- 1. Conda 安装配置生物信息软件
- _anaconda_depends pkgs/main/linux-64::_anaconda_depends-2020.07-py37_0
- _r-mutex conda-forge/noarch::_r-mutex-1.0.1-anacondar_1
- binutils_impl_lin~ pkgs/main/linux-64::binutils_impl_linux-64-2.33.1-he6710b0_7
- binutils_linux-64 conda-forge/linux-64::binutils_linux-64-2.33.1-h9595d00_17
- brotlipy conda-forge/linux-64::brotlipy-0.7.0-py37h516909a_1000
- bwidget conda-forge/linux-64::bwidget-1.9.14-0
- gcc_impl_linux-64 pkgs/main/linux-64::gcc_impl_linux-64-7.3.0-habb00fd_1
- gcc_linux-64 conda-forge/linux-64::gcc_linux-64-7.3.0-h553295d_17
- 获取所有包的名字
- 手动安装
- 2. Conda 常见异常与解决
- 3. Conda 加速器之 Mamba 操作
- 参考资料
本文以生信宝典的《一文掌握 Conda 软件安装:虚拟环境、软件通道、加速solving、跨服务器迁移 》为基础,对部分内容进行了扩展和部分调整,希望能形成一个更加系统化完善化的 Conda 生信软件安装配置指南!
更新历史:
- 2021.10.25 - 增加第三章 Conda 加速器之 Mamba 操作 - by shenweiyan
- 2021.04.20 - 增加第二章 conda 常见异常与解决 - by shenweiyan
1. Conda 安装配置生物信息软件
Conda 是一种通用包管理系统,旨在构建和管理任何语言的任何类型的软件。通常与 Anaconda 和 Miniconda 一起发放。
- Anaconda:https://www.anaconda.com/products/individual),集成了更多软件包。
- Miniconda:https://conda.io/miniconda.html),只包含基本功能软件包。
最初接触到 Anaconda 是用于 Python 包的安装。Anaconda 囊括了 100 多个常用的 Python 包,一键式安装,解决 Python 包安装的痛苦。
但后来发现,其还有更多的功能,尤其是其增加了 bionconda (https://bioconda.github.io/index.html)通道后,生物信息分析的 7925 多个软件都可以一键安装了(具体列表在:https://anaconda.org/bioconda/repo),免去了编译时间浪费和解决库文件安装的问题。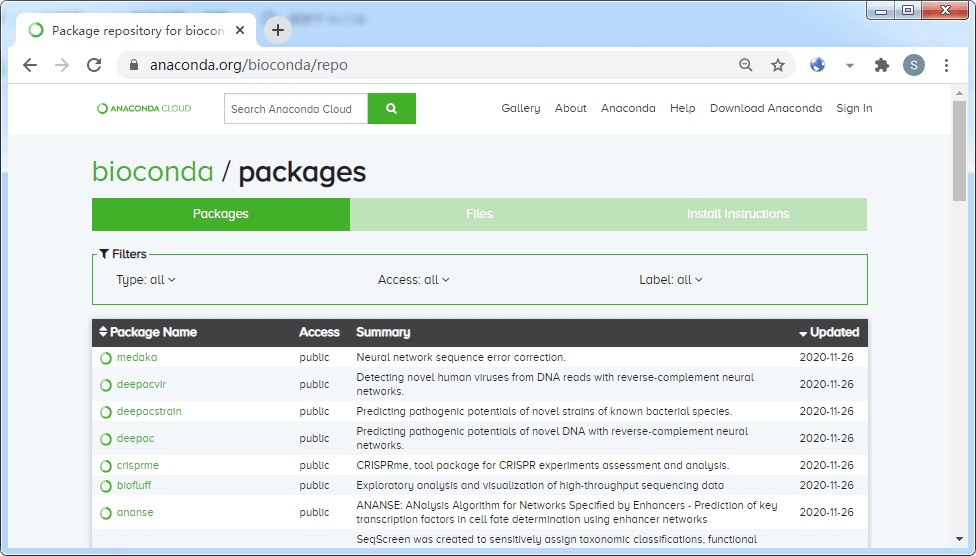
另外其最有吸引力的是它的虚拟软件环境概念,可以简单的配置不同 Python 版本的环境、不同 Python 包的环境、不同 R 环境和 R 包的环境,对于生物信息软件繁杂的应用和频繁的更新提供了很大的便利。
1.1 Conda 安装和配置
在链接 https://www.anaconda.com/products/individual 下载 Anaconda 或 Miniconda 对应版本的分发包之后,安装就是运行下面的命令,根据提示一步步操作,主要是修改安装路径:
- 如果是根用户,可以安装到
/anaconda下,或者其它任意目录都可以,但路径短还是有好处的; - 普通用户可安装到自己有权限的目录下,如
~/miniconda2。
安装完成之后,记得把安装路径下的# soft目录为conda安装的目录,可自己修改soft=~/miniconda2echo 'export PATH="'${soft}'/bin:$PATH"' >>~/.bash_profileexport PATH="${soft}/bin:$PATH"wget -c https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.shbash Miniconda2-latest-Linux-x86_64.sh -b -f -p ${soft}
bin文件夹加入到环境变量中(上面命令中我们已经帮您加进去了)。
1.2 Conda 基本使用
在 conda 安装配置好之后,就可以使用了。
conda list # 列出安装的软件包# conda所有软件名都是小写conda search <package ambigious name> # 搜索需要安装的软件包,获取其完成名字
以搜索 numpy 为例:
$ conda search numpy # * 表示对于版本的包已安装Loading channels: done# Name Version Build Channelnumpy 1.5.1 py26_1 freenumpy 1.5.1 py26_3 freenumpy 1.5.1 py26_4 freenumpy 1.5.1 py26_6 freenumpy 1.5.1 py26_ce0 freenumpy 1.5.1 py27_1 freenumpy 1.5.1 py27_3 freenumpy 1.5.1 py27_4 freenumpy 1.5.1 py27_6 freenumpy 1.5.1 py27_ce0 free# 安装包, -y 是同意安装,不写的话会弹出提示,需要再次确认conda install <package name> # 安装软件包conda install numpy=1.7.2 -y # 安装特定版本的软件包conda remove <package name> # 移除软件包
安装 R:
# 具体见下面# 安装 R,及 80 多个常用的数据分析包, 包括 idplyr, shiny, ggplot2, tidyr, caret 和 nnetconda install -c r r-base=4.0.2 r-essentials# 安装单个包# conda install -c https://conda.binstar.org/bokeh ggplot
更新包:
# 更新基础 conda,新版本 conda 使用起来更快conda update -n base -c defaults condaconda update r-base
获取帮助信息:
conda -h # 查看 conda 可用的命令conda install -h # 查看 install 子命令的帮助
只是这些命令就可以省去不少安装的麻烦了,但是如果软件没搜索到呢?
1.3 Conda 的 channel
Conda 默认的源访问速度有些慢,可以增加国内的源;另外还可以增加几个源,以便于安装更多的软件,尤其是:
- bioconda 安装生信类工具;
- conda-forge 通道是 Conda 社区维护的包含很多不在默认通道里面的通用型软件;
- r 通道是向后兼容性通道,尤其是使用 R-3.3.1 版本时会用到,现在则不需要单独添加了。
后加的通道优先级更高,因此一般用下面列出的顺序添加。清华镜像具体见 《Anaconda 镜像使用帮助》,有时清华镜像也不稳定,不稳定时直接用官方镜像,早上下载速度还是好的。
conda config --add channels rconda config --add channels defaultsconda config --add channels conda-forgeconda config --add channels biocondaconda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/# Anocanda 清华镜像conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/cond-forge# 清华通道, 最高优先级conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/conda config --set show_channel_urls yes
注意通道的顺序是会影响 **solving environment** 和软件包下载的速度的。
# 显示已有的通道conda config --get channels
conda 通道的配置文件一般在 ~/.condarc 里面,内容如下。全局控制 conda 的安装在conda_path/.condarc,具体操作见:
- https://conda.io/docs/user-guide/configuration/admin-multi-user-install.html
channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/cond-forge- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # Anocanda清华镜像- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/- bioconda- conda-forge- r
1.4 创建不同的软件运行环境
这是 conda 最有特色的地方,可以通过创建不同的环境,同时运行不同软件的多个版本。
新创建的软件环境的目录为 anaconda_path/envs/enrironment_name,具体见下面的 3 个例子。
1.4.1 创建一个环境 transcriptome 安装常用转录组分析软件
# 新建一个环境,命名为 transcriptome# 环境名字为 transcriptome# 环境中安装 samtools multiqc rseqcconda create -n transcriptome samtools multiqc rseqc# 如果还想继续安装conda install -n transcriptome fastqc salmon star stringtie sra-tools trimmomatic rmats rmats2sashimiplot# 启动新环境source activate transcriptomesalmon -h# 默认安装到了 anaconda_path 下面的 envs/transcriptome 目录下(在屏幕输出也会有显示)# 这个目录下存在bin文件夹,一般使用全路径就可以调用,如下# anaconda_path/envs/transcriptome/bin/salmon -h # 但有时会因为依赖关系而失败source deactivate transcriptome
不少软件不激活环境也可以使用全路径调用,比如 anaconda_path/envs/transcriptome/bin/salmon 就可以直接使用 salmon 程序,这样我们就可以根据前面的 PATH 介绍,我们把目录 anaconda_path/envs/transcriptome/bin/ 放入环境变量,就可以直接调用这个环境中的大部分程序了。
新版的 conda 默认会使用 conda activate transcriptome 来激活环境。
初次使用时会弹出一个提示,需要运行 conda init :
conda activate qiime2-2020.6CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'.To initialize your shell, run$ conda init <SHELL_NAME>Currently supported shells are:- bash- fish- tcsh- xonsh- zsh- powershellSee 'conda init --help' for more information and options.IMPORTANT: You may need to close and restart your shell after running 'conda init'.
