一、引言
Jupyter(以前叫 iPython)已经被数据科学家,研究人员和分析师广泛采用。Jupyter 的笔记本用户界面可以将可执行代码与叙述性文本,方程式,交互式可视化和图像混合在一起,以加强团队合作,并推动可重复的研究和培训向前发展。Jupyter 开始于 Python 语言,现在拥有50种不同语言的内核,而 IRKernel 是用于 Jupyter 的本地 R 内核。
数据科学家、研究人员和分析师使用 conda 软件包管理器来安装和组织项目依赖。通过 conda,他们可以轻松地构建和共享元数据包,这些元数据包是可下载的软件包。conda 可以在 Linux, OS X, 和 Windows 下工作,并且是与语言无关的,因此我们可以将它用于任何编程语言以及依赖于多种语言的项目。
接下来,让我们使用 conda 和 Jupyter 在 R 中开始一个数据科学项目。
二、安装
1. 创建”R Essentials”
Anaconda 团队已经创建了一个 “R Essentials“ 把 IRKernel 和数据科学分析中最常用的超过 80 个 R 包捆绑在了一起,这些包包括:dplyr、shiny、ggplot2、tidyr、caret 和 nnet。
“R Essentials” 下载需要通过 conda 命令。Miniconda 已经包含了 conda、Python 以及其他的一些必须包,而 Anaconda 则包含了 miniconda 的所有东西,以及用于科学,数学,工程和数据分析的 200 多个最受欢迎的 Python 软件包。用户可以选择安装 Anaconda 一次安装所有的包;也可以先安装 Miniconda ,然后再使用 conda 命令安装他们需要的包,包括在 Anaconda 中的任何包。
如果你已经拥有了 conda,你可以为当前环境安装 “R Essentials”:
conda install -c r r-essentials
或者创建一个专门用于 “R essentials” 的新环境:
conda create -n my-r-env -c r r-essentials
2. 常见问题与解决
① conda 安装完 r-essentials,命令行下启动 R 出错:
