架构
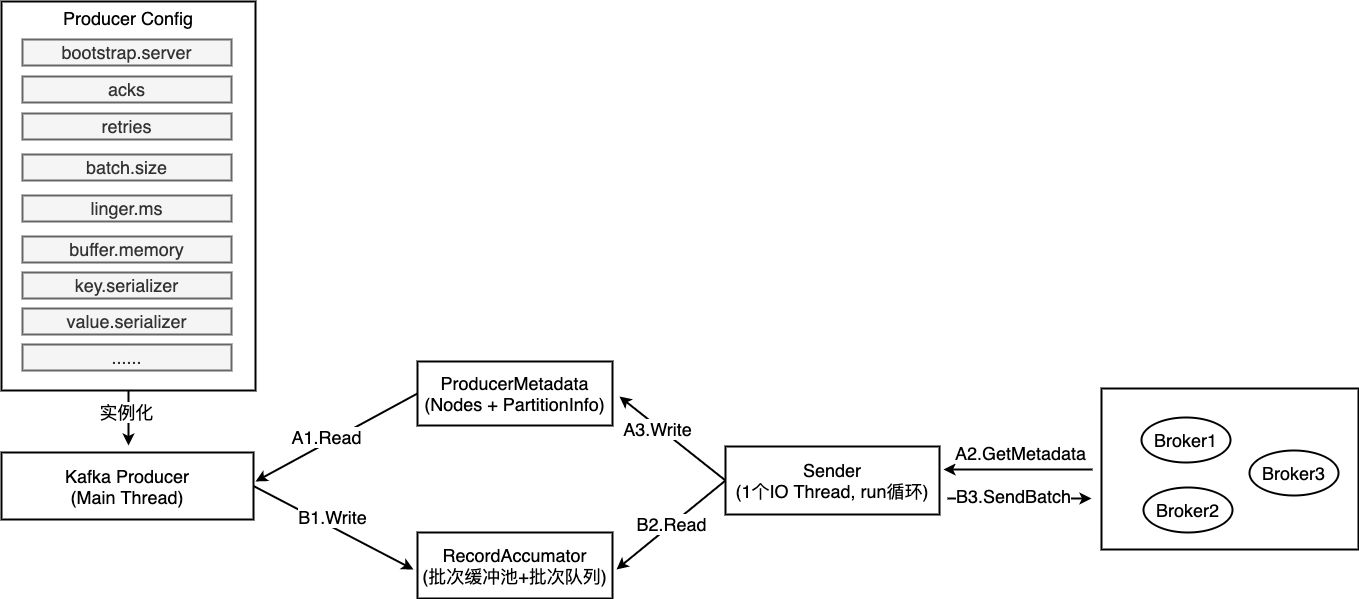
消息发送组件
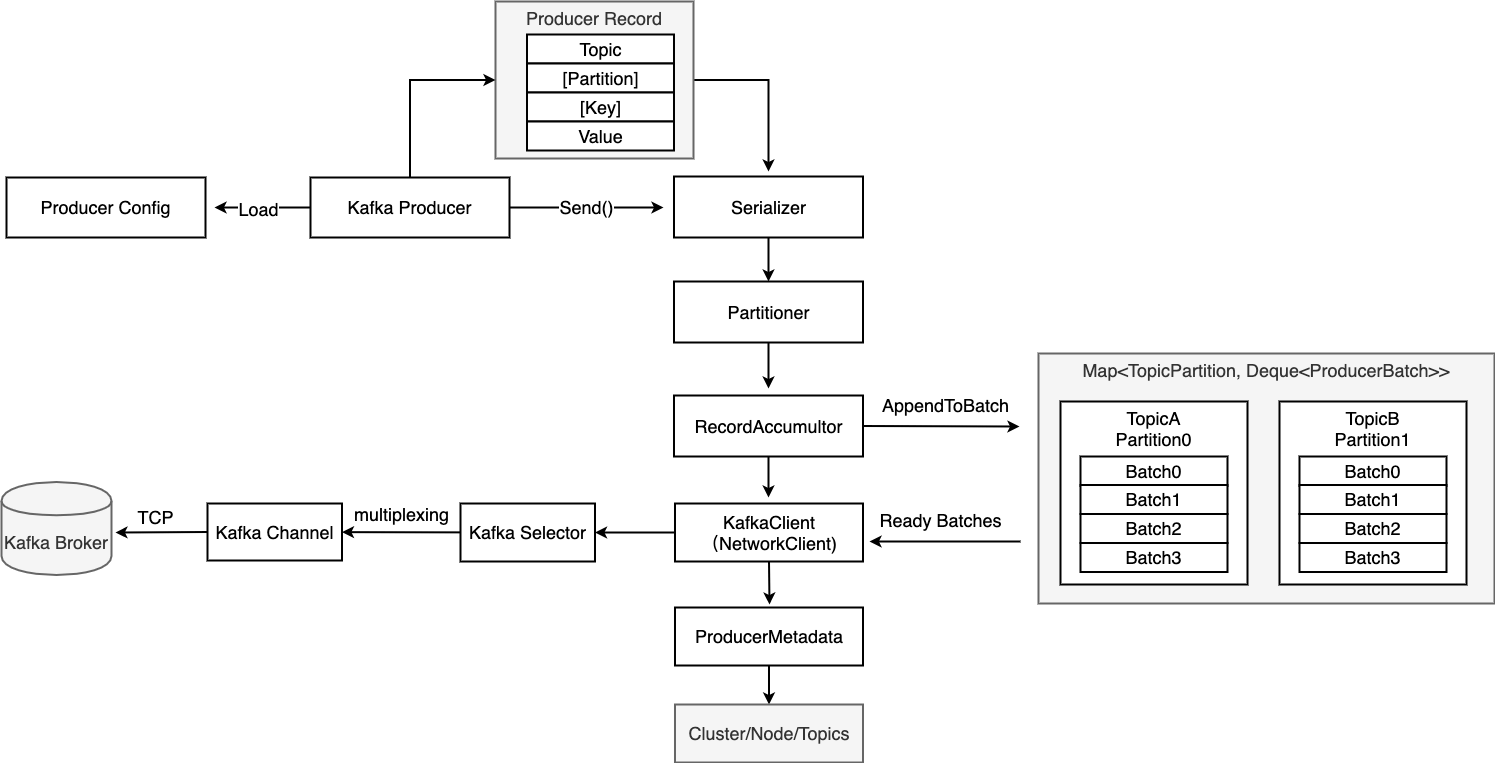
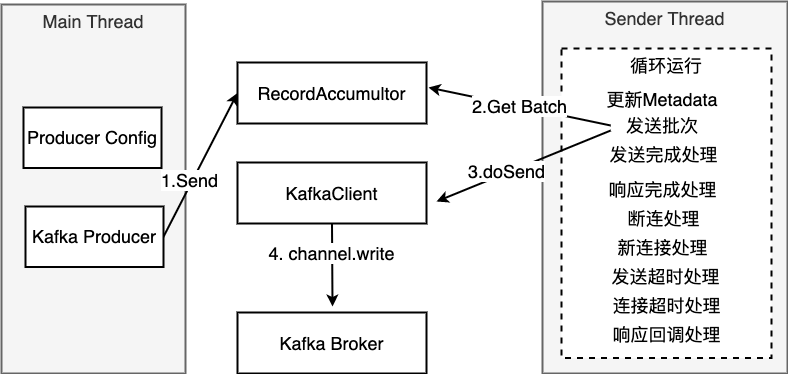
线程模型
使用介绍
Producer重要配置说明
生产者还有很多可配置的参数,在 Kafka 文档里都有说明,它们大部分都有合理的默认 值,所以没有必要去修改它们。不过有几个参数在内存使用、性能和可靠性方面对生产者 影响比较大,接下来我们会一一说明。
acks
acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。 这个参数对消息丢失的可能性有重要影响。该参数有如下选项。
- 如果 acks=0,生产者在成功写入消息之前不会等待任何来自服务器的响应。也就是说, 如果当中出现了问题,导致服务器没有收到消息,那么生产者就无从得知,消息也就丢 失了。不过,因为生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大 速度发送消息,从而达到很高的吞吐量。
- 如果 acks=1,只要集群的首领节点收到消息,生产者就会收到一个来自服务器的成功 响应。如果消息无法到达首领节点(比如首领节点崩溃,新的首领还没有被选举出来), 生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个 没有收到消息的节点成为新首领,消息还是会丢失。这个时候的吞吐量取决于使用的是同步发送还是异步发送。如果让发送客户端等待服务器的响应(通过调用 Future 对象 的 get() 方法),显然会增加延迟(在网络上传输一个来回的延迟)。如果客户端使用回 调,延迟问题就可以得到缓解,不过吞吐量还是会受发送中消息数量的限制(比如,生 产者在收到服务器响应之前可以发送多少个消息)。
- 如果 acks=all,只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自 服务器的成功响应。这种模式是最安全的,它可以保证不止一个服务器收到消息,就算 有服务器发生崩溃,整个集群仍然可以运行.不过,它的 延迟比 acks=1 时更高,因为我们要等待不只一个服务器节点接收消息。
buffer.memory
该参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果 应用程序发送消息的速度超过发送到服务器的速度,会导致生产者空间不足。这个时候, send() 方法调用要么被阻塞,要么抛出异常,取决于如何设置 block.on.buffer.full 参数
(在 0.9.0.0 版本里被替换成了 max.block.ms,表示在抛出异常之前可以阻塞一段时间)。compression.type
默认情况下,消息发送时不会被压缩。该参数可以设置为 snappy、gzip 或 lz4,它指定了 消息被发送给 broker 之前使用哪一种压缩算法进行压缩。snappy 压缩算法由 Google 发明, 它占用较少的 CPU,却能提供较好的性能和相当可观的压缩比,如果比较关注性能和网 络带宽,可以使用这种算法。gzip 压缩算法一般会占用较多的 CPU,但会提供更高的压缩 比,所以如果网络带宽比较有限,可以使用这种算法。使用压缩可以降低网络传输开销和 存储开销,而这往往是向 Kafka 发送消息的瓶颈所在。retries