不过,个人更喜欢用source anaconda_path/bin/activate transcriptome 激活环境,用起来更灵活一些。而且如果是根用户安装时,不建议把 **conda** 环境默认加到环境变量中,会引起不必要的系统冲突。可以给个用户自己使用是自己配置对应的环境变量。
激活环境后,会看到命令行提示前多了一个环境名字,比如下面激活 qiime2-2020.6 环境后的展示。
ct@ehbio:~# source /anaconda3/bin/activate qiime2-2020.6(qiime2-2020.6) ct@ehbio:~# which python/anaconda3/envs/qiime2-2020.6/bin/python(qiime2-2020.6) ct@ehbio:~# source /anaconda3/bin/deactivateDeprecationWarning: 'source deactivate' is deprecated. Use 'conda deactivate'.ct@ehbio:~# which python/usr/bin/python
1.4.2 在环境 phylo 中安装 ete3
起因是使用官方的推荐命令安装时出了问题,py3.5 的包装到了 py2.7 环境下。解决办法,新建一个 py2.7 的环境,然后安装。
# 新建一个环境,命名为phylo,指定其内安装的python版本为2.7conda create -n phylo python=2.7# 在phylo环境中安装 ete3# ete3存在于2个通道中,官方推荐使用自己的通道,但没有成功# -n 指定安装环境 -c 指定下载通道# conda install -n phylo -c etetoolkit ete3 ete3_external_apps# bioconda通道里面也有ete3, 下面的安装未指定具体通道,# 将在前面设定的几个通道里面按先后顺序查找安装conda install -n phylo ete3 ete3_external_apps# 默认安装到了anaconda_path下面的envs/phylo目录下(在屏幕输出也会有显示)# 这个目录下存在bin文件夹,一般使用全路径就可以调用,如下# anaconda_path/envs/phylo/bin/ete3 -h # 但有时会因为依赖关系而失败# 所以激活本次安装环境是比较不容易出问题的使用方式source activate phylo# 在新环境里面执行命令操作ete3 -h# 其它操作# 退出新环境source deactivate phylo
1.4.3 创建 R 环境 Reference1
# Create a new conda environment called r,并且在里面安装anacondaconda create -n r anaconda# Switch to r environmentsource activate r# 在新环境里面安装R Installs Rconda install -c r r# Install R kernel for IPython notebookconda install -c r r-irkernel# Install ggplotconda install -c https://conda.binstar.org/bokeh ggplot# 最后退出新环境source deactivate r
列出所有的环境:
$ conda env list# conda environments:#base * /anaconda2lefse /anaconda2/envs/lefsemetagenome_env /anaconda2/envs/metagenome_envmetawrap /anaconda2/envs/metawrapprokka_env /anaconda2/envs/prokka_envpy3 /anaconda2/envs/py3r-environment /anaconda2/envs/r-environmentreseq /anaconda2/envs/reseqsourmash_env /anaconda2/envs/sourmash_envqiime2-2020.6 /anaconda3/envs/qiime2-2020.6
1.5 移除某个 Conda 环境
如果环境不需要了,或出了错,则可以移除。比如需要移除 phylo 环境,执行 conda remove -n phylo --all。
1.6 Conda 配置 R
在添加了不同的源之后,有些源更新快,有些更新慢,经常会碰到版本不一的问题。而且软件版本的优先级,低于源的优先级。保险期间,先做下搜索,获得合适的版本号,然后再选择安装。
conda search r-essentialsLoading channels: done# Name Version Build Channelr-essentials 1.0 r3.2.1_0 rr-essentials 1.0 r3.2.1_0a rr-essentials 1.1 r3.2.1_0 rr-essentials 1.1 r3.2.2_0 rr-essentials 1.1 r3.2.1_0a rr-essentials 1.1 r3.2.2_0a rr-essentials 1.1 r3.2.2_1 rr-essentials 1.1 r3.2.2_1a rr-essentials 1.4 0 rr-essentials 1.4.1 r3.3.1_0 rr-essentials 1.4.2 0 rr-essentials 1.4.2 r3.3.1_0 rr-essentials 1.4.3 r3.3.1_0 rr-essentials 1.5.0 0 rr-essentials 1.5.1 0 rr-essentials 1.5.2 r3.3.2_0 rr-essentials 1.5.2 r3.4.1_0 rr-essentials 1.6.0 r3.4.1_0 rr-essentials 1.0 r3.2.1_0 defaultsr-essentials 1.0 r3.2.1_0a defaultsr-essentials 