$ R......*** caught segfault ***address 0x20, cause 'memory not mapped'Traceback:1: dyn.load(libPath)......Possible actions:1: abort (with core dump, if enabled)2: normal R exit3: exit R without saving workspace4: exit R saving workspaceSelection:Selection:Warning message:In doTryCatch(return(expr), name, parentenv, handler) :unable to load shared object '/usr/local/software/anaconda3/lib/R/modules//R_X11.so':libXdmcp.so.6: cannot open shared object file: No such file or directory> quit()
解决方法:
conda install -c clinicalgraphics libxdmcp
三、在 Jupyter Notebook 中使用 R
Jupyter 提供了一个强大的笔记本交互界面来写你的分析,并与同行分享。打开一个 shell 并运行下面这个命令来启动浏览器中的 Jupyter 笔记本界面:
jupyter notebook
创建一个新的 R 笔记:
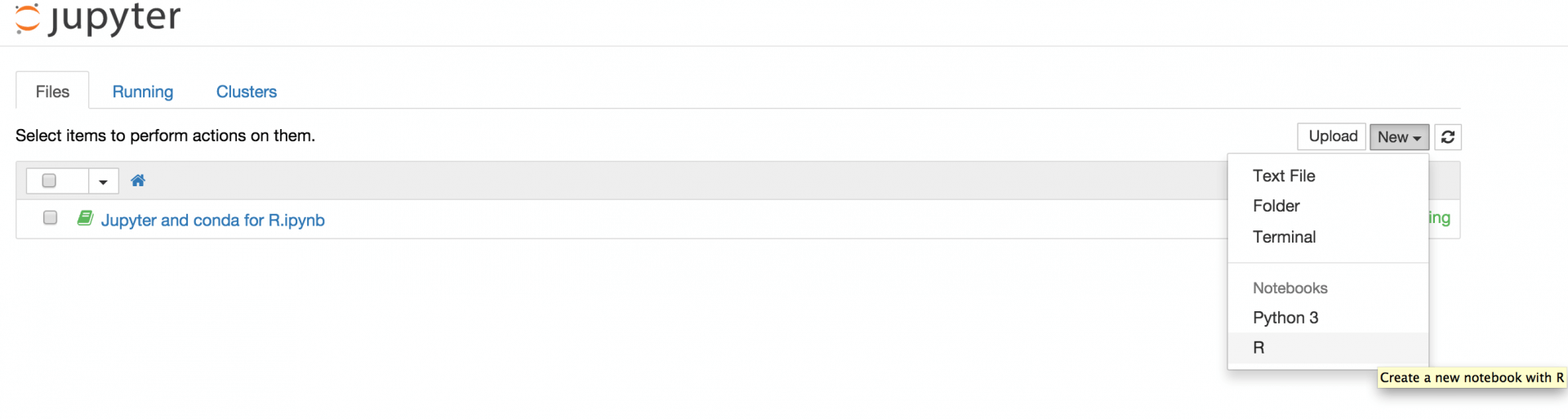
接下来,你就可以在 notebook cells 中编写和运行你的 R 代码了。
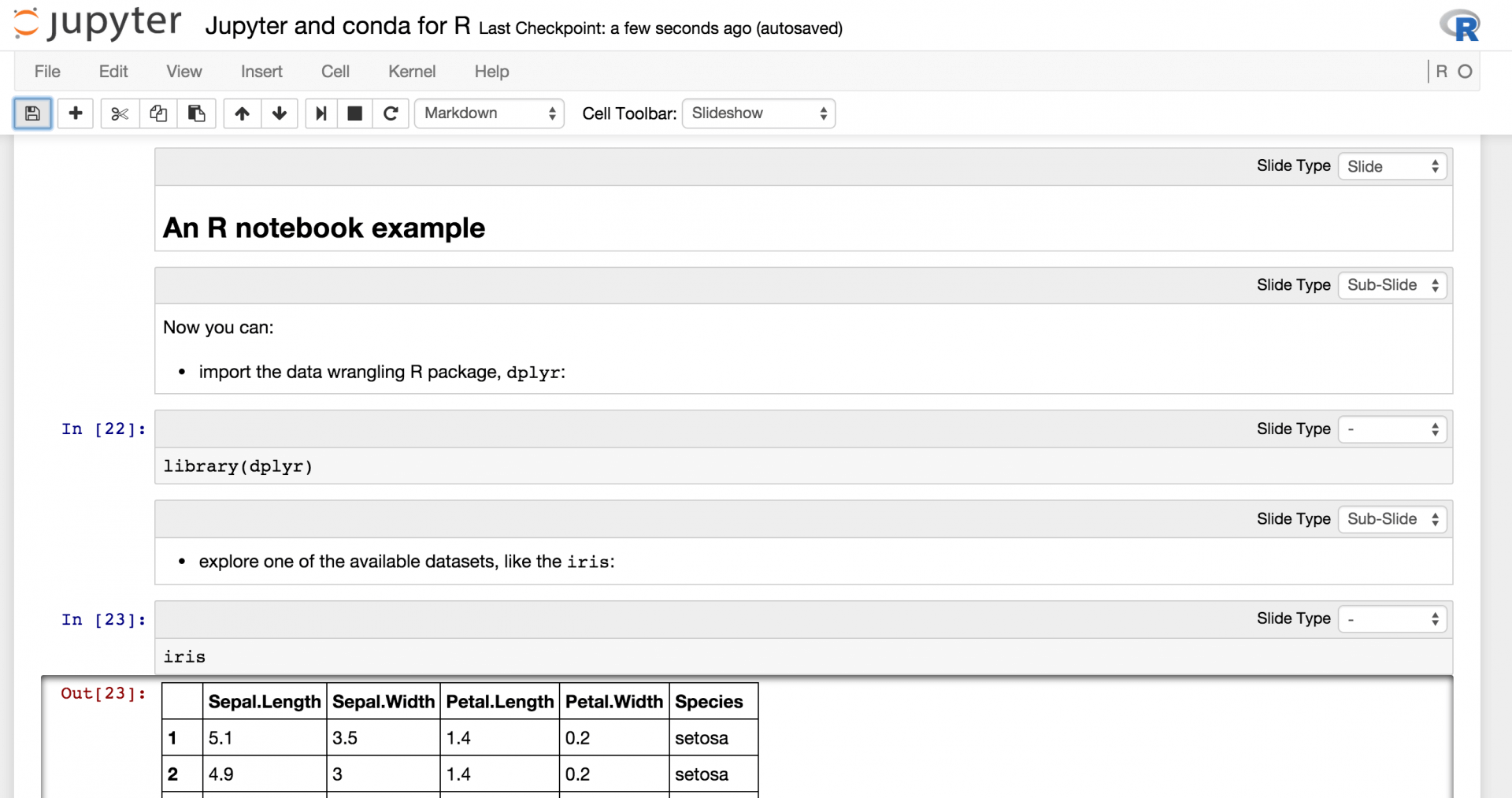
1. Jupyter Notebook R 笔记示例
- 导入数据整理 R 包,dplyr:
In [1]: library(dplyr)
- 调用一个可用的数据集,如
iris:
In [2]: irisOut[2]:Sepal.Length Sepal.Width Petal.Length Petal.Width Species1 5.1 3.5 1.4 0.2 setosa2 4.9 3 1.4 0.2 setosa...
