绍如何从目录列表中进行结果过滤。
列出目录中的所有文件
本节将向您展示如何使用os.listdir(),os.scandir()和pathlib.Path()打印出目录中文件的名称。 如果我们要过滤目录并仅列出由os.listdir()得到的目录列表中的文件,请使用os.path:
import os# List all files in a directory using os.listdirbasepath = 'my_directory/'for entry in os.listdir(basepath):if os.path.isfile(os.path.join(basepath, entry)):print(entry)
在这里,对os.listdir()的调用返回了指定路径中的所有内容列表,然后使用os.path.isfile()过滤该列表,只打印出文件而不是目录。这会产生以下输出:
file1.pyfile3.txtfile2.csv
列出目录中文件的一个更简单方法是使用os.scandir()或pathlib.Path():
import os# List all files in a directory using scandir()basepath = 'my_directory/'with os.scandir(basepath) as entries:for entry in entries:if entry.is_file():print(entry.name)
使用os.scandir()比使用os.listdir()具有更清晰,更容易理解的优点,即使它是一行更长的代码。如果对象是文件,则对 ScandirIterator 中的每个 item 调用 entry.is_file() 将返回True的结果。打印出目录中所有文件的名称可以得到以下输出:
file1.pyfile3.txtfile2.csv
以下是使用pathlib.Path()列出目录中文件的方法:
from pathlib import Pathbasepath = Path('my_directory/')files_in_basepath = basepath.iterdir()for item in files_in_basepath:if item.is_file():print(item.name)
在这里,我们在.iterdir()产生的每个 item 上调用.is_file()。 产生的输出是相同的:
file1.pyfile3.txtfile2.csv
如果将 for 循环和 if 语句组合成单个生成器表达式,则上面的代码可以更简洁。 Dan Bader 有一篇关于生成器表达式(generator expressions)和列表推导(list comprehensions)的优秀文章,感兴趣的可以去看一下。
上面的代码,经修改后的版本如下所示:
from pathlib import Path# List all files in directory using pathlibbasepath = Path('my_directory/')files_in_basepath = (entry for entry in basepath.iterdir() if entry.is_file())for item in files_in_basepath:print(item.name)
这将产生与之前的示例完全相同的输出。本节展示了使用os.scandir()和pathlib.Path()过滤文件或目录,它们比使用os.listdir()和os.path更直观,看起来更干净。
列出子目录
要列出子目录而不是文件,请使用以下方法之一。
如何使用os.listdir()和os.path():
import os# List all subdirectories using os.listdirbasepath = 'my_directory/'for entry in os.listdir(basepath):if os.path.isdir(os.path.join(basepath, entry)):print(entry)
当您多次调用os.path.join()时,以这种方式操作文件系统路径很快就会变得很麻烦。在我的计算机上运行它会产生以下输出:
sub_dir_csub_dir_bsub_dir
如何使用os.scandir():
import os# List all subdirectories using scandir()basepath = 'my_directory/'with os.scandir(basepath) as entries:for entry in entries:if entry.is_dir():print(entry.name)
与文件列表示例中一样,此处在os.scandir()返回的每个条目上调用.is_dir()。 如果条目是目录,则.is_dir()返回True,并打印出目录的名称。输出与上面相同:
sub_dir_csub_dir_bsub_dir
如何使用pathlib.Path():
from pathlib import Path# List all subdirectory using pathlibbasepath = Path('my_directory/')for entry in basepath.iterdir():if entry.is_dir():print(entry.name)
本示例在 basepath 迭代器的每个条目上调用.is_dir()检查条目是文件还是目录 如果条目是目录,则将其名称打印到屏幕上。本示例输出与上一示例中的输出相同:
sub_dir_csub_dir_bsub_dir
获取文件属性
Python 可以轻松检索文件大小和修改时间等文件属性。这是通过os.stat(),os.scandir()或pathlib.Path()完成的。
os.scandir()和pathlib.Path()检索具有文件属性组合的目录列表。这可能比使用os.listdir()列出文件然后获取每个文件的文件属性信息更有效。
下面的示例显示了如何获取 my_directory 中文件的上次修改时间。输出以秒为单位:
>>> import os>>> with os.scandir('my_directory/') as dir_contents:... for entry in dir_contents:... info = entry.stat()... print(info.st_mtime)...1539032199.00520351539032469.63244751538998552.24029231540233322.40093161537192240.04973391540266380.3434134
os.scandir()返回一个 ScandirIterator 对象。ScandirIterator 对象中的每个条目都有一个.stat()方法,用于检索有关其指向的文件或目录的信息。.stat()提供文件大小和上次修改时间等信息。在上面的示例中,代码打印出 st_mtime 属性,该属性是上次修改文件内容的时间。
pathlib 模块也具有相应的方法,用于检索提供相同结果的文件信息:
>>> from pathlib import Path>>> current_dir = Path('my_directory')>>> for path in current_dir.iterdir():... info = path.stat()... print(info.st_mtime)...1539032199.00520351539032469.63244751538998552.24029231540233322.40093161537192240.04973391540266380.3434134