1.1 r3.2.1_0 defaultsr-essentials 1.1 r3.2.2_0 defaultsr-essentials 1.1 r3.2.1_0a defaultsr-essentials 1.1 r3.2.2_0a defaultsr-essentials 1.1 r3.2.2_1 defaultsr-essentials 1.1 r3.2.2_1a defaultsr-essentials 1.4 0 defaultsr-essentials 1.4.1 r3.3.1_0 defaultsr-essentials 1.4.2 0 defaultsr-essentials 1.4.2 r3.3.1_0 defaultsr-essentials 1.4.3 r3.3.1_0 defaultsr-essentials 1.5.0 0 defaultsr-essentials 1.5.1 0 defaultsr-essentials 1.5.2 r3.3.2_0 defaultsr-essentials 1.5.2 r3.4.1_0 defaultsr-essentials 1.6.0 r3.4.1_0 defaultsr-essentials 1.5.2 r3.3.2_0 conda-forger-essentials 1.5.2 r3.3.2_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
从上面可以看到清华的源版本同步于conda-forge, 都比较老,还是指定 r 通道安装。
conda install -c r -n r r-essentials=1.6.0
R 会安装于 conda_path/envs/r/bin 中,软链到位于环境变量的目录中即可正常使用。这就是环境变量的活学活用。
1.7 Conda 环境简化运行
为了方便不同环境里面程序的运行,我写了一个 shell 脚本 (conda_env_run.sh),具体运行如下:
# -c: 表示实际需要运行的命令# -e: 表示需要启动的软件环境,也就是上面conda create建立的环境# -b:一般不需要指定,如果conda没在环境变量中需要给出conda的安装路径conda_env_run.sh -c 'ete3 -h mod' -e phyloconda_env_run.sh -c 'bwa mem -h' -e aligner -b "/usr/local/anaconda2/bin"
conda_env_run.sh 内容如下:
#!/bin/bash#set -xusage(){cat <<EOF${txtcyn}***CREATED BY Chen Tong (chentong_biology@163.com)***Usage:$0 options${txtrst}${bldblu}Function${txtrst}:This is designed to run conda program in given environment.It will automatically activate the environment, run the program anddeactivate the environment.Thress commands from conda, 'activate', 'conda', 'deactivate' mustbe in PATH or you should spcify <-b> parameter.${txtbld}OPTIONS${txtrst}:-c Full command to be run ${bldred}[NECESSARY]${txtrst}-e Environment name${bldred}[NECESSARY]${txtrst}-b Conda path${bldred}[NECESSARY]${txtrst}EOF}command_cmd=''environment=''conda_path=''while getopts "hc:e:b:" OPTIONdocase $OPTION inh)echo "Help mesage"usageexit 1;;c)command_cmd=$OPTARG;;e)environment=$OPTARG;;b)conda_path=$OPTARG;;?)usageecho "Unknown parameters"exit 1;;esacdoneif [ -z ${environment} ]; thenecho 1>&2 "Please give command and environment."usageexit 1fiif ! [ -z ${conda_path} ]; thenexport PATH=${conda_path}:${PATH}fisource activate ${environment}${command_cmd}source deactivate ${environment}
1.8 Conda 环境备份
有的时候会出现装一个新包,装着装着就把当前环境搞装崩了的情况,所以备份一个环境还是必要的,conda create -n python35copy --clone python35,把 python35 备份为 python35copy。
1.9 Conda 环境导出和导入
做培训时需要给参加培训的老师提供配置环境的脚本,之前都是提供一个 Bash 文件全部运行下来就可以完成整个环境的配置,更简单的方式是可以导出环境,自己配置时再导入就好了。
# 假设我们有一个环境叫 ehbio,可以导出为一个yml文件conda env export --file ehbio_env.yml --name ehbio# 然后换一台电脑,就可以完全重现这个环境了# 这么做的另一个优势是yml中明确列出了软件的版本,# 使用 conda solving environment时速度会快很多conda env create -f ehbio_env.yml
1.10 core dump error/Segment fault/段错误
如果 conda 在软件安装中出现 “core dump error/Segment fault/段错误” 怎么办?