- 计算物种的平均萼片宽度:
In [3]: iris %>%group_by(Species) %>%summarise(Sepal.Width.Avg = mean(Sepal.Width)) %>%arrange(Sepal.Width.Avg)Out [3]:Species Sepal.Width.Avg1 versicolor 2.772 virginica 2.9743 setosa 3.428
- 导入可视化 R 包 ggplot2:
In [4]: library(ggplot2)
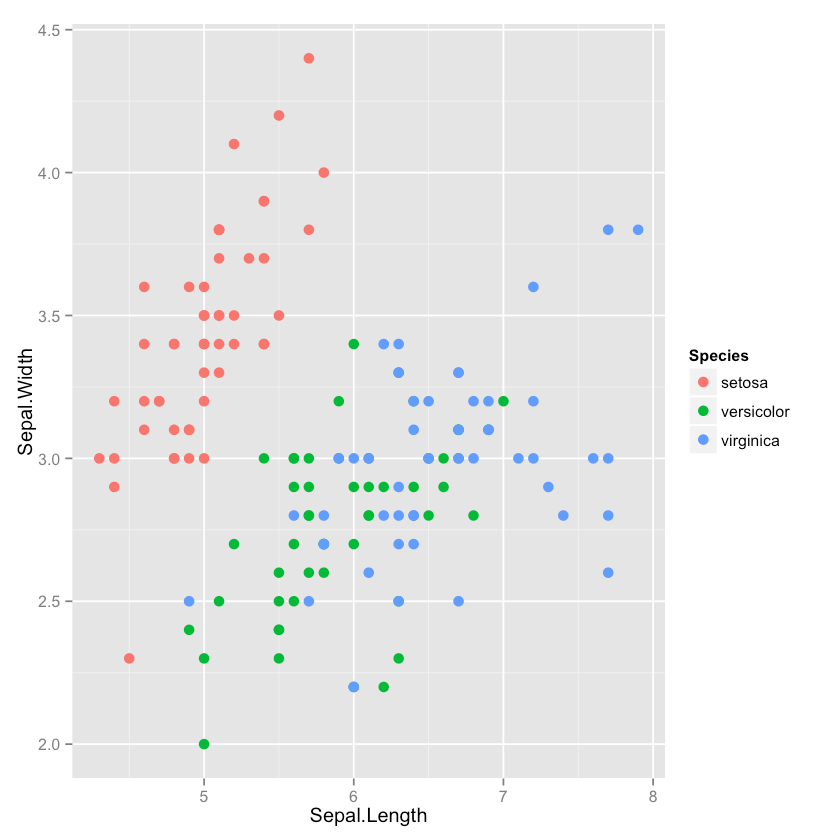
- 绘图 Sepal.Width vs. Sepal.Length:
In [5]: ggplot(data=iris, aes(x=Sepal.Length, y=Sepal.Width, color=Species)) + geom_point(size=3)
2. 转换笔记为幻灯片
Jupyter 可以把笔记转换为在线幻灯片,供讲座和教程使用。
要将笔记本转换为 reveal.js 演示文稿,请将 “单元格工具栏(Cell Toolbar)” 设置为“幻灯片放映(Slideshow”)”: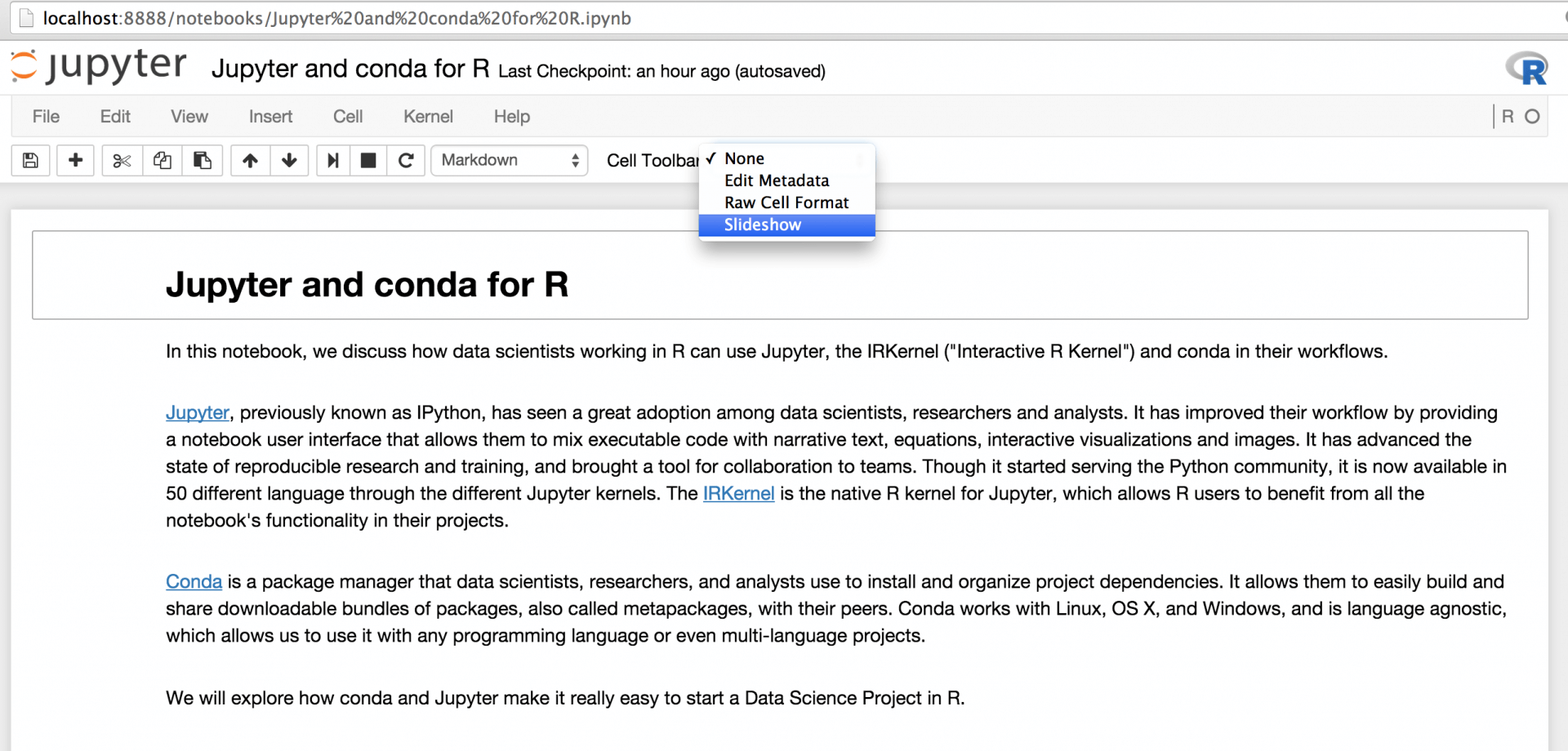