在上面的示例中,代码循环遍历.iterdir()返回的对象,并通过.stat()调用为目录列表中的每个文件检索其文件属性。st_mtime 属性返回了一个浮点值,表示自纪元以来的秒数。如果想要转换 st_mtime 返回的值以用于更直观的展示,我们可以编写一个辅助函数来将秒转换为 datetime对象:
from datetime import datetimefrom os import scandirdef convert_date(timestamp):d = datetime.utcfromtimestamp(timestamp)formated_date = d.strftime('%d %b %Y')return formated_datedef get_files():dir_entries = scandir('my_directory/')for entry in dir_entries:if entry.is_file():info = entry.stat()print(f'{entry.name}\t Last Modified: {convert_date(info.st_mtime)}')
这将首先获取 my_directory 中的文件列表及其属性,然后调用convert_date()将每个文件的上次修改时间转换为人类可读的形式。 convert_date()使用.strftime()将时间(以秒为单位)转换为字符串。
传递给.strftime()的参数如下:
- %d:the day of the month
- %b:the month, in abbreviated form
- %Y:the year
这些指令整合到一起产生如下所示的输出:
>>> get_files()file1.py Last modified: 04 Oct 2018file3.txt Last modified: 17 Sep 2018file2.txt Last modified: 17 Sep 2018
将日期和时间转换为字符串的语法可能非常混乱。要了解更多信息,请查看相关的官方文档。或者参考另一个更易于记忆的方法:http://strftime.org/。
创建目录
我们编写的程序需要创建目录以便在其中存储数据时,可以参考os和pathlib中包含用于创建目录的函数。
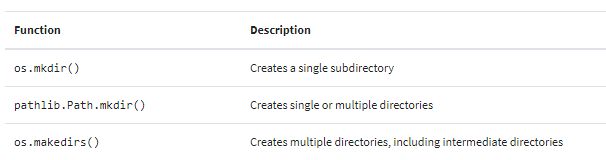
创建单个目录
要创建单个目录,请将目录路径作为参数传递给os.mkdir():
import osos.mkdir('example_directory/')
如果目录已存在,os.mkdir()会引发FileExistsError。或者,我们可以使用pathlib创建目录:
from pathlib import Pathp = Path('example_directory/')p.mkdir()
如果路径已经存在,mkdir()会引发FileExistsError:
>>> p.mkdir()Traceback (most recent call last):File '<stdin>', line 1, in <module>File '/usr/lib/python3.5/pathlib.py', line 1214, in mkdirself._accessor.mkdir(self, mode)File '/usr/lib/python3.5/pathlib.py', line 371, in wrappedreturn strfunc(str(pathobj), *args)FileExistsError: [Errno 17] File exists: '.'[Errno 17] File exists: '.'
为了避免这样的错误,可以在错误发生时捕获错误并让用户知道:
from pathlin Pathp = Path('example_directory')try:p.mkdir()except FileExistsError as exc:print(exc)
或者,我们也可以通过将exist_ok = True参数传递给.mkdir()来忽略FileExistsError:
from pathlib import Pathp = Path('example_directory')p.mkdir(exist_ok=True)
这样一来,如果目录已存在,则不会引发错误。
创建多个目录
os.makedirs()类似于os.mkdir()。两者之间的区别在于,os.makedirs()不仅可以创建单独的目录,还可以用于创建目录树。换句话说,它可以创建任何必要的中间文件夹,以确保存在完整路径。
os.makedirs()类似于在 Bash 中运行mkdir -p。例如,要创建一组目录,如2018/10/05,您只需执行以下操作:
import osos.makedirs('2018/10/05')
这将创建一个包含文件夹 2018,10 和 05 的嵌套目录结构:
.└── 2018└── 10└── 05
.makedirs()使用默认权限创建目录。如果要创建具有不同权限的目录,我们需要在调用.makedirs()时并传入我们希望在以下位置创建目录的模式:
import osos.makedirs('2018/10/05', mode=0o770)
这将创建 2018/10/05 目录结构,并为所有者和组用户提供读、写和执行权限。默认模式为0o777,并且不更改现有父目录的文件权限位。有关文件权限以及模式应用方式的更多详细信息,请参阅文档。
执行 tree 的 shell 命令以确认已应用正确的权限:
$ tree -p -i ..[drwxrwx---] 2018[drwxrwx---] 10[drwxrwx---] 05
这将打印出当前目录的目录树。tree通常用于以树状格式列出目录的内容。 将-p和-i参数传递给它会在垂直列表中打印出目录名称及其文件权限信息。-p打印出文件权限,-i使树生成一个没有缩进行的垂直列表。
如我们所见,所有目录都拥有770权限。创建目录的另一种方法是使用pathlib.Path中的.mkdir():
import pathlibp = pathlib.Path('2018/10/05')p.mkdir(parents=True)
将parents = True传递给Path.mkdir()会使其创建目录05以及使路径有效所需的任何父目录。
默认情况下,如果目标目录已存在,os.makedirs()和Path.mkdir()会引发OSError。通过在调用每个函数时传递exist_ok = True作为关键字参数,可以覆盖此行为(从 Python 3.2 开始)。
运行上面的代码会产生一个像下面一样的目录结构:
.└── 2018└── 10└── 05
我更喜欢在创建目录时使用pathlib,因为我可以使用相同的函数来创建单个或嵌套目录。
文件名模式匹配
使用上述方法之一获取目录中的文件列表后,您很可能希望搜索与特定模式匹配的文件。
这些是可以使用的方法和功能:
endswith()andstartswith()string methodsfnmatch.fnmatch()glob.glob()pathlib.Path.glob()
本节中的示例将在名为 some_directory 的目录上执行,该目录具有以下结构:
