概要
zookeeper是一个基于观察者设计模式的分布式服务管理框架,它负责和管理需要关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
zookeeper的特点:
zookeeper的原理
架构
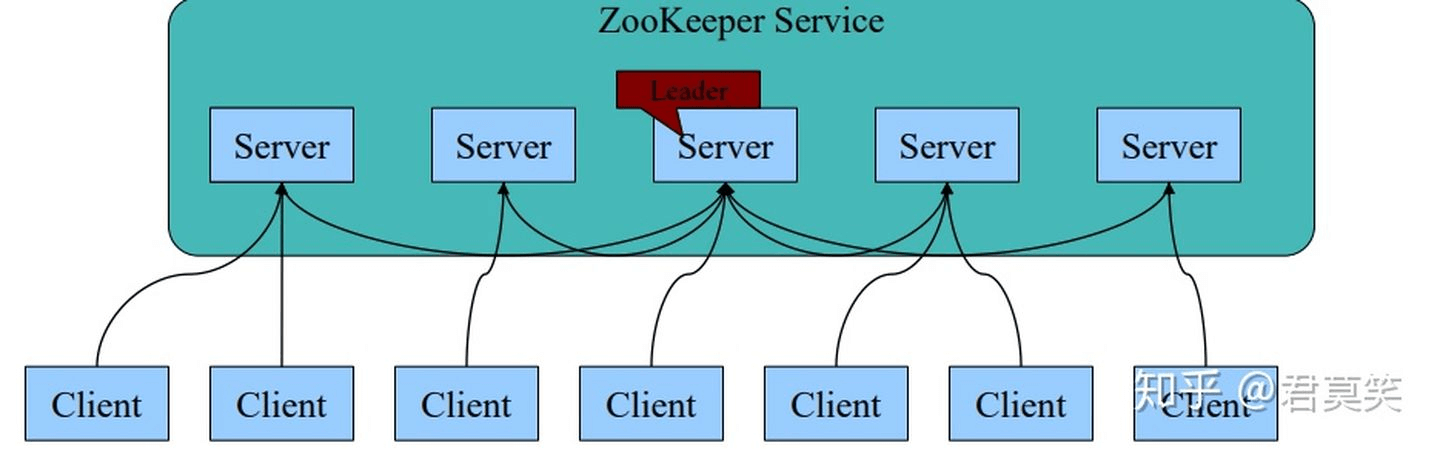
- 一个领导者(Leader)和多个跟随者(Follower)组成的集群,在启动时根据Paxos协议选举一个Leader。
- 集群中只要有半数以上的节点存活,Zookeeper集群就能正常服务。
- 全局一致性:每个Server保存一份相同的数据副本,Client无论链接到哪个Server,数据都是一致的。
- Leader根据Zab协议负责处理数据的更新等操作。
- 更新请求顺序进行,来自同一个Client的更新请求按其发送顺序依次执行。
- 原子性:一次更新操作(可以是多个),当且仅当大多数Server在内存中成功修改数据,要么成功,要么失败。
- 实时性:在一定时间范围内,Client能读到最新数据。
Zookeeper角色
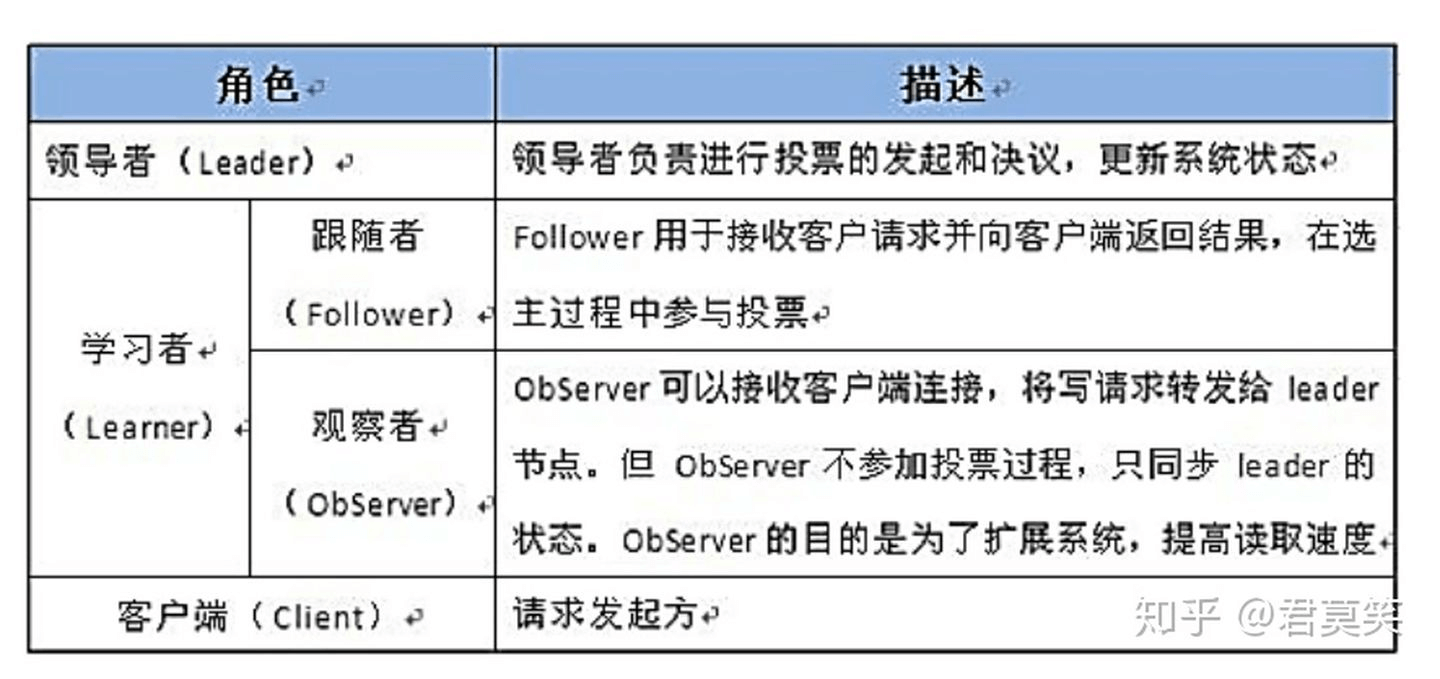
- Leader选举算法采用了Paxos协议;
Paxos核心思想:当多数Server写成功,则任务数据写成功。
- 如果有3个Server,则需要2个写成功即可。
- 如果有5个Server,则需要3个写成功即可。
Zookeeper Server数目一般为奇数
- 如果有3个Server,则最多允许1个Server挂掉。
- 如果有4个Server,则最多允许1个Server挂掉。
Zookeeper数据结构
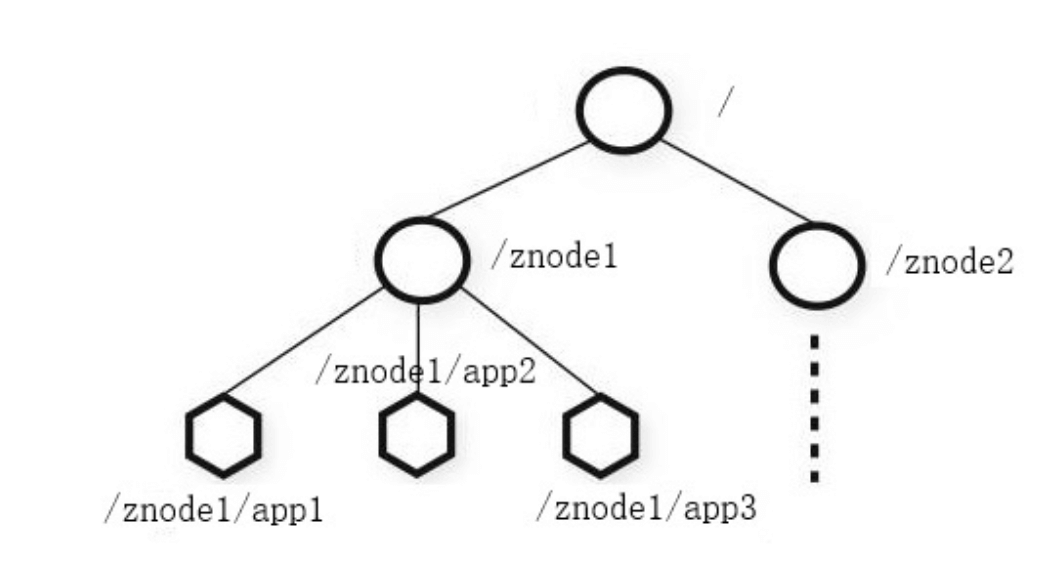
- Zookeeper数据模型结构与Unix文件系统很像,整体可以看做是树,每个节点为一个Znode,每一个Znode默认能存储1MB数据,每个Znode都可以通过其路径唯一标识。
- 和Unix不同的是,Znode可以存数据,又可有子节点。(不同于文件和文件夹的概念)
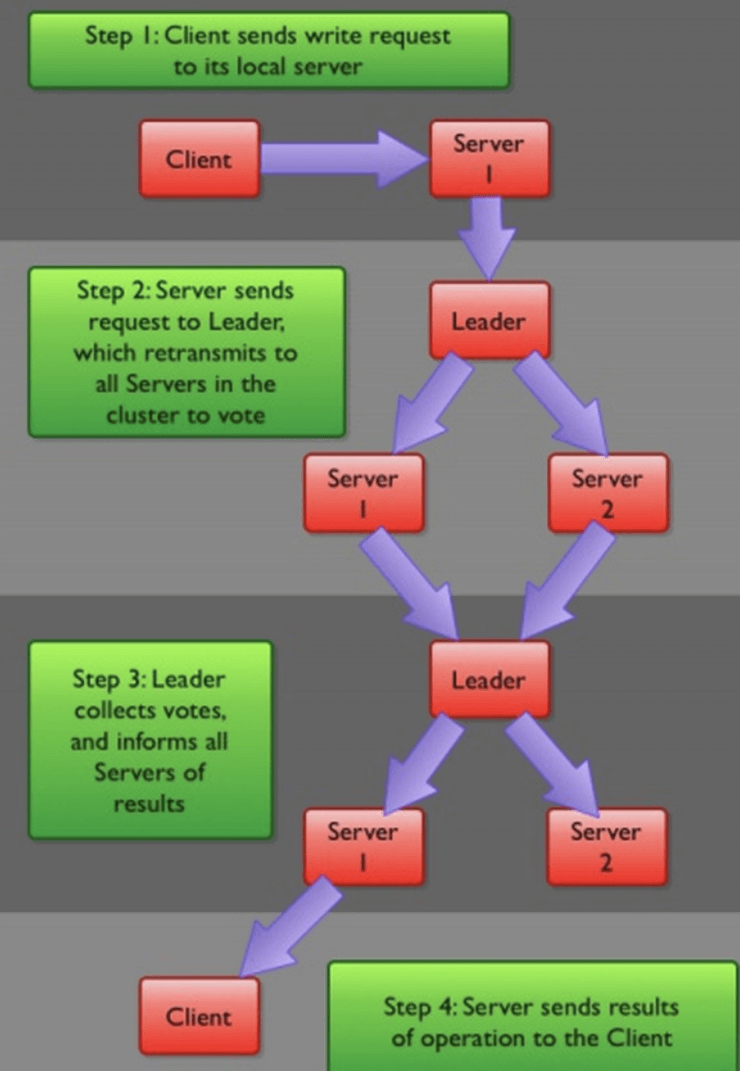
Zookeeper 数据写流程
基本API
持久节点(persistent)和临时节点(ephemeral)
持久节点只能通过delete删除。临时节点在创建该节点的客户端崩溃或关闭时,自动被删除。
前面例子中的/master应该使用临时节点,这样当主节点失效或者退出时,该znode被删除,其他节点知道主节点崩溃了,开始进行选举的逻辑。另外/works/worker-1也应该是临时节点,在此从节点失效的时候,该临时节点自动删除。