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领)。在这种情况 下,retries 参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会 放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待 100ms,不过可以通过 retry.backoff.ms 参数来改变这个时间间隔。建议在设置重试次数和重试时间间隔之前, 先测试一下恢复一个崩溃节点需要多少时间(比如所有分区选举出首领需要多长时间), 让总的重试时间比 Kafka 集群从崩溃中恢复的时间长,否则生产者会过早地放弃重试。不 过有些错误不是临时性错误,没办法通过重试来解决(比如“消息太大”错误)。一般情 况下,因为生产者会自动进行重试,所以就没必要在代码逻辑里处理那些可重试的错误。 你只需要处理那些不可重试的错误或重试次数超出上限的情况。batch.size
当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指 定了一个批次可以使用的内存大小,按照字节数计算(而不是消息个数)。当批次被填满, 批次里的所有消息会被发送出去。不过生产者并不一定都会等到批次被填满才发送,半满 的批次,甚至只包含一个消息的批次也有可能被发送。所以就算把批次大小设置得很大, 也不会造成延迟,只是会占用更多的内存而已。但如果设置得太小,因为生产者需要更频 繁地发送消息,会增加一些额外的开销。linger.ms
该参数指定了生产者在发送批次之前等待更多消息加入批次的时间。KafkaProducer 会在 批次填满或 linger.ms 达到上限时把批次发送出去。默认情况下,只要有可用的线程,生 产者就会把消息发送出去,就算批次里只有一个消息。把 linger.ms 设置成比 0 大的数, 让生产者在发送批次之前等待一会儿,使更多的消息加入到这个批次。虽然这样会增加延 迟,但也会提升吞吐量(因为一次性发送更多的消息,每个消息的开销就变小了)。timeout.ms、request.timeout.ms 和 metadata.fetch.timeout.ms
request.timeout.ms 指定了生产者在发送数据时等待服务器返回响应的时间,metadata. fetch.timeout.ms 指定了生产者在获取元数据(比如目标分区的首领是谁)时等待服务器 返回响应的时间。如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误
(抛出异常或执行回调)。timeout.ms 指定了 broker 等待同步副本返回消息确认的时间,与 asks 的配置相匹配——如果在指定时间内没有收到同步副本的确认,那么 broker 就会返回 一个错误。max.block.ms
该参数指定了在调用 send() 方法或使用 partitionsFor() 方法获取元数据时生产者的阻塞 时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法就会阻塞。在阻 塞时间达到 max.block.ms 时,生产者会抛出超时异常。max.request.size