.├── admin.py├── data_01_backup.txt├── data_01.txt├── data_02_backup.txt├── data_02.txt├── data_03_backup.txt├── data_03.txt├── sub_dir│ ├── file1.py│ └── file2.py└── tests.py1 directory, 10 files
如果您正在使用 Bash shell,则可以使用以下命令创建上述目录结构:
$ mkdir some_directory$ cd some_directory/$ mkdir sub_dir$ touch sub_dir/file1.py sub_dir/file2.py$ touch data_{01..03}.txt data_{01..03}_backup.txt admin.py tests.py
这将创建 some_directory/ 目录,进入该目录,然后创建 sub_dir。第 4 行是在 sub_dir 中创建 file1.py 和 file2.py,最后一行使用扩展创建所有其他文件。 要了解有关 shell 扩展的更多信息,请访问此站点。
使用字符串方法
Python 有几种用于修改和操作字符串的内置方法。当您在文件名中使用搜索模式时,其中两个方法.startswith() 和.endswith()非常有用。为此,首先获取目录列表,然后迭代它:
>>> import os>>> # Get .txt files>>> for f_name in os.listdir('some_directory'):... if f_name.endswith('.txt'):... print(f_name)
上面的代码找到 some_directory/中的所有文件,迭代它们并使用.endswith()打印出具有.txt文件扩展名的文件名:sh
data_01.txtdata_03.txtdata_03_backup.txtdata_02_backup.txtdata_02.txtdata_01_backup.txt
使用 fnmatch 进行简单文件名模式匹配
字符串方法的匹配能力有限。但 fnmatch 具有更高级的模式匹配功能和方法。 fnmatch.fnmatch() 是一个支持使用 * 和 ? 等通配符的函数。例如,要使用fnmatch查找目录中的所有.txt文件:
>>> import os>>> import fnmatch>>> for file_name in os.listdir('some_directory/'):... if fnmatch.fnmatch(file_name, '*.txt'):... print(file_name)
这将迭代some_directory中的文件列表,并使用.fnmatch()对具有.txt扩展名的文件执行通配符搜索。
更高级的模式匹配
假设我们要查找符合特定条件的.txt文件。例如,我们可能只想查找包含单词data的.txt文件,匹配一组下划线之间的数字,或者文件名中的包含单词 backup。 类似于data_01_backup,data_02_backup或data_03_backup的东西。
>>> for filename in os.listdir('.'):... if fnmatch.fnmatch(filename, 'data_*_backup.txt'):... print(filename)
在此处,仅打印与数据_*_ backup.txt模式匹配的文件的名称。模式中的星号将匹配任何字符,因此运行以上代码将查找其文件名中以单词data开头并以backup.txt结尾的所有文本文件,如下面的输出所示:
data_03_backup.txtdata_02_backup.txtdata_01_backup.txt
使用 glob 的文件名模式匹配
模式匹配的另一个有用模块是 glob。
glob模块中的.glob()作用就像fnmatch.fnmatch()一样,但与fnmatch.fnmatch()不同的是,它把以句点(.)为开头的文件当作特殊的文件进行处理。
UNIX 和相关的系统使用 ? 和 * 通配符来把名称模式转化成文件列表。这称为通配。
例如,在 UNIX shell 中键入mv *.py python_files/会将所有具有.py扩展名的文件从当前目录移动(mv)到目录python_files。 *字符是通配符,表示”任意数量的字符”,*.py是glob模式匹配。 Windows 操作系统中不提供此 shell 功能。但glob模块在 Python 中添加了此功能,使 Windows 程序也能够使用此功能。
这是一个如何使用glob搜索当前目录中所有 Python(.py)源文件的示例:
>>> import glob>>> glob.glob('*.py')['admin.py', 'tests.py']
glob.glob ('*。py')搜索当前目录中具有.py扩展名的所有文件,并将它们作为列表返回。 glob还支持 shell 样式的通配符来匹配模式:
>>> import glob>>> for name in glob.glob('*[0-9]*.txt'):... print(name)
这将查找文件名中包含数字的所有文本(.txt)文件:
data_01.txtdata_03.txtdata_03_backup.txtdata_02_backup.txtdata_02.txtdata_01_backup.txt
glob也可以轻松地在子目录中递归搜索文件:
>>> import glob>>> for file in glob.iglob('**/*.py', recursive=True):... print(file)
此示例使用glob.iglob()来搜索当前目录和子目录中的.py文件。并通过传递recursive = True作为.iglob()的参数使其搜索当前目录和任何子目录中的.py文件。 其中glob.iglob()和glob.glob()之间的区别在于.iglob()返回迭代器而不是列表。
运行上面的程序会产生以下结果:
admin.pytests.pysub_dir/file1.pysub_dir/file2.py
pathlib包含用于获取灵活文件列表的类似方法。 下面的示例显示了如何使用.Path.glob()列出了文件类型是以字母 p 为开头的文件:
>>> from pathlib import Path>>> p = Path('.')>>> for name in p.glob('*.p*'):... print(name)admin.pyscraper.pydocs.pdf
调用p.glob('*.p*')将返回一个生成器对象,该对象指向当前目录中以文件扩展名中的字母 p 开头的所有文件。
Path.glob()类似于上面讨论的os.glob()。 正如我们所看到的,pathlib将os,os.path和glob模块的许多最佳功能组合到一个模块中,这使得使用起来非常愉快。
回顾一下,这是我们在本节中介绍的功能表:

遍历目录和文件
遍历目录树并处理树中的文件是最常见的编程任务之一。 让我们来探索如何使用内置的 Python 函数 os.walk() 来实现这一点。os.walk()用于通过从上到下或从下到上的遍历来生成目录树中的文件名。出于本节的目的,我们将操作以下目录树:
.|├── folder_1/| ├── file1.py| ├── file2.py| └── file3.py|├── folder_2/| ├── file4.py| ├── file5.py| └── file6.py|├── test1.txt└── test2.txt