在目前的版本,由于临时znode会因为创建者会话过期被删除,所以不允许临时节点拥有子节点。
有序节点
znode可以被设置为有序(sequential)节点。有序znode节点被分配唯一一个单调递增的证书。如果创建了个一有序节点为/workers/worker-,zookeeper会自动分配一个序号1,追加在名字后面,znode名称为/workers/worker-1。通过这种方式,可以创建唯一名称znode,并且可以直观的看到创建的顺序。
znode支持的操作及暴露的API:
create /path data
创建一个名为/path的znode,数据为data。
delete /path
删除名为/path的znode。
exists /path
检查是否存在名为/path的znode
setData /path data
设置名为/path的znode的数据为data
getData /path
返回名为/path的znode的数据
getChildren /path
返回所有/path节点的所有子节点列表
观察与通知
分布式应用需要及时知道zookeeper中znode的变化,从而了解到分布式应用整体的状况,如果采用轮询方式,代价太大,绝大多数查询都是无效的。因此,zookeeper采用了通知的机制。客户端向zookeeper请求,在特定的znode设置观察点(watch)。当该znode发生变化时,会触发zookeeper的通知,客户端收到通知后进行业务处理。观察点触发后立即失效。所以一旦观察点触发,需要再次设置新的观察点。
我们使用Zookeeper不能期望能够监控到节点每次的变化。思考如下场景:
1、客户端C1设置观察点在/tasks
2、观察点触发,C1处理自己的逻辑
3、C1设置新的观察点前,C2更新了/tasks
4、C1处理完逻辑,再次设置了观察点。
此时C1不会得到第三步的通知,因此错过了C2更新/tasks这次操作。要想不错过这次更新,C1需要在设置监视点前读取/tasks的数据,进行对比,发现更新。
再如下面的场景:
1、客户端C1设置观察点在/tasks
2、/tasks上发生了连续两次更新
3、C1在得到第一次更新的通知后就读取了/tasks的数据
4、此时第二次更新也已经发生,C1用第一次的通知,读取到两次更新后的数据
此时C1虽然错过了第二次通知,但是C1最终还是读取到了最新的数据。
因此Zookeeper只能保证最终的一致性,而无法保证强一致性。