该参数用于控制生产者发送的请求大小。它可以指能发送的单个消息的最大值,也可以指 单个请求里所有消息总的大小。例如,假设这个值为 1MB,那么可以发送的单个最大消 息为 1MB,或者生产者可以在单个请求里发送一个批次,该批次包含了 1000 个消息,每 个消息大小为 1KB。另外,broker 对可接收的消息最大值也有自己的限制(message.max. bytes),所以两边的配置最好可以匹配,避免生产者发送的消息被 broker 拒绝。receive.buffer.bytes 和 send.buffer.bytes
这两个参数分别指定了 TCP socket 接收和发送数据包的缓冲区大小。如果它们被设为 -1, 就使用操作系统的默认值。如果生产者或消费者与 broker 处于不同的数据中心,那么可以 适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。
max.in.flight.requests.per.connection
限制每个连接(也就是客户端与Node之间的连接)最多缓存的请求数,默认值为5,即每个连接最多缓存5个未响应的的请求。通过比较Deque
依赖引入
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.7.0</version></dependency>
使用API发送消息(推荐使用Callback)
public class ProducerDemo {public static void main(String[] args) {// 1. 生产者配置Properties properties = new Properties();// 指定kafka地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 指定ack等级properties.put(ProducerConfig.ACKS_CONFIG, "all");// 指定重试次数,即生产者发送数据后没有收到ack应答时的重试次数properties.put(ProducerConfig.RETRIES_CONFIG, 3);// 指定批次大小 16k = 16 * 1024properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);// 指定等待时间,单位毫秒properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);// 指定RecordAccumulator缓冲区大小 32m = 32 * 1024 * 1024properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);// 指定k-v序列化规则properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 指定过滤器链:不常用// properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, Arrays.asList("kafka.MessageFormatInterceptor"));// 2. 创建生产者KafkaProducer<String, String> producer = new KafkaProducer<>(properties);// 3. 