将单元格(cells)组织成幻灯片(slides)和副幻灯片(subslides):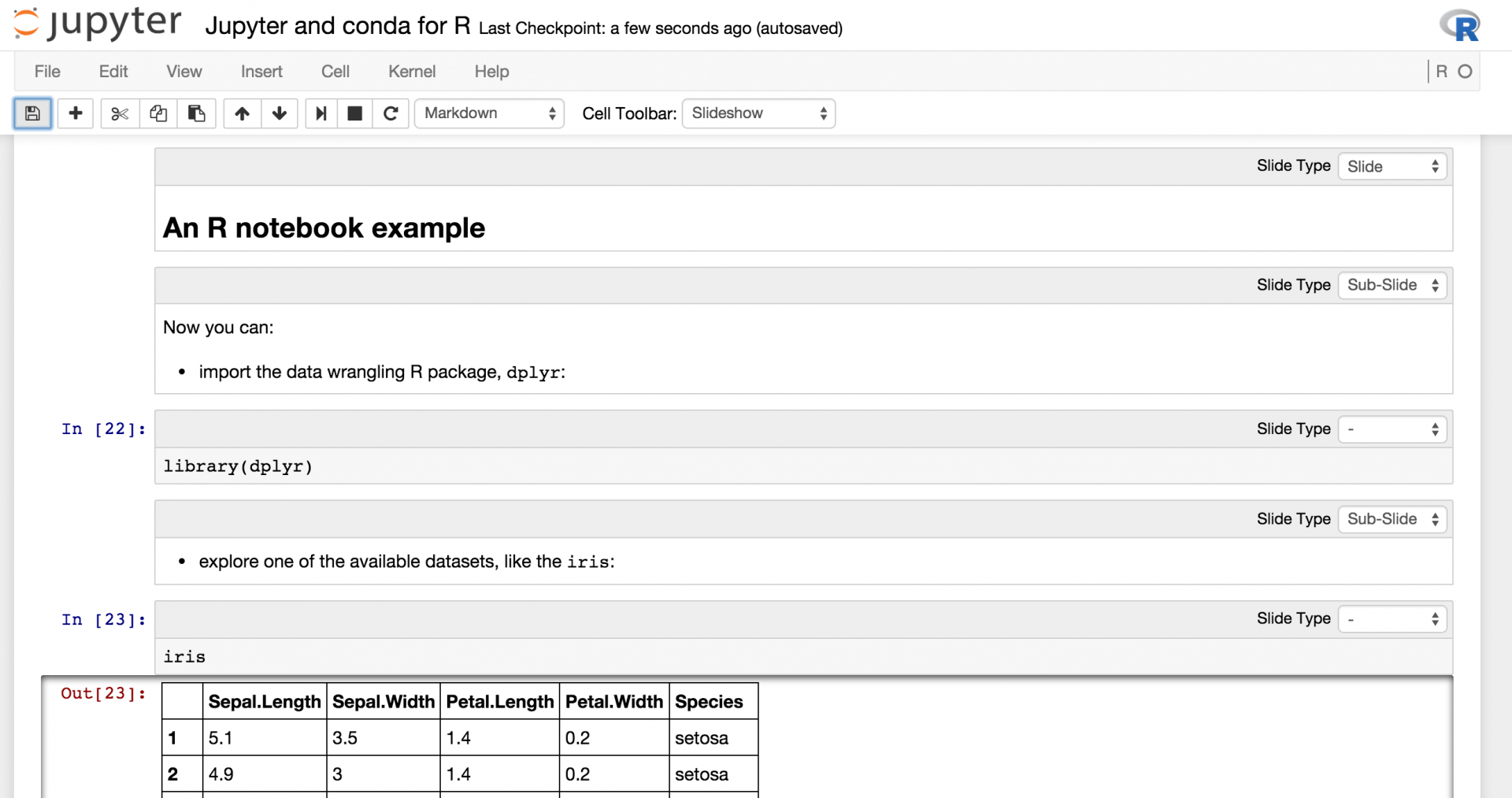
执行转化命令:
jupyter nbconvert my_r_notebook.ipynb --to slides --post serve
最后,打开浏览器展示幻灯片:
3. 常见问题与解决
① jupyter notebook 中 R 画图,不显示文字、标签。
解决方法:
# This is because the fonts are missing in anaconda, what we need is to install it:conda install -c anaconda fonts-anaconda
参考:https://github.com/ContinuumIO/anaconda-issues/issues/7455
四、创建自定义 R 包
出于用户使用方便考虑,Anaconda 已经在 “R Essentials” 中打包了一些最常用的数据科学 R 包。使用 conda metapackage 命令创建您自己的 R 软件包以便与同行共享也非常容易。例如,提供一个只包含在我们的示例笔记本中使用的库,名字为 custom-r-bundle 的下载程序,只需创建 metapackage 即可:
conda metapackage custom-r-bundle 0.1.0 --dependencies r-irkernel jupyter r-ggplot2 r-dplyr --summary "My custom R bundle"
把我们自定义的 R 包上传到 Anaconda.org 与同事分享:
conda install anaconda-clientanaconda loginanaconda upload path/to/custom-r-bundle-0.1.0-0.tar.bz2
现在,任何人都可以通过运行下面的命令来获取所有这些包和依赖关系:
conda install -c <your anaconda.org username> custom-r-bundle
五、总结
本博客文章探讨 Jupyter 如何为 R 用户提供一个漂亮的笔记本界面来进行开发,叙述和分享 R 中的数据科学项目。同样的,对于开始,打包和跟踪必要的依赖关系以便用 conda 和 “R essentials” 复制分析和结果,也是非常简单的。
六、参考资料

若有收获,就点个赞吧
0 人点赞