以下是一个示例,演示如何使用os.walk()列出目录树中的所有文件和目录。
os.walk()默认以自上而下的方式遍历目录:
# Walking a directory tree and printing the names of the directories and filesfor dirpath, dirnames, files in os.walk('.'):print(f'Found directory: {dirpath}')for file_name in files:print(file_name)
os.walk()在每次的循环迭代中返回三个值:
- 当前文件夹的名称。
- 当前文件夹中的文件夹列表。
- 当前文件夹中的文件列表。
在每次迭代时,它会打印出它找到的子目录和文件的名称:
Found directory: .test1.txttest2.txtFound directory: ./folder_1file1.pyfile3.pyfile2.pyFound directory: ./folder_2file4.pyfile5.pyfile6.py
要以自下而上的方式遍历目录树,需要将topdown = False关键字参数传递给os.walk():
for dirpath, dirnames, files in os.walk('.', topdown=False):print(f'Found directory: {dirpath}')for file_name in files:print(file_name)
传递topdown = False参数将使os.walk()首先打印出它在子目录中找到的文件:
Found directory: ./folder_1file1.pyfile3.pyfile2.pyFound directory: ./folder_2file4.pyfile5.pyfile6.pyFound directory: .test1.txttest2.txt
如我们所见,程序通过在列出根目录的内容之前列出子目录的内容来启动。 这在我们想要递归删除文件和目录的情况下非常有用(我们将在下面章节部分中学习如何执行此操作)。默认情况下,os.walk不会向下走到符号链接文件所指向的目录中。 我们可以通过使用followlinks = True参数调用此行为来覆盖此行为
创建临时文件和目录
Python 提供了一个名为 tempfile 方便的模块,用于创建临时文件和目录。
tempfile 可用于在程序运行时临时在文件或目录中打开和存储数据。另一方面,tempfile 会在程序完成后对临时文件执行删除处理。
以下是创建临时文件的方法:
from tempfile import TemporaryFile# Create a temporary file and write some data to itfp = TemporaryFile('w+t')fp.write('Hello universe!')# Go back to the beginning and read data from filefp.seek(0)data = fp.read()# Close the file, after which it will be removedfp.close()
第一步是从tempfile模块导入TemporaryFile。 接下来,使用TemporaryFile()方法,并通过传递要打开文件的模式创建一个类似于 object 的文件。这将创建并打开一个可用作临时存储区域的文件。
在上面的示例中,模式为’w + t’,这使得tempfile在写入模式下创建临时文本文件。这里没有必要为临时文件提供文件名,因为在脚本运行完毕后它将被销毁。
写入文件后,我们可以从中读取并在完成处理后将其关闭。文件关闭后,将从文件系统中删除。如果需要命名使用tempfile生成的临时文件,请使用tempfile.NamedTemporaryFile()。
使用tempfile创建的临时文件和目录存储在一个特殊的用于存储临时文件的系统目录中。 Python 通过搜索标准目录列表以找到用户可以在其中创建文件的目录。
在 Windows 上,目录按顺序为C:\TEMP, C:\TMP, \TEMP, and \TMP 进行搜索。在所有其他平台上,目录按顺序为 /tmp ,/var/tmp ,以及 /usr/tmp。作为最后的手段,tempfile 将保存当前目录中的临时文件和目录。
.TemporaryFile()也是一个上下文管理器,因此它可以与 with 语句一起使用。使用上下文管理器会在读取文件后自动关闭和删除文件:
with TemporaryFile('w+t') as fp:fp.write('Hello universe!')fp.seek(0)fp.read()# File is now closed and removed
这将创建一个临时文件并从中读取数据。 一旦读取文件的内容,就会关闭临时文件并从文件系统中删除。
tempfile 也可用于创建临时目录。 让我们看一下如何使用tempfile.TemporaryDirectory()来做到这一点:
>>> import tempfile>>> with tempfile.TemporaryDirectory() as tmpdir:... print('Created temporary directory ', tmpdir)... os.path.exists(tmpdir)...Created temporary directory /tmp/tmpoxbkrm6cTrue>>> # Directory contents have been removed...>>> tmpdir'/tmp/tmpoxbkrm6c'>>> os.path.exists(tmpdir)False
调用tempfile.TemporaryDirectory()会在文件系统中创建一个临时目录,并返回一个表示该目录的对象。在上面的示例中,使用上下文管理器创建目录,目录的名称存储在tmpdir中。第三行打印出临时目录的名称,os.path.exists(tmpdir)确认目录是否实际在文件系统中创建。
在上下文管理器退出上下文后,临时目录将被删除,并且对os.path.exists(tmpdir)的调用将返回 False,这意味着该目录已成功删除。
删除文件和目录
我们可以使用os,shutil和pathlib模块中的方法删除单个文件,目录和整个目录树。以下部分介绍如何删除不再需要的文件和目录。
在 Python 中删除文件
要删除单个文件,请使用pathlib.Path.unlink(),os.remove() 或者os.unlink()。
os.remove()和os.unlink()在语义上是相同的。要使用os.remove()删除文件,请执行以下操作:
import osdata_file = 'C:\\Users\\vuyisile\\Desktop\\Test\\data.txt'os.remove(data_file)
使用os.unlink()删除文件与使用os.remove()的方式类似:
import osdata_file = 'C:\\Users\\vuyisile\\Desktop\\Test\\data.txt'os.unlink(data_file)