准备数据ProducerRecord<String, String> record = new ProducerRecord("quickstart-events", "this is a quick-start message");// 4. 发送数据(回调)producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception e) {if (e != null) {e.printStackTrace();} else {System.out.println("The offset of the record we just sent is: " + metadata.offset());System.out.println(metadata);}}});// 5. 关闭连接producer.close();}}
运行原理
概要
Kafka Producer采取异步的方式发送消息。当实例化一个Kafka Producer,同时会开启一个IO线程sender,该线程不断读取队列中的消息,然后通过Selector将数据发送给Kafka Server。用户调用Producer.send方法发送消息时,所执行的步骤如下:
- 与topic相关的broker建立连接,更新元数据(包括当前producer相关的topic,partition,broker等等信息),后续分析分析元数据时再细说。
- 根据key决定当前消息将发送给当前topic的哪个分区。如果用户给出key,则对该key进行哈希求余,得到分区号;如果用户没有提供key,则采用DefaultPartitioner方式决定分区。
- 将该消息添加到RecordAccumulator中对应的队列中,而RecordAccumulator内包含若干双端队列列表,每个topic的每个partition都对应着一个双端队列列表,每个列表含有若干RecordBatch,而每个RecordBatch可以存储若干条消息。
上述就是producer.send方法所执行的过程,当将数据放到队列后,即可返回执行下一次的producer.send; 因为异步,执行速度非常快; 接下来,当队列中有了数据之后,即可把视角切换到IO线程sender,sender线程处于一个while循环中,不断获取消息发送,执行过程如下:
- 将RecordAccumulator中消息按broker进行重新分类,因为kafka把发往同一个broker的消息整合在一个request中,因此,如果有四个broker,则会产生size=4的Map
将每个broker对应的List序列化后存储再ByteBuffer,并将这个ByteBuffer与broker对应的socketChannel绑定,最后注册到selector等待发送。代码见下:
public Send toSend(String destination, RequestHeader header) {return new NetworkSend(destination, serialize(header));}public ByteBuffer serialize(RequestHeader header) {return RequestUtils.serialize(header.toStruct(), toStruct());}
在下一次selector超时时,即可读取Kafka Server返回的response,并执行相应的回调函数;
bufferpool与批次的大小如何控制?
