摘要
Kafka体系架构:M个producer +N个broker +K个consumer+ZK集群
Topic: 消息主题,同一组消息的逻辑队列
分区:同一个Topic有多个分区,分为Leader分区与Follower分区,分布在不同的Broker中。Leader分区负责接收消息,并复制到Follower分区中。每个分区从0开始编号。
消息:每条消息写入到某个Broker中的Leader分区中,用分区offset表示该消息的唯一位置。
副本:每条消息有多个副本,分布在不同的分区里。
日志:消息以日志的形式顺序写入到磁盘,提高随机写磁盘的性能,从而具有很好的写性能,提高吞吐量。
在 Kafka 底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
消费者Offset: 消费者消费某个Broker中的分区,用消费者offset表示具体消费哪条消息。与分区offset无关系。
生产者:Kafka 客户端发送消息的应用,生产者只发送消息到Leader分区中。
消费者:Kafka 客户端消费消息的应用,消费者只消费Leader分区。
消费者组:多个消费者实例共同指定相同的消费者组名称后,组成一个消费者组,共同消费同一个主题下的所有分区,每个消费者只能消费一个分区。通常建议消费者数量小于等于分区数量,如果分区数量大于消费者,会出现某消费者无对应的消费分区。如果一个消费者失效,群组 里的其他消费者可以接管失效消费者的工作(重平衡)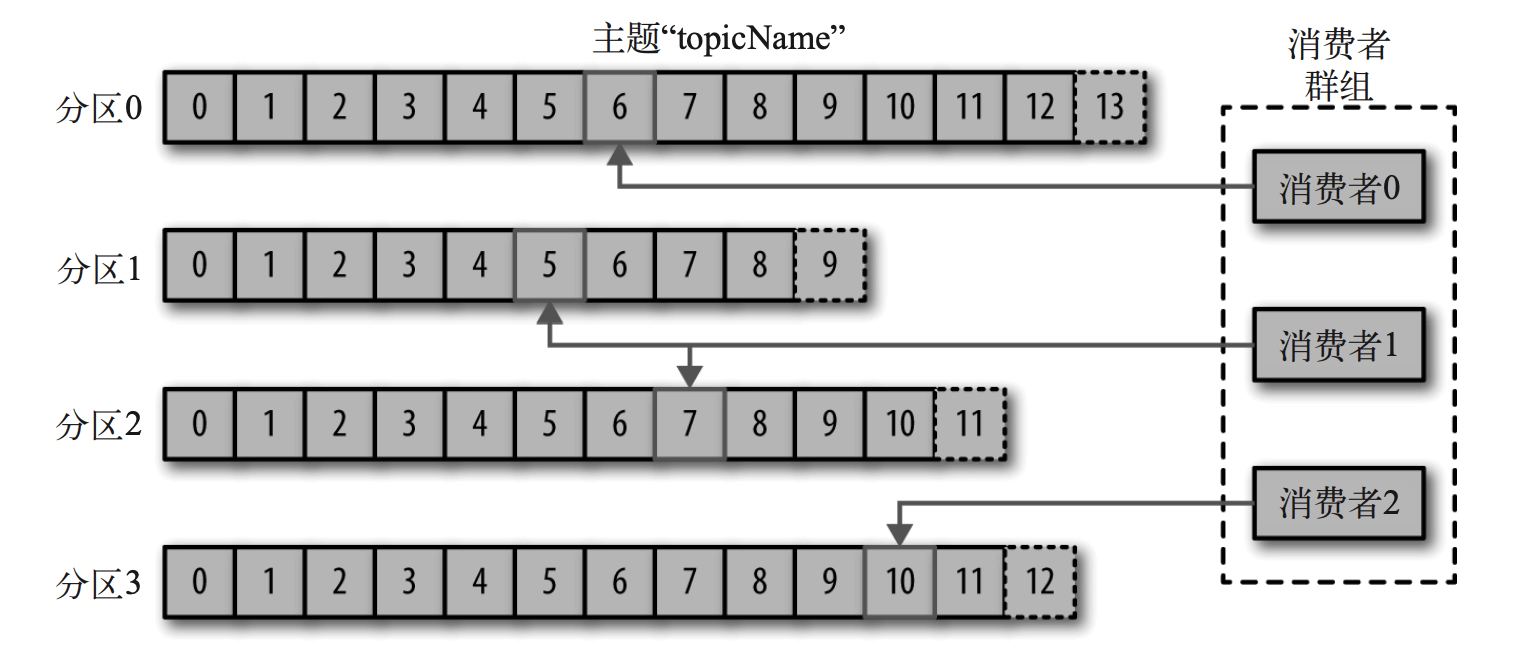
Broker:一个独立的Kafka 服务端实例称为Broker,多个Broker组成Kafka集群. broker 接收来自生产者的消息,为消息设置偏移 量,并提交消息到磁盘保存。broker 为消费者提供服务,对读取分区的请求作出响应,返 回已经提交到磁盘上的消息。根据特定的硬件及其性能特征,单个 broker 可以轻松处理数 千个分区以及每秒百万级的消息量.