# 清空缓存# https://github.com/conda/conda/issues/7815conda clean -a
1.11 Conda 为什么越来越慢?
Conda 中包含的软件越来越多,而且软件的不同版本都保留了下来,软件的索引文件越来越大,安装一个新软件时搜索满足环境中所有软件依赖的软件的搜索空间也会越来越大,导致 solving environment 越来越慢。
1.12 Conda 是如何工作的
从设定的通道(channel)处下载通道中所有软件的索引信息 (
repodata.json) (Collecting package metadata (repodata.json))。"packages" : {"moto-1.3.7-py_0.tar.bz2" : {"build" : "py_0","build_number" : 0,"depends" : [ "aws-xray-sdk !=0.96,>=0.93", "backports.tempfile", "boto >=2.36.0", "boto3 >=1.6.15", "botocore >=1.12.13", "cookies", "dicttoxml", "docker-py", "flask", "jinja2 >=2.7.3", "jsondiff 1.1.1.*", "mock", "pyaml", "python", "python-dateutil", "python-jose <3.0.0", "pytz", "requests >=2.5", "responses >=0.9.0", "six", "werkzeug", "xmltodict" ],"license" : "Apache-2.0","md5" : "17b424658cd07e678b5feebdc932eb52","name" : "moto","sha256" : "5924666f8c1758472dc4c3d22b270b46cd1c4b66c50a9ba50d5c636d2237bdd1","size" : 399973,"subdir" : "noarch","timestamp" : 1552438392680,"version" : "1.3.7"}}~~
解析
repodata中的信息获取所有依赖的包的信息。- 采用
SAT-solver算法决定需要下载包的哪个版本和它们的安装顺序。 - 下载并安装包。
1.13 Conda 哪一步慢?
主要是第 3 步,确定待安装包的依赖包之间的兼容和已安装软件之间的兼容,获得需要下载的包和对应版本。
1.14 如何提速 Conda
采用最新版的
conda(Conda 4.7 相比 Conda 4.6 提速 3.5 倍,Conda 4.8 应该不会比 4.7 慢)。安装时指定版本减少搜索空间
conda install python=3.7.4。安装 R 包时指定 R 的版本也会极大减小搜索空间(R 包因其数目众多,也是生物类软件依赖解析较慢的原因之一),如
conda install r-base=4.0.2 r-ggplot2=3.3.2。采用
mamba加速软件依赖解析 [mamba采用c++重写了部分解析过程,这个提速效果是很明显的](安装好mamba后就可以用mamba替换conda进行安装了)。conda install mamba -c conda-forgemamba install python=3.7.4
默认 conda 解析软件依赖时优先考虑允许的最高版本,设置通道优先级权限高于软件版本新旧后,conda 会能更快的解决依赖关系,避免
defaults和conda-forge通道的奇怪组合导致软件依赖解析迟迟不能将结束的问题:conda config --set channel_priority strict(这个命令只需要运行一次)。创建一个新环境(
conda env create -n env_name)再安装软件,这样就不用考虑与已有的软件的兼容问题了,也可以大大降低搜索空间和提高解析软件依赖的速度。如果安装的软件提供了
environment.yaml那么用起来,文件中对应的软件版本都很明确,解析依赖关系时更快。也可以按前面提供的方式导出一个已经配置好的环境的yaml文件,在其它电脑配置时直接读取。(具体导出方式见《Bioconda 软件安装神器:多版本并存、环境复制、环境导出》。channels:- qiime2/label/r2020.6- conda-forge- bioconda- defaultsdependencies:- _libgcc_mutex=0.1- _openmp_mutex=4.5- _r-mutex=1.0.1- alsa-lib=1.1.5- arb-bio-tools=6.0.6- attrs=19.3.0- backcall=0.2.0- bibtexparser=1.1.0- binutils_impl_linux-64=2.34- binutils_linux-64=2.34- bioconductor-biobase=2.42.0- bioconductor-biocgenerics=0.28.0- bioconductor-biocparallel=1.16.6- bioconductor-biostrings=2.50.2- bioconductor-dada2=1.10.0
添加 bioconda 通道时,注意顺序,给予
conda-forge最高优先级,其次是bioconda。如果之前已经添加好了通道,自己在~/.condarc中调整顺序。conda config --add channels defaultsconda config --add channels biocondaconda config --add channels conda-forge