创建RecordAccumulator 时,通过配置指定buffer.memory 用来控制缓冲区ByteBuffer的最大内存占用
内部创建批次的buffer时用batch.size来控制批次占用的内存。
发送消息的大致流程?
org.apache.kafka.clients.producer.KafkaProducer#doSend方法逻辑:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {TopicPartition tp = null;try {throwIfProducerClosed(); // 检查Producer是否已经关闭// 获取集群元数据ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);nowMs += clusterAndWaitTime.waitedOnMetadataMs;long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);Cluster cluster = clusterAndWaitTime.cluster;// 序列化Keybyte[] serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());// 序列化Valuebyte[] valueSerializer = serialize(record.topic(), record.headers(), record.value());;// 计算发送的分区int partition = partition(record, serializedKey, serializedValue, cluster);tp = new TopicPartition(record.topic(), partition);// 包装回调执行链(如果指定了发送拦截器)// producer callback will make sure to call both 'callback' and interceptor callbackCallback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);// 把消息追加到批次里RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);// 达到发送条件-如果批次满了,或新创建了批次-唤醒阻塞在Select上的Selector// Sender线程会执行发送if (result.batchIsFull || result.newBatchCreated) {log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);this.sender.wakeup();}// 返回异步Future(这里主要是为了给同步调用场景使用,底层统一走异步Future模型)return result.future;} catch (ApiException e) {// 出现异常,直接把异常带出到回调中if (callback != null)callback.onCompletion(null, e);this.errors.record();this.interceptors.onSendError(record, tp, e);return new FutureFailure(e);}
如何把消息追加到批次里?
org.apache.kafka.clients.producer.internals.RecordAccumulator#append
public RecordAppendResult append(TopicPartition tp,long timestamp,byte[] key,byte[] value,Header[] headers,Callback callback,long maxTimeToBlock,boolean abortOnNewBatch,long nowMs) throws InterruptedException {try {// 创建TopicPartition对应的批次队列Deque<ProducerBatch> dq = getOrCreateDeque(tp);synchronized (dq) {// 获取队列最后一个批次,追加key、value字节RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);if (appendResult != null)return appendResult;}}最后调用到如下方法:org.apache.kafka.common.record.MemoryRecordsBuilder#appendLegacyRecordorg.apache.kafka.common.record.LegacyRecord#writepublic static long write(DataOutputStream out,byte magic,long timestamp,ByteBuffer key,ByteBuffer value,CompressionType compressionType,TimestampType timestampType) throws IOException {byte attributes = computeAttributes(magic, compressionType, timestampType);long crc = computeChecksum(magic, attributes, timestamp, key, value);write(out, magic, crc, attributes, timestamp, key, value);return crc;}底层通过DataOutputStream#write写入key/value
什么时候创建TCP连接?
Sender线程的run方法里,首次发送数据时会初始化连接
org.apache.kafka.clients.producer.internals.Sender#sendProducerData
private long sendProducerData(long now) {.....// remove any nodes we aren't ready to send toIterator<Node> iter = result.readyNodes.iterator();long notReadyTimeout = Long.MAX_VALUE;while (iter.hasNext()) {Node node = iter.next();if (!this.client.ready(node, now)) {iter.remove();notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));}}....}public boolean ready(Node node, long now) {if (node.isEmpty())throw new IllegalArgumentException("Cannot connect to empty node " + node);if (isReady(node, now))return true;// 初始化连接if (connectionStates.canConnect(node.idString(), now))// if we are interested in sending to a node and we don't have a connection to it, initiate oneinitiateConnect(node, now);return false;}
如何获取集群元数据?