在文件上调用.unlink()或.remove()会从文件系统中删除该文件。如果传递给它们的路径指向目录而不是文件,这两个函数将抛出OSError。为避免这种情况,我们可以:检查确认我们实际想要删除的只是文件,并当且仅当它是文件才执行删除;或者使用异常处理来处理OSError:
import osdata_file = 'home/data.txt'# If the file exists, delete itif os.path.isfile(data_file):os.remove(data_file)else:print(f'Error: {data_file} not a valid filename')
os.path.isfile() 用于检查data_file是否实际上是一个文件。如果是,则通过调用os.remove()删除它。如果data_file指向文件夹(目录),则会向控制台输出错误消息。
以下示例说明如何在删除文件时使用异常处理来处理错误:
import osdata_file = 'home/data.txt'# Use exception handlingtry:os.remove(data_file)except OSError as e:print(f'Error: {data_file} : {e.strerror}')
上面的代码尝试在检查其类型之前先删除该文件。如果data_file实际上不是文件,则抛出的OSError将在except子句中处理,并向控制台输出错误消息。打印出的错误消息使用 Python f-strings 格式化。
最后,我们还可以使用pathlib.Path.unlink()删除文件:
from pathlib import Pathdata_file = Path('home/data.txt')try:data_file.unlink()except IsADirectoryError as e:print(f'Error: {data_file} : {e.strerror}')
上面的代码将创建一个名为data_file的 Path 对象,该对象指向文件。在data_file上调用.remove()将删除home/data.txt。 如果data_file指向目录,则引发IsADirectoryError。值得注意的是,上面的 Python 程序与运行它的用户具有相同的权限。如果用户没有删除文件的权限,则会引发PermissionError。
删除目录
Python 的标准库提供以下删除目录的功能:
os.rmdir()pathlib.Path.rmdir()shutil.rmtree()
要删除单个目录或文件夹,请使用os.rmdir()或pathlib.rmdir()。这两个函数仅在我们尝试删除的目录为空时才有效。如果目录不为空,则引发OSError。以下是删除文件夹的方法:
import ostrash_dir = 'my_documents/bad_dir'try:os.rmdir(trash_dir)except OSError as e:print(f'Error: {trash_dir} : {e.strerror}')
这里,通过将其路径作为参数传递给os.rmdir()来删除trash_dir目录。如果目录不为空,则会在屏幕上显示错误消息:
Traceback (most recent call last):File '<stdin>', line 1, in <module>OSError: [Errno 39] Directory not empty: 'my_documents/bad_dir'
或者,我们可以使用pathlib删除目录:
from pathlib import Pathtrash_dir = Path('my_documents/bad_dir')try:trash_dir.rmdir()except OSError as e:print(f'Error: {trash_dir} : {e.strerror}')
在这里,我们创建一个指向要删除的目录的 Path 对象。如果目录为空,则在 Path 对象上调用.rmdir()将它删除。
删除整个目录树
要删除非空目录和整个目录树,Python 提供了shutil.rmtree():
import shutiltrash_dir = 'my_documents/bad_dir'try:shutil.rmtree(trash_dir)except OSError as e:print(f'Error: {trash_dir} : {e.strerror}')
当对shutil.rmtree()进行调用时,trash_dir中的所有内容都将被删除。在某些情况下,我们可能希望以递归方式删除空文件夹。对此,我们可以结合上面提到的os.walk()方法来完成此操作:
import osfor dirpath, dirnames, files in os.walk('.', topdown=False):try:os.rmdir(dirpath)except OSError as ex:pass
这将遍历目录树并尝试删除它找到的每个目录。如果目录不为空,则引发OSError并跳过该目录。
下表列出了本节中涉及的功能:

文件和目录复制,移动及重命名
Python 附带的shutil模块,是 shell 实用程序的缩写。它为文件提供了许多高级操作,以支持文件和目录的复制,存档和删除。在本节中,我们将学习如何移动和复制文件和目录。
Python 中的文件复制
shutil 提供了一些复制文件的功能。其中最常用的函数是shutil.copy()和shutil.copy2()。要使用shutil.copy()将文件从一个位置复制到另一个位置,请执行以下操作:
import shutilsrc = 'path/to/file.txt'dst = 'path/to/dest_dir'shutil.copy(src, dst)
shutil.copy()与 UNIX 系统中的 cp 命令相当。shutil.copy(src, dst)会将文件 src 复制到 dst 指定的位置。如果 dst 是文件,则该文件的内容将替换为 src 的内容。如果 dst 是目录,则 src 将被复制到该目录中。shutil.copy()仅复制文件的内容和文件的权限。其他元数据(如文件的创建和修改时间)不会保留。
要在复制时保留所有文件元数据,请使用shutil.copy2():
import shutilsrc = 'path/to/file.txt'dst = 'path/to/dest_dir'shutil.copy2(src, dst)
使用.copy2()可保留有关文件的详细信息,例如上次访问时间,权限位,上次修改时间和标志。
Python 中的目录复制
虽然shutil.copy()只复制单个文件,但shutil.copytree()可以将复制整个目录及其中包含的所有内容。shutil.copytree(src, dest)有两个参数:源目录;将文件和文件夹复制到的目标目录。
以下是如何将一个文件夹的内容复制到其他位置的示例:
>>> import shutil>>> shutil.copytree('data_1', 'data1_backup')'data1_backup'
在此示例中,.copytree() 将 data_1 的内容复制到新位置 data1_backup 并返回目标目录。如果目标目录不存在,它以及其缺少的父目录将被一起创建。shutil.copytree()是备份文件的好方法。
移动文件和目录
要将文件或目录移动到其他位置,请使用shutil.move(src, dst),其中 src 是要移动的文件或目录,dst 是目标文件或者目录:
>>> import shutil>>> shutil.move('dir_1/', 'backup/')'backup'
如果backup/存在,shutil.move('dir_1/', 'backup/')将会把dir_1/移动到backup/目录;如果backup/目录不存在,则dir_1/将重命名为backup。
重命名文件和目录
Python 内置的os.rename(src, dst)可用于文件和目录的重命名:
>>> os.rename('first.zip', 'first_01.zip')
上面的代码行将first.zip重命名为first_01.zip。如果目标路径指向目录,则会引发OSError。
重命名文件或目录的另一种方法是使用pathlib模块中的rename():
>>> from pathlib import Path>>> data_file = Path('data_01.txt')>>> data_file.rename('data.txt')
要使用pathlib重命名文件,首先要创建一个pathlib.Path()对象,该对象包含要替换的文件的路径。下一步是在路径对象上调用rename()并为我们要重命名的文件或目录传递新文件名。
归档
归档是将多个文件打包成一个文件的便捷方式。两种最常见的存档类型是 ZIP 和 TAR。我们编写的 Python 程序可以从归档中创建,读取和提取数据。我们将在本节中学习如何从两种存档格式文件中读取和写入数据。
读取 ZIP 文件
zipfile模块是一个低级模块,是 Python 标准库的一部分。zipfile具有可以轻松打开和提取 ZIP 文件的功能。要读取 ZIP 文件的内容,我们首先要做的是创建一个 ZipFile 对象。ZipFile 对象类似于使用 open()创建的文件对象。ZipFile 同时也是一个上下文管理器,因此支持 with 语句:
import zipfilewith zipfile.ZipFile('data.zip', 'r') as zipobj:
在这里,您创建一个 ZipFile 对象,传入 ZIP 的文件名称并在读取模式下打开。打开 ZIP 文件后,可以通过zipfile模块提供的功能访问有关存档的信息。上面示例中的 data.zip 存档是从名为 data 的目录创建的,该目录包含总共 5 个文件和 1 个子目录:
.|├── sub_dir/| ├── bar.py| └── foo.py|├── file1.py├── file2.py└── file3.py
要获取存档中的文件列表,请在 ZipFile 对象上调用namelist():
import zipfilewith zipfile.ZipFile('data.zip', 'r') as zipobj:zipobj.namelist()
以上代码将会产生一个列表结果:
['file1.py', 'file2.py', 'file3.py', 'sub_dir/', 'sub_dir/bar.py', 'sub_dir/foo.py']
.namelist()返回归档中文件和目录的名称列表。要检索有关存档中文件的信息,请使用.getinfo():
import zipfilewith zipfile.ZipFile('data.zip', 'r') as zipobj:bar_info = zipobj.getinfo('sub_dir/bar.py')bar_info.file_size
代码结果如下:
15277
.getinfo()返回一个 ZipInfo 对象,该对象存储有关存档的单个成员的信息。要获取有关归档中文件的信息,请将其路径作为参数传递给.getinfo()。使用getinfo(),我们可以检索有关存档成员的信息,例如上次修改文件的日期,压缩大小及其完整文件名。调用.file_size将以字节为单位检索文件的原始大小。
以下示例说明如何在 Python REPL 中检索有关已归档文件的更多详细信息。假设已导入zipfile模块,bar_info 与我们在前面的示例中创建的对象相同:
>>> bar_info.date_time(2018, 10, 7, 23, 30, 10)>>> bar_info.compress_size2856>>> bar_info.filename'sub_dir/bar.py'
- bar_info 包含有关 bar.py 的详细信息,例如压缩时的大小及其完整路径。
- 第一行显示了如何检索文件的上次修改日期。下一行显示了如何在压缩后获取文件的大小。最后一行显示了存档中 bar.py 的完整路径。
ZipFile 支持上下文管理器协议,这就是我们可以将它与 with 语句一起使用的原因。完成后,执行此操作会自动关闭 ZipFile 对象。如果我们尝试从已关闭的 ZipFile 对象中打开或提取文件将导致错误。
提取 ZIP 归档
zipfile模块允许我们通过.extract()和.extractall()从 ZIP 压缩文件中提取一个或多个文件。
默认情况下,这些方法将文件解压缩到当前目录。 它们都采用可选的路径参数,允许我们指定要将文件提取到的其他目录。 如果该目录不存在,则会自动创建该目录。 要从存档中提取文件,请执行以下操作:
>>> import zipfile>>> import os>>> os.listdir('.')['data.zip']>>> data_zip = zipfile.ZipFile('data.zip', 'r')>>> # Extract a single file to current directory>>> data_zip.extract('file1.py')'/home/terra/test/dir1/zip_extract/file1.py'>>> os.listdir('.')['file1.py', 'data.zip']>>> # Extract all files into a different directory>>> data_zip.extractall(path='extract_dir/')>>> os.listdir('.')['file1.py', 'extract_dir', 'data.zip']>>> os.listdir('extract_dir')['file1.py', 'file3.py', 'file2.py', 'sub_dir']>>> data_zip.close()
第三行代码是对os.listdir()的调用,它显示当前目录只有一个文件data.zip。
接下来,在读取模式下打开data.zip并调用.extract()从中提取file1.py。 .extract()返回解压缩文件的完整文件路径。 由于没有指定路径,.extract()会将 file1.py 提取到当前目录。
下一行代码打印一个目录列表,显示当前目录除原始存档之外的解压缩文件。之后的行显示了如何将整个存档解压缩到zip_extract目录中。 .extractall() 创建 extract_dir 并将 data.zip 的内容提取到其中。最后一行关闭 ZIP 存档。
从受密码保护的归档中提取数据
zipfile支持提取受密码保护的 ZIP。要提取受密码保护的 ZIP 文件,请将密码作为参数传递给.extract()或.extractall()方法:
>>> import zipfile>>> with zipfile.ZipFile('secret.zip', 'r') as pwd_zip:... # Extract from a password protected archive... pwd_zip.extractall(path='extract_dir', pwd='Quish3@o')