zookeeper可以定义不同的观察类型。例如观察znode数据变化,观察znode子节点变化,观察znode创建或者删除。
版本
每个znode都有版本号,随着每次数据变化自增。setData和delete,以版本号作为参数,当传入的版本号和服务器上不一致时,调用失败。当多个zookeeper客户端同时对一个znode操作时,版本将会起到作用,假设c1,c2同时往一个znode写数据,c1先写完后版本从1升为2,但是c2写的时候携带版本号1,c2会写入失败。
法定票数
zookeeper服务器运行于两种模式:独立模式和仲裁模式(集群)。仲裁模式下,会复制所有服务器的数据树。但如果让客户端等待所有复制完成,延迟太高。这里引入法定人数概念,指为了使zookeeper集群正常工作,必须有效运行的服务器数量。同时也是服务器通知客户端保存成功前,必须保存数据的服务器最小数。例如我们有一个5台服务器的zookeeper集群,法定人数为3,只要任何3个服务器保存了数据,客户端就会收到确认。只要有3台服务器存活,整个zookeeper集群就是可用的。
使用场景
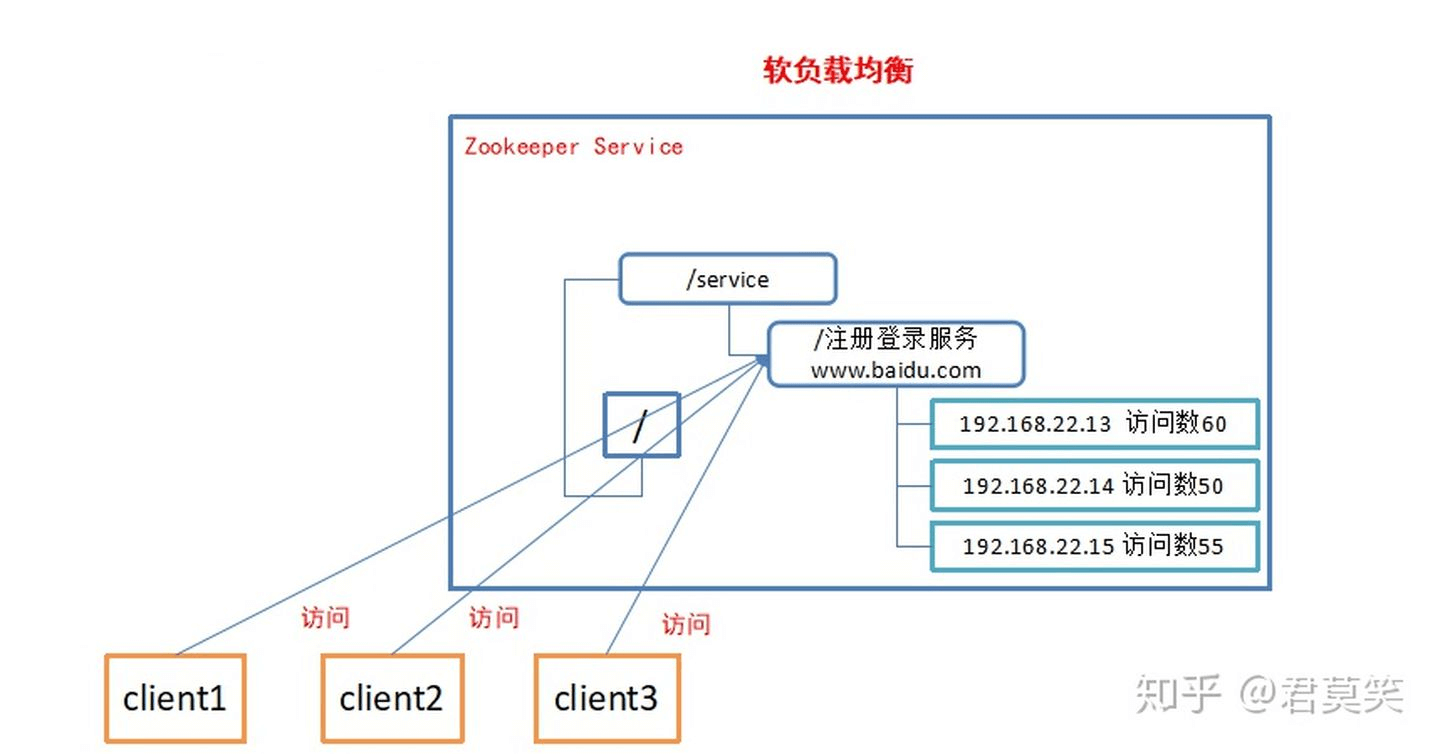
统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
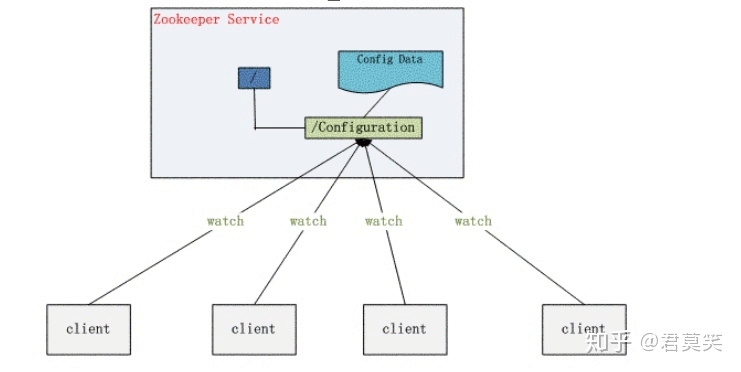
配置管理
一个集群中,所有节点的配置信息是一致的,对配置文件修改后,希望能够快速同步到各个节点上。例如Hadoop。
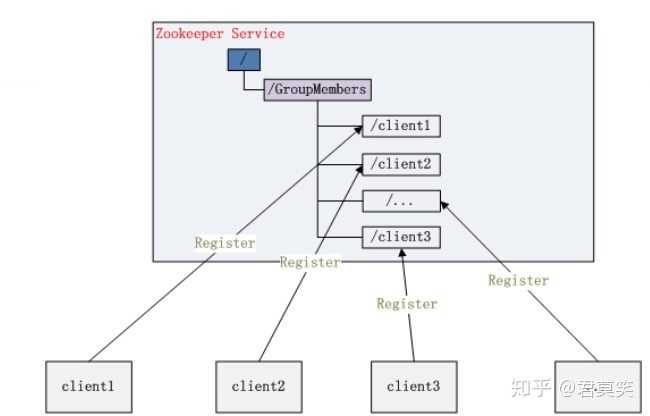
集群管理
分布式环境中,实时掌握每个节点的状态是必要的。例如集群中的Master的监控和选举
分布式通知/协调
分布式环境中,经常存在一个服务需要知道它所管理的子服务状态。例如NameNode需要知道DataNode状态。
分布式锁
多个客户端同时在Zookeeper上创建相同的znode,只有一个创建成功。创建成功的客户端得到锁,其他客户端等待。或基于临时顺序节点来实现锁功能
分布式队列
当一个列队的成员都聚齐时,这个列队才可用,否则一直等待所有成员到达,这种事同步列队。列队按照FIFO方式进行入队和出队操作,例如实现生产者和消费者模型。同步列队中一个Job由多个task组成,只有所有任务完成后,Job才运行完成。如:可以为Job创建一个/job的节点,在其下每完成一个task创建一个临时的znode,一旦临时节点数达到task总数,则Job运行完成。
示例
Provider注册/Consumer监听
AppServer