综合以上组合,之前尝试多次都没安装好的工具,直接搞定。
1.15 下载提速
- 国内镜像,见《软件安装不上,可能是网速慢!Conda/R/pip/brew 等国内镜像大全拿走不谢~~》。
- 换个网或从朋友处拷贝已经下载好的压缩包一般在
anaconda_root_dir/pkgs下,拷贝放在自己的anaconda3/pkgs下面,再次下载时系统会识别已经下载好的包而跳过(并不总是有效)。 - 获取所有相关包的名字,从朋友处拷贝下载好的安装包。如果拷贝过来未能自动识别,可手动安装
conda install --offline local_path。 ```bash mamba install r-base=4.0.2 r-ggplot2=3.3.2 —dry-run >package_solving_result
_anaconda_depends pkgs/main/linux-64::_anaconda_depends-2020.07-py37_0
_r-mutex conda-forge/noarch::_r-mutex-1.0.1-anacondar_1
binutils_impl_lin~ pkgs/main/linux-64::binutils_impl_linux-64-2.33.1-he6710b0_7
binutils_linux-64 conda-forge/linux-64::binutils_linux-64-2.33.1-h9595d00_17
brotlipy conda-forge/linux-64::brotlipy-0.7.0-py37h516909a_1000
bwidget conda-forge/linux-64::bwidget-1.9.14-0
gcc_impl_linux-64 pkgs/main/linux-64::gcc_impl_linux-64-7.3.0-habb00fd_1
gcc_linux-64 conda-forge/linux-64::gcc_linux-64-7.3.0-h553295d_17
获取所有包的名字
grep ‘::’ a | sed ‘s/.*:://‘ | sed ‘s/$/.tar.bz2/‘
手动安装
for i in grep '::' a | sed 's/.*:://' | sed 's/$/.tar.bz2/'; do conda install —offline /anaconda3/pkgs/$i; done
<a name="gq6pR"></a>### 1.16 使用 conda-pack 直接从已经安装好的地方拷贝一份(同一操作系统)安装 `conda-pack`:```bashconda install -c conda-forge conda-pack# pip install git+https://github.com/conda/conda-pack.git
打包已经安装好的环境:
conda pack -n my_env_name -o my_env_name.tar.gz
拷贝打包好的环境my_env_name.tar.gz到目标机器,并解压到任何目录,一般推荐放到envs目录下( anaconda_root/envs)。(注意:anaconda_root 改为自己的 conda 安装路径。)
# 解压打包好的环境# 默认是全都解压到当前目录,场面很壮观# -C 一定要指定mkdir -p anaconda_root/envs/my_envtar -xzf my_env.tar.gz -C anaconda_root/envs/my_env# 激活环境source my_env/bin/activate# Unpackconda-unpack# 至此环境就完全拷贝过来了source deactivate
2. Conda 常见异常与解决
2.1 json.decoder.JSONDecodeError
conda 在安装或者导入某些包/环境过程中出现 json.decoder.JSONDecodeError: Expecting value: line 478921 column 32 (char 14428018) 异常,具体可以参考 https://github.com/conda/conda/issues/9590 的解决方法:
- 方法一:删除 ~/.conda 和 ~/.condarc。
- 方法二:编辑 ~/.condarc,把其他的 channels 删除,只保留 ‘defaults’ channel。
- 方法三:使用 conda clean -i 命令移除 index cache。
个人在重装导出的环境文件时遇到类似的问题(conda/4.10.1,json.decoder.JSONDecodeError: Expecting value: line 478921 column 32 (char 14428018)),发现单纯的方法一,或者方法二、方法三都不能很好的解决问题。需要三个方法加起来才可以。
个人用的是清华大学的镜像,除了上面提到的 json.decoder.JSONDecodeError 以外,在安装过程中还引发了 ReadTimeoutError: HTTPSConnectionPool(host=’pypi.tuna.tsinghua.edu.cn’, port=443): Read timed out 异常,后来把默认的 pip 镜像换成阿里云的源,问题才得以解决。
2.2 CondaHTTPError: HTTP 000 CONNECTION FAILED
通过 conda update conda 的方式把 base 环境的 conda 升级到 4.10.3 后,使用 conda create/install 等命令安装软件时发现一直提示 CondaHTTPError: HTTP 000 CONNECTION FAILED!