这将以读取模式打开 secret.zip 存档。接下来,把密码提供给.extractall(),存档内容被提取到extract_dir。由于 with 语句,在完成提取后,存档会自动关闭。
创建新的 ZIP 存档
要创建新的 ZIP 存档,请以写入模式(w)打开 ZipFile 对象并添加要存档的文件:
>>> import zipfile>>> file_list = ['file1.py', 'sub_dir/', 'sub_dir/bar.py', 'sub_dir/foo.py']>>> with zipfile.ZipFile('new.zip', 'w') as new_zip:... for name in file_list:... new_zip.write(name)
在该示例中,我们以写入模式打开new_zip,然后把 file_list 中的每个文件都添加到归档中。完成with语句套件后,将关闭new_zip。以写入模式打开 ZIP 文件会删除存档的内容并创建新存档。
要将文件添加到现有存档,请以追加模式打开ZipFile对象,然后添加文件:
>>> # Open a ZipFile object in append mode>>> with zipfile.ZipFile('new.zip', 'a') as new_zip:... new_zip.write('data.txt')... new_zip.write('latin.txt')
在这里,我们打开在上一个示例中以追加模式创建的 new.zip 存档。在追加模式下打开ZipFile对象允许您将新文件添加到 ZIP 文件而不删除其当前内容。将文件添加到 ZIP 文件后,with 语句将脱离上下文并关闭 ZIP 文件。
打开 TAR 归档
TAR 文件是 ZIP 等未压缩文件的存档。它们可以使 用 gzip,bzip2 和 lzma 压缩方法进行压缩。TarFile 类允许读取和写入 TAR 存档。
这样做是为了从存档中读取:
import tarfilewith tarfile.open('example.tar', 'r') as tar_file:print(tar_file.getnames())
tarfile对象的打开方式跟大多数类似文件对象的打开方式一样。它们有一个open()函数,并采用一种模式来确定文件的打开方式。
使用 “r”,”w” 或 “a” 模式分别打开未压缩的 TAR 文件以进行读取,写入和追加。要打开压缩的 TAR 文件,需要将模式参数传递给tarfile.open(),其格式为filemode [:compression]。下表列出了可以打开 TAR 文件的可能模式:

.open() 默认以 ‘r’ 模式打开文件。要读取未压缩的 TAR 文件并检索其中的文件名,可以使用.getnames():
>>> import tarfile>>> tar = tarfile.open('example.tar', mode='r')>>> tar.getnames()['CONTRIBUTING.rst', 'README.md', 'app.py']
这将返回一个包含存档内容名称的列表。
可以使用特殊属性访问存档中每个条目的元数据:
>>> for entry in tar.getmembers():... print(entry.name)... print(' Modified:', time.ctime(entry.mtime))... print(' Size :', entry.size, 'bytes')... print()CONTRIBUTING.rstModified: Sat Nov 1 09:09:51 2018Size : 402 bytesREADME.mdModified: Sat Nov 3 07:29:40 2018Size : 5426 bytesapp.pyModified: Sat Nov 3 07:29:13 2018Size : 6218 bytes
在此示例中,循环遍历.getmembers()返回的文件列表,并打印出每个文件的属性。.getmembers()返回的对象具有可以通过编程方式访问的属性,例如归档中每个文件的名称,大小和上次修改时间。在读取或写入存档后,我们必须关闭它以释放系统资源。
从 TAR 存档中提取文件
在本节中,我们学习一下如何使用下面的方法从 TAR 存档中提取文件:
.extract().extractfile().extractall()
要从 TAR 存档中提取单个文件,可以使用extract(),并传入文件名:
>>> tar.extract('README.md')>>> os.listdir('.')['README.md', 'example.tar']
README.md文件从存档中提取到文件系统。然后调用os.listdir()确认README.md文件已成功提取到当前目录中。要从存档中解压缩或提取所有内容,可以使用.extractall():
>>> tar.extractall(path="extracted/")
.extractall()有一个可选的 path 参数来指定解压缩文件的去向。这里,存档被解压缩到解压缩的目录中。以下命令显示已成功提取存档:
$ lsexample.tar extracted README.md$ tree.├── example.tar├── extracted| ├── app.py| ├── CONTRIBUTING.rst| └── README.md└── README.md1 directory, 5 files$ ls extracted/app.py CONTRIBUTING.rst README.md
要提取文件对象以进行读取或写入,可以使用.extractfile(),它将文件名或TarInfo对象作为参数提取。.extractfile()返回一个可以读取和使用的类文件对象:
>>> f = tar.extractfile('app.py')>>> f.read()>>> tar.close()
打开的存档文件应在读取或写入后始终关闭。要关闭存档,需要在存档文件句柄上调用.close(),或在创建1tarfile对象时使用with语句,以便在完成后自动关闭存档。这将释放系统资源,并把我们对存档所做的任何更改写入文件系统。
创建新的 TAR 存档
创建新的 TAR 存档,可以参考下面的做法:
>>> import tarfile>>> file_list = ['app.py', 'config.py', 'CONTRIBUTORS.md', 'tests.py']>>> with tarfile.open('packages.tar', mode='w') as tar:... for file in file_list:... tar.add(file)>>> # Read the contents of the newly created archive>>> with tarfile.open('package.tar', mode='r') as t:... for member in t.getmembers():... print(member.name)app.pyconfig.pyCONTRIBUTORS.mdtests.py
首先,我们要创建要添加到存档的文件列表,这样就不必手动添加每个文件。