Metadata的数据结构:
// 这个类被 client 线程和后台 sender 所共享,它只保存了所有 topic 的部分数据,当我们请求一个它上面没有的 topic meta 时,它会通过发送 metadata update 来更新 meta 信息,// 如果 topic meta 过期策略是允许的,那么任何 topic 过期的话都会被从集合中移除,// 但是 consumer 是不允许 topic 过期的因为它明确地知道它需要管理哪些 topicpublic final class Metadata {private static final Logger log = LoggerFactory.getLogger(Metadata.class);public static final long TOPIC_EXPIRY_MS = 5 * 60 * 1000;private static final long TOPIC_EXPIRY_NEEDS_UPDATE = -1L;private final long refreshBackoffMs; // metadata 更新失败时,为避免频繁更新 meta,最小的间隔时间,默认 100msprivate final long metadataExpireMs; // metadata 的过期时间, 默认 60,000msprivate int version; // 每更新成功1次,version自增1,主要是用于判断 metadata 是否更新private long lastRefreshMs; // 最近一次更新时的时间(包含更新失败的情况)private long lastSuccessfulRefreshMs; // 最近一次成功更新的时间(如果每次都成功的话,与前面的值相等, 否则,lastSuccessulRefreshMs < lastRefreshMs)private Cluster cluster; // 集群中一些 topic 的信息private boolean needUpdate; // 是都需要更新 metadata/* Topics with expiry time */private final Map<String, Long> topics; // topic 与其过期时间的对应关系private final List<Listener> listeners; // 事件监控者private final ClusterResourceListeners clusterResourceListeners; //当接收到 metadata 更新时, ClusterResourceListeners的列表private boolean needMetadataForAllTopics; // 是否强制更新所有的 metadataprivate final boolean topicExpiryEnabled; // 默认为 true, Producer 会定时移除过期的 topic,consumer 则不会移除}
关于 topic 的详细信息(leader 所在节点、replica 所在节点、isr 列表)都是在 Cluster 实例中保存的。
// 并不是一个全集,metadata的主要组成部分public final class Cluster {// 从命名直接就看出了各个变量的用途private final boolean isBootstrapConfigured;private final List<Node> nodes; // node 列表private final Set<String> unauthorizedTopics; // 未认证的 topic 列表private final Set<String> internalTopics; // 内置的 topic 列表private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition; // partition 的详细信息private final Map<String, List<PartitionInfo>> partitionsByTopic; // topic 与 partition 的对应关系private final Map<String, List<PartitionInfo>> availablePartitionsByTopic; // 可用(leader 不为 null)的 topic 与 partition 的对应关系private final Map<Integer, List<PartitionInfo>> partitionsByNode; // node 与 partition 的对应关系private final Map<Integer, Node> nodesById; // node 与 id 的对应关系private final ClusterResource clusterResource;}// org.apache.kafka.common.PartitionInfo// topic-partition: 包含 topic、partition、leader、replicas、isrpublic class PartitionInfo {private final String topic;private final int partition;private final Node leader;private final Node[] replicas;private final Node[] inSyncReplicas;}
Cluster 实例主要是保存:
- broker.id 与
node的对应关系; - topic 与 partition (
PartitionInfo)的对应关系; node与 partition (PartitionInfo)的对应关系。
第一次获取集群元数据:在Producer执行线程里发起