在 https://github.com/conda/conda/issues/9746 上有这个问题的一些讨论和解决方法,个人尝试过都没办法解决!最后,重装 conda 后,问题解决。
# If you want to update an existing installation, use the -u option.$ sh /RiboBio/Bioinfo/Pipeline/src/pkgs/Miniconda3-latest-Linux-x86_64.sh -u
3. Conda 加速器之 Mamba 操作
几年前,生物信息数据分析,一个最大的问题即生物信息学软件安装。但现在绝大多数安装问题都可以通过使用conda,一键解决。如果要挑 conda 的毛病,那么就是速度不够快。于是就有了 Mamba。
Mamba 主页:https://quantstack.net/mamba.html
Mamba Github 地址:https://github.com/QuantStack/mamba
Mamba 是在 C++ 中对 conda 的重新实现,可以认为是更高级的 conda。有以下特点:
- 使用多线程并行下载数据和 package,实现更高效的安装。
- libsolv 能够更快地解决依赖关系,这是一个最先进的库,用于 Red Hat、Fedora 和 OpenSUSE 的 RPM 包管理器中。
- mamba 的核心部分是用 C++ 实现的,以获得最大的效率。
- 当我们使用 conda 进行安装时,如果速度太慢,可以改用 mamba 进行安装。
3.1 安装与更新
# 安装conda install mamba -n base -c conda-forge# 更新conda update mamba -n base -c conda-forge
3.2 mamba 的使用