package zookeeper;import org.apache.zookeeper.CreateMode;import org.apache.zookeeper.WatchedEvent;import org.apache.zookeeper.Watcher;import org.apache.zookeeper.ZooDefs;import org.apache.zookeeper.ZooKeeper;import org.apache.zookeeper.data.Stat;import java.net.Inet4Address;/*** @author xiele on 2021/2/4*/public class AppServer {private String groupNode = "sgroup";private String subNode = "sub";/*** 连接zookeeper** @param address server的地址*/public void connectZookeeper(String address) throws Exception {ZooKeeper zk = new ZooKeeper("127.0.0.1:2181",5000, new Watcher() {public void process(WatchedEvent event) {// 不做处理System.out.println("watchEvent=" + event);}});// 在"/sgroup"下创建子节点// 子节点的类型设置为EPHEMERAL_SEQUENTIAL, 表明这是一个临时节点, 且在子节点的名称后面加上一串数字后缀// 将server的地址数据关联到新创建的子节点上// 先创建父节点Stat exists = zk.exists("/" + groupNode, false);if (exists == null) {String createdSGroupPath = zk.create("/" + groupNode, null,ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);System.out.println("create sgroup: " + createdSGroupPath);}String createdPath = zk.create("/" + groupNode + "/" + subNode, address.getBytes("utf-8"),ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);System.out.println("create: " + createdPath + ", data:" + address);}/*** server的工作逻辑写在这个方法中* 此处不做任何处理, 只让server sleep*/public void handle() throws InterruptedException {Thread.sleep(Long.MAX_VALUE);}public static void main(String[] args) throws Exception {String hostAddress = Inet4Address.getLocalHost().getHostAddress();AppServer as = new AppServer();as.connectZookeeper(hostAddress);as.handle();}}
AppClient
package zookeeper;import org.apache.zookeeper.WatchedEvent;import org.apache.zookeeper.Watcher;import org.apache.zookeeper.ZooKeeper;import org.apache.zookeeper.data.Stat;import org.junit.Test;import java.util.ArrayList;import java.util.List;/*** @author xiele on 2021/2/4*/public class AppClient {private String groupNode = "sgroup";private ZooKeeper zk;private Stat stat = new Stat();private volatile List<String> serverList;/*** 连接zookeeper*/public void connectZookeeper() throws Exception {zk = new ZooKeeper("127.0.0.1:2181", 5000, new Watcher() {public void process(WatchedEvent event) {// 如果发生了"/sgroup"节点下的子节点变化事件, 更新server列表, 并重新注册监听if (event.getType() == Event.EventType.NodeChildrenChanged&& ("/" + groupNode).equals(event.getPath())) {try {updateServerList();} catch (Exception e) {e.printStackTrace();}}}});updateServerList();}/*** 更新server列表*/private void updateServerList() throws Exception {System.out.println("updateServerList...");List<String> newServerList = new ArrayList<String>();// 获取并监听groupNode的子节点变化// watch参数为true, 表示监听子节点变化事件.// 每次都需要重新注册监听, 因为一次注册, 只能监听一次事件, 如果还想继续保持监听, 必须重新注册List<String> subList = zk.getChildren("/" + groupNode, true);for (String subNode : subList) {// 获取每个子节点下关联的server地址byte[] data = zk.getData("/" + groupNode + "/" + subNode, false, stat);newServerList.add(new String(data, "utf-8"));}// 替换server列表serverList = newServerList;System.out.println("server list updated: " + serverList);}/*** client的工作逻辑写在这个方法中* 此处不做任何处理, 只让client sleep*/public void handle() throws InterruptedException {Thread.sleep(Long.MAX_VALUE);}public static void main(String[] args) throws Exception {AppClient ac = new AppClient();ac.connectZookeeper();ac.handle();}}
先启动Client,此时拿到的server list is empty, 再启动一个server, 监听到一个server,再启动一个server,继续监听到一个server.