org.apache.kafka.clients.producer.KafkaProducer#waitOnMetadataprivate ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {// add topic to metadata topic list if it is not there already and reset expiryCluster cluster = metadata.fetch();metadata.add(topic, nowMs);// 如果之前已经获取了该topic的元数据,并缓存再cluster,则直接返回ClusterAndWaitTime实例Integer partitionsCount = cluster.partitionCountForTopic(topic);// Return cached metadata if we have it, and if the record's partition is either undefined// or within the known partition rangeif (partitionsCount != null && (partition == null || partition < partitionsCount))return new ClusterAndWaitTime(cluster, 0);long remainingWaitMs = maxWaitMs;long elapsed = 0;do {if (partition != null) {log.trace("Requesting metadata update for partition {} of topic {}.", partition, topic);} else {log.trace("Requesting metadata update for topic {}.", topic);}metadata.add(topic, nowMs + elapsed);int version = metadata.requestUpdateForTopic(topic);sender.wakeup();try {metadata.awaitUpdate(version, remainingWaitMs);} catch (TimeoutException ex) {// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMsthrow new TimeoutException(String.format("Topic %s not present in metadata after %d ms.",topic, maxWaitMs));}cluster = metadata.fetch();elapsed = time.milliseconds() - nowMs;if (elapsed >= maxWaitMs) {throw new TimeoutException(partitionsCount == null ?String.format("Topic %s not present in metadata after %d ms.",topic, maxWaitMs) :String.format("Partition %d of topic %s with partition count %d is not present in metadata after %d ms.",partition, topic, partitionsCount, maxWaitMs));}metadata.maybeThrowExceptionForTopic(topic);remainingWaitMs = maxWaitMs - elapsed;partitionsCount = cluster.partitionCountForTopic(topic);} while (partitionsCount == null || (partition != null && partition >= partitionsCount));return new ClusterAndWaitTime(cluster, elapsed);}
说明:在Producer线程里会更新Metadata的版本号,然后唤醒Sender线程,由Sender线程的poll方法完成元数据更新,更新Metadata完成后,Sender线程唤醒Producer线程。
所以Metadata的更新统一由Sender线程完成。
Sender线程的run方法会会轮询(Poll)检查是否要更新Metadata
public List<ClientResponse> poll(long timeout, long now) {...// 调用MetadataUpdater来更新元数据long metadataTimeout = metadataUpdater.maybeUpdate(now);...}org.apache.kafka.clients.NetworkClient.DefaultMetadataUpdater#maybeUpdateprivate long maybeUpdate(long now, Node node) {String nodeConnectionId = node.idString();// 发送元数据请求if (canSendRequest(nodeConnectionId, now)) {Metadata.MetadataRequestAndVersion requestAndVersion = metadata.newMetadataRequestAndVersion(now);MetadataRequest.Builder metadataRequest = requestAndVersion.requestBuilder;log.debug("Sending metadata request {} to node {}", metadataRequest, node);sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);inProgress = new InProgressData(requestAndVersion.requestVersion, requestAndVersion.isPartialUpdate);return defaultRequestTimeoutMs;}}
Sender线程循环执行runOnce方法里,会检查Broker的响应是否完成:
private void handleCompletedReceives(List<ClientResponse> responses, long now) {// 取回Metadata请求的响应if (req.isInternalRequest && response instanceof MetadataResponse)metadataUpdater.handleSuccessfulResponse(req.header, now, (MetadataResponse) response);}
然后由Updater更新元数据,最好执行到Metadata的update方法
org.apache.kafka.clients.Metadata#updatepublic synchronized void update(int requestVersion, MetadataResponse response, boolean isPartialUpdate, long nowMs) {.....// 更新集群缓存:更新分区信息,集群Node信息this.cache = handleMetadataResponse(response, isPartialUpdate, nowMs);Cluster cluster = cache.cluster();}
如何发送批次数据到Broker?