下一行代码使用了 with 上下文管理器在写入模式下打开名为 packages.tar 的新存档。同时以写入模式(’w’)打开存档以便我们可以将新文件写入存档。这样,我们将删除存档中的所有现有文件,并创建新存档。
创建并填充存档后,with 上下文管理器会自动关闭它并将其保存到文件系统。最后三行我们打开刚刚创建的存档,并打印出其中包含的文件的名称。
要将新文件添加到现有存档,可以以追加模式(’a’)打开存档:
>>> with tarfile.open('package.tar', mode='a') as tar:... tar.add('foo.bar')>>> with tarfile.open('package.tar', mode='r') as tar:... for member in tar.getmembers():... print(member.name)app.pyconfig.pyCONTRIBUTORS.mdtests.pyfoo.bar
在追加模式(’a’)下打开存档允许我们向其添加新文件而不删除其中已存在的文件。
处理压缩归档
tarfile还可以使用gzip,bzip2和lzma 来读取和写入 TAR 的压缩文件。要读取或写入压缩存档,请使用tarfile.open(),为压缩类型传递适当的模式。
例如,要读取或写入使用 gzip 压缩的 TAR 存档数据,请分别使用 ‘r:gz’ 或 ‘w:gz’ 模式:
>>> files = ['app.py', 'config.py', 'tests.py']>>> with tarfile.open('packages.tar.gz', mode='w:gz') as tar:... tar.add('app.py')... tar.add('config.py')... tar.add('tests.py')>>> with tarfile.open('packages.tar.gz', mode='r:gz') as t:... for member in t.getmembers():... print(member.name)app.pyconfig.pytests.py
‘w:gz’ 可以以 gzip 压缩写入的方式打开压缩的存档文件,’r:gz’ 模式则可以以 gzip 压缩读取的方式打开压缩的存档文件。需要注意的是,我们无法在追加模式下打开压缩的存档。要将文件添加到压缩存档,我们必须创建新存档。
创建归档更简单的方法
Python 标准库还支持使用shutil模块中的高级方法创建 TAR 和 ZIP 存档。shutil中的归档实用程序允许我们创建,读取和提取 ZIP 和 TAR 归档文件。这些实用程序依赖于较低级别的tarfile和zipfile模块。
使用 shutil.make_archive() 处理存档
shutil.make_archive()至少有两个参数:归档的名称和归档格式。
默认情况下,它将当前目录中的所有文件压缩为format参数中指定的归档格式。我们也可以传入可选的root_dir参数来压缩不同目录中的文件。.make_archive()支持 zip,tar,bztar 和 gztar 存档格式。
这是使用shutil创建 TAR 存档的方法:
import shutil# shutil.make_archive(base_name, format, root_dir)shutil.make_archive('data/backup', 'tar', 'data/')
上面程序将复制 data/ 中的所有内容,并在文件系统中创建名为 backup.tar 的存档并返回其名称。要提取存档,我们可以调用 .unpack_archive():
shutil.unpack_archive('backup.tar', 'extract_dir/')
这行代码调用了.unpack_archive()并传入存档名称和目标目录,它会将 backup.tar 的内容提取到 extract_dir/ 中。 ZIP 存档也可以以相同的方式创建和提取。
读取多个文件
Python 支持通过 fileinput 模块从多个输入流或文件列表中读取数据。此模块允许我们快速轻松地循环遍历一个或多个文本文件的内容。以下是使用 fileinput 的典型方法:
import fileinputfor line in fileinput.input()process(line)
fileinput 默认从传递给 sys.argv 的命令行参数中获取其输入。
使用 fileinput 循环遍历多个文件
让我们使用 fileinput 构建一个普通的 UNIX 实用程序 cat 的原始版本。cat 实用程序将按顺序读取文件,将它们写入标准输出。当在命令行参数中给出多个文件时,cat 将连接文本文件并在终端中显示结果:
# File: fileinput-example.pyimport fileinputimport sysfiles = fileinput.input()for line in files:if fileinput.isfirstline():print(f'\n--- Reading {fileinput.filename()} ---')print(' -> ' + line, end='')print()
在当前目录中的两个文本文件上运行此命令会产生以下输出:
$ python3 fileinput-example.py bacon.txt cupcake.txt--- Reading bacon.txt ----> Spicy jalapeno bacon ipsum dolor amet in in aute est qui enim aliquip,-> irure cillum drumstick elit.-> Doner jowl shank ea exercitation landjaeger incididunt ut porchetta.-> Tenderloin bacon aliquip cupidatat chicken chuck quis anim et swine.-> Tri-tip doner kevin cillum ham veniam cow hamburger.-> Turkey pork loin cupidatat filet mignon capicola brisket cupim ad in.-> Ball tip dolor do magna laboris nisi pancetta nostrud doner.--- Reading cupcake.txt ----> Cupcake ipsum dolor sit amet candy I love cheesecake fruitcake.-> Topping muffin cotton candy.-> Gummies macaroon jujubes jelly beans marzipan.
fileinput 允许我们检索有关每一行的更多信息,例如它是否是第一行(.isfirstline()),行号(.lineno()) 和文件名(.filename())。 更多关于 fileinput 的内容,我们可以点击这里查看。
总结
现在我们已经知道如何使用 Python 对文件和文件组执行最常见的操作。同时也已经了解了用于读取,查找和操作它们的不同内置模块。
现在我们可以使用 Python 来:
- 获取目录内容和文件属性
- 创建目录和目录树
- 在文件名中查找模式
- 创建临时文件和目录
- 移动,重命名,复制和删除文件或目录
- 从不同类型的档案中读取和提取数据
- 使用
fileinput同时读取多个文件

若有收获,就点个赞吧
0 人点赞