安装完成之后,当你运行 mamba -V 查看其版本时会发现返回的是 Conda 的版本信息,这是因为 Mamba 的本质是对 Conda 功能的覆盖,因此我们在使用 Mamba 时其实只要将原有的 Conda 语句中的 conda 替换为 mamba 即可,譬如我们常用的 conda clean —all,即清空本地缓存安装包: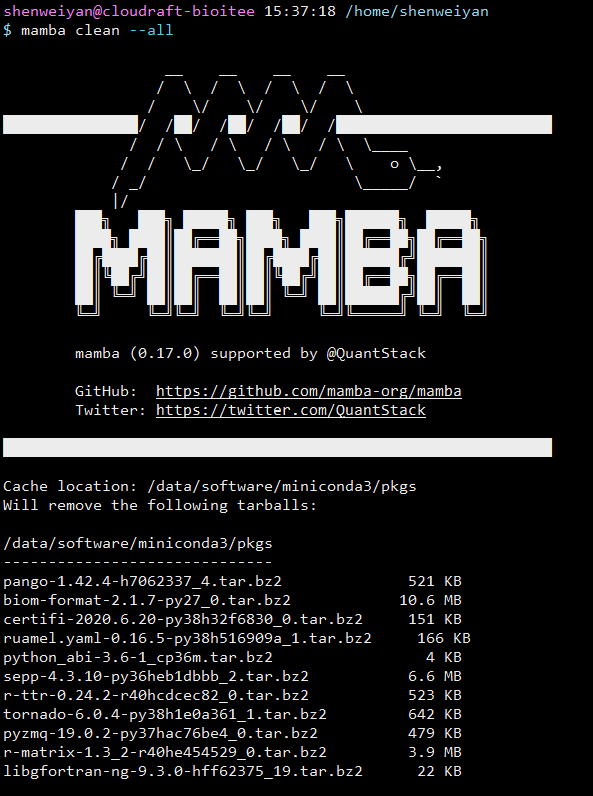
很有意思的是 Mamba 在执行命令时会先打印出logo等信息,对应其名称黑曼巴~
当然 Mamba 并不是重写了 Conda 所有的功能,只是针对一些 Conda 低效的功能进行重写,并添加了一些实用的新功能,接下来我们来对这些知识进行学习。
1. 加速下载
作为 Mamba 最核心的功能,Mamba 对 conda install 语句进行并行化改造,达到加速下载过程的目的。
以下载 qgis 为例,使用 mamba install -c conda-forge qgis -y 代替以前的安装方式,执行命令后,Mamba 会在短暂获取资源下载链接之后,以并行的方式按计划同时下载多个资源,比老方法要快很多。
对于其他涉及下载资源的命令譬如 conda update 同样适用,你可以自行体验。
2. 查看指定库所有可用版本
这是 Mamba 异于 Conda 的新功能,使用 mamba repoquery search 库名可以查看指定库全部所有可用版本,以 pandas 为例: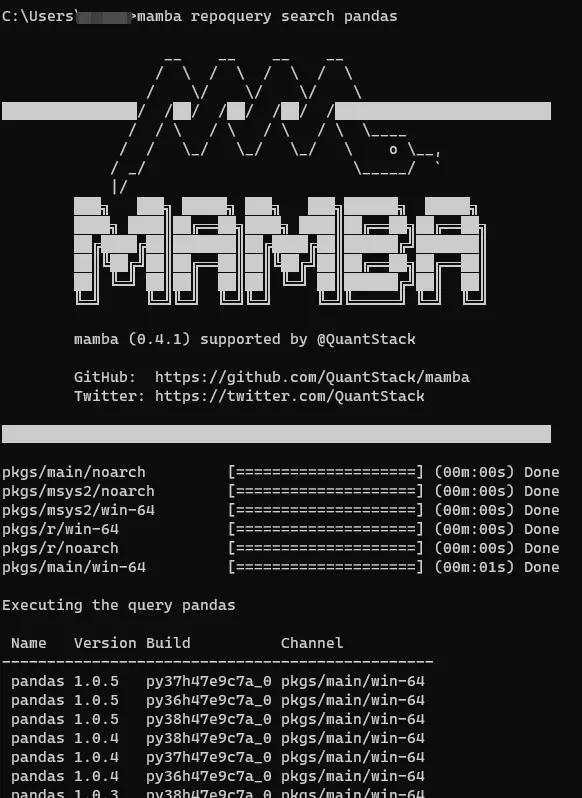
3. 查看依赖关系
Mamba 中还提供了 mamba repoquery depends 和 mamba repoquery whoneeds,分别用于查看指定库依赖哪些库,以及指定库被哪些库依赖,如官方文档的示例: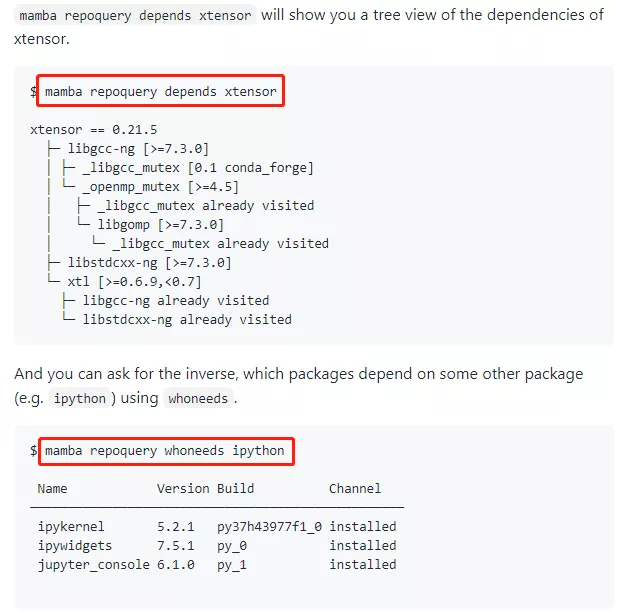
参考资料
- 费弗里,《Conda太慢?试试这个加速工具!》,Python大数据分析
- 郑淇,《生信软件安装神器 Mamba [conda加速器~]》,生信药丸
- kaopubear,《极速安装软件的升级版 conda》,生信媛

若有收获,就点个赞吧
0 人点赞