Broker集群:每个Kafka集群都有一个 broker 同时充当了集群控制器的角色(自动 从集群的活跃成员中选举出来)控制器负责管理工作,包括将分区分配给 broker 和监控 broker。在集群中,一个分区从属于一个 broker,该 broker 被称为分区的Leader。一个分区 可以分配给多个 broker,这个时候会发生分区复制(见下图)。这种复制机制为分区提供 了消息冗余,如果有一个 broker 失效,其他 broker 可以接管领导权。不过,相关的消费者 和生产者都要重新连接到新的Leader.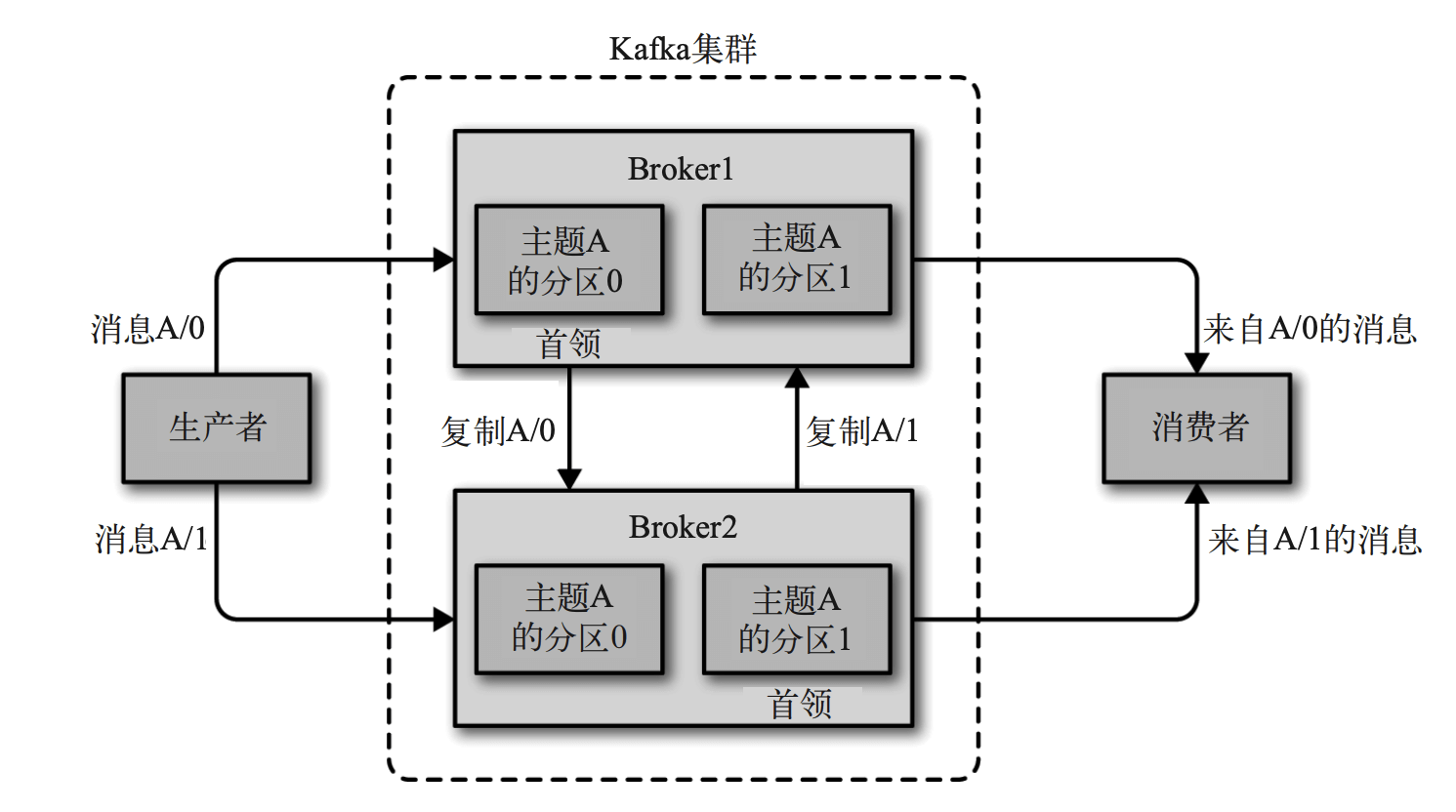
消息保留:是 Kafka 的一个重要特性。Kafka broker 默认的消息保留策略 是这样的:要么保留一段时间(比如 7 天),要么保留到消息达到一定大小的字节数(比 如 1GB)。
一张图

问题
为什么不像Redis,MySQL的读写分离(从节点提供读服务), Kafka Follower分区不对外提供读服务而只是做副本?
A1: Mysql通过读写分离来分担压力,多分区已经能实现负载均衡.
因为mysql一般部署在不同的机器上一台机器读写会遇到瓶颈,Kafka中的领导者副本一般均匀分布在不同的broker中,已经起到了负载的作用。即:同一个topic的已经通过分区的形式负载到不同的broker上了,读写的时候针对的领导者副本,但是量相比mysql一个还实例少太多,没有必要在提供度读服务了。
A2: 会造成不一致,如果要解决不一致的问题而引入更复杂的问题。
Kafka副本机制使用的是异步消息拉取,因此存在leader和follower之间的不一致性。如果要采用读写分离,必然要处理副本lag引入的一致性问题,比如如何实现read-your-writes、如何保证单调读(monotonic reads)以及处理消息因果顺序颠倒的问题。相反地,如果不采用读写分离,所有客户端读写请求都只在Leader上处理也就没有这些问题了——当然最后全局消息顺序颠倒的问题在Kafka中依然存在,常见的解决办法是使用单分区

若有收获,就点个赞吧
0 人点赞