仍然是Sender线程负责。循环检查RecordAccumulator里的分区批次数据是否ready,然后取出所有Topic对应的批次,调用sendProduceRequest,然后由KafkaClient#send方法完成发送。
发送逻辑为:通过Builder把ProducerBatch 写入到ByteBuffer中,最后由org.apache.kafka.clients.NetworkClient#doSend完成发送到Channel里。
org.apache.kafka.clients.producer.internals.Sender#sendProduceRequest{ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,produceRecordsByPartition, transactionalId);RequestCompletionHandler callback = response -> handleProduceResponse(response, recordsByPartition, time.milliseconds());String nodeId = Integer.toString(destination);ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,requestTimeoutMs, callback);client.send(clientRequest, now);}
doSend把ProducerBatch写入到ByteBuffer里:
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {String destination = clientRequest.destination();RequestHeader header = clientRequest.makeHeader(request.version());if (log.isDebugEnabled()) {log.debug("Sending {} request with header {} and timeout {} to node {}: {}",clientRequest.apiKey(), header, clientRequest.requestTimeoutMs(), destination, request);}// 转为send对象:内部就是ByteBufferSend send = request.toSend(destination, header);InFlightRequest inFlightRequest = new InFlightRequest(clientRequest,header,isInternalRequest,request,send,now);this.inFlightRequests.add(inFlightRequest);selector.send(send);}Request的toSend方法public Send toSend(String destination, RequestHeader header) {return new NetworkSend(destination, serialize(header));}/*** Use with care, typically {@link #toSend(String, RequestHeader)} should be used instead.*/public ByteBuffer serialize(RequestHeader header) {return RequestUtils.serialize(header.toStruct(), toStruct());}
最好仍然是有Sender线程调用Selector完成数据写入到Channel里,这里走的是NIO模式
private void attemptWrite(SelectionKey key, KafkaChannel channel, long nowNanos) throws IOException {if (channel.hasSend()&& channel.ready()&& key.isWritable()&& !channel.maybeBeginClientReauthentication(() -> nowNanos)) {write(channel);}}void write(KafkaChannel channel) throws IOException {String nodeId = channel.id();// 这里完成实际的希尔到Channel里long bytesSent = channel.write();Send send = channel.maybeCompleteSend();// We may complete the send with bytesSent < 1 if `TransportLayer.hasPendingWrites` was true and `channel.write()`// caused the pending writes to be written to the socket channel bufferif (bytesSent > 0 || send != null) {long currentTimeMs = time.milliseconds();if (bytesSent > 0)this.sensors.recordBytesSent(nodeId, bytesSent, currentTimeMs);// 写入Send的完成后把send对象保存起来,放到completedSendsif (send != null) {this.completedSends.add(send);this.sensors.recordCompletedSend(nodeId, send.size(), currentTimeMs);}}}
响应结果回来如何回调?
在org.apache.kafka.clients.producer.internals.Sender#sendProduceRequest发送批次数据时,注册了回调函数Callback,然后Selector#write发送完成后,会把send对象放到completedSends。
ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,produceRecordsByPartition, transactionalId);RequestCompletionHandler callback = response -> handleProduceResponse(response, recordsByPartition, time.milliseconds());String nodeId = Integer.toString(destination);ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,requestTimeoutMs, callback);client.send(clientRequest, now);
Sender线程的通过KafkaClient#poll()方法把一些列的响应都放到一个List里。
poll方法逻辑如下:
public List<ClientResponse> poll(long timeout, long now) {....long metadataTimeout = metadataUpdater.maybeUpdate(now);// process completed actionslong updatedNow = this.time.milliseconds();List<ClientResponse> responses = new ArrayList<>();handleCompletedSends(responses, updatedNow); // 完成发送处理handleCompletedReceives(responses, updatedNow);// 完成响应处理handleDisconnections(responses, updatedNow); // 断连处理handleConnections(); // 建连处理handleInitiateApiVersionRequests(updatedNow);handleTimedOutConnections(responses, updatedNow); // 连接超时处理handleTimedOutRequests(responses, updatedNow); // 请求超时处理completeResponses(responses); // 响应回调处理return responses;}
handleCompletedSends把发送完成的Response放入到List中, Send完成的Response会带入Request注册的Callback。
private void handleCompletedSends(List<ClientResponse> responses, long now) {// if no response is expected then when the send is completed, return itfor (Send send : this.selector.completedSends()) {InFlightRequest request = this.inFlightRequests.lastSent(send.destination());if (!request.expectResponse) {this.inFlightRequests.completeLastSent(send.destination());// 这里会Request发起时注册的Callbackresponses.add(request.completed(null, now));}}}
最后统一执行:completeResponses,逐个调用之前注册的回调。
private void completeResponses(List<ClientResponse> responses) {for (ClientResponse response : responses) {try {response.onComplete();} catch (Exception e) {log.error("Uncaught error in request completion:", e);}}}
参考文档
https://blog.csdn.net/chunlongyu/article/details/52622422
https://matt33.com/2017/07/08/kafka-producer-metadata/
http://luodw.cc/2017/05/02/kafka02/

若有收获,就点个赞吧
0 人点赞