updateServerList...server list updated: []updateServerList...server list updated: [127.0.0.1]updateServerList...server list updated: [127.0.0.1, 127.0.0.1]updateServerList...server list updated: [127.0.0.1]updateServerList...server list updated: []create: /sgroup/sub0000000001, data:127.0.0.1create: /sgroup/sub0000000002, data:127.0.0.1
zkServer.sh&zkCli.sh使用
Start Serverbin/zkServer.sh start查看Server状态bin/zkServer.sh status查看帮助bin/zkServer.sh help启动CLient,连接Serverbin/zkCli.sh -server localhost:2181 (等同于 bin/zkCli.sh)查看Client Helpbin/zkCli.sh help
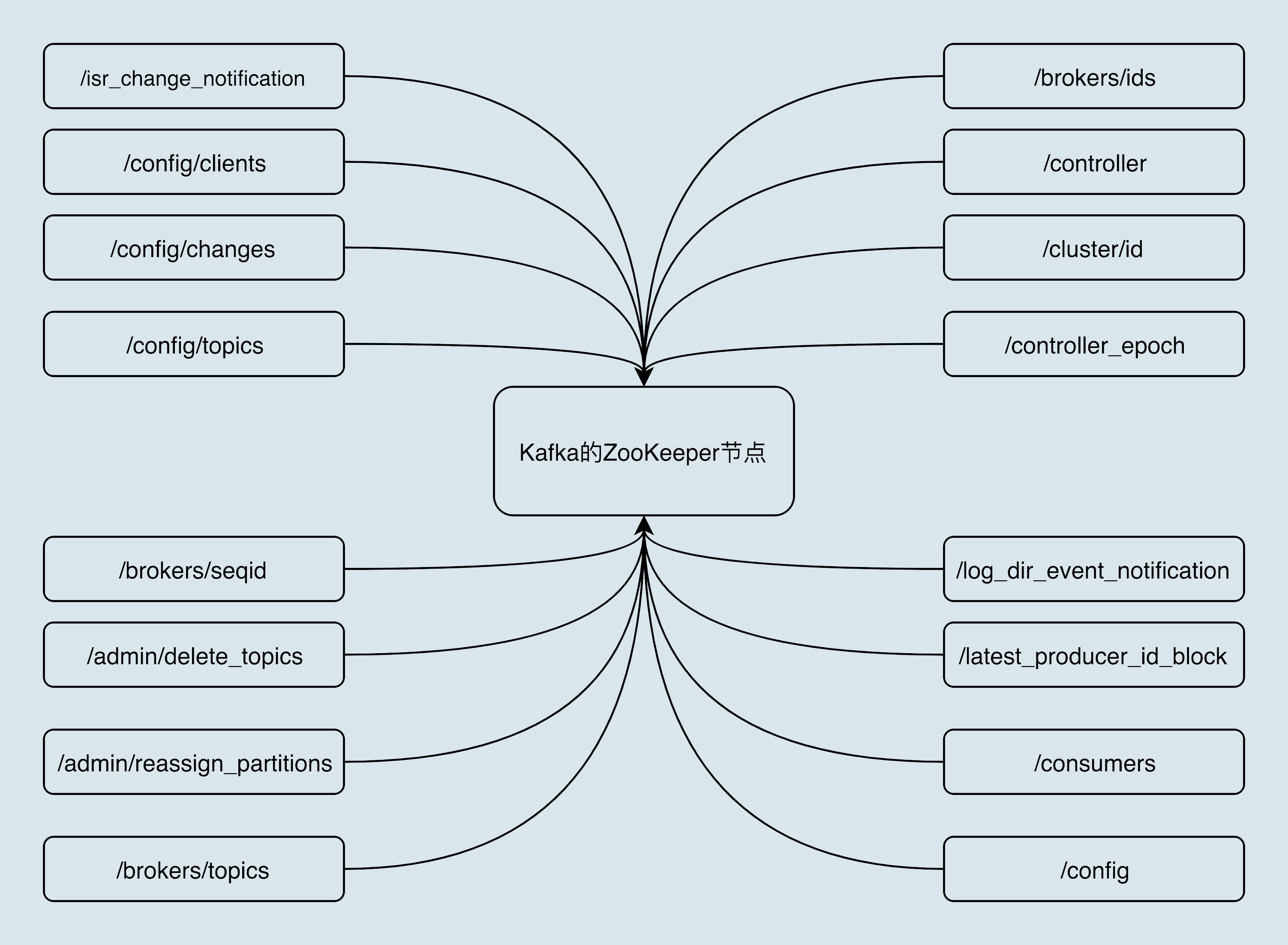
附录
kafka zookeeper znode

若有收获,就点个赞吧
0 人点赞
