什么是分层架构
DDD的分层架构有多种,如传统的DDD分层架构,依赖倒置的分层架构,整洁架构,CQRS,六边形架构等。比如DDD中常用的2中分层架构如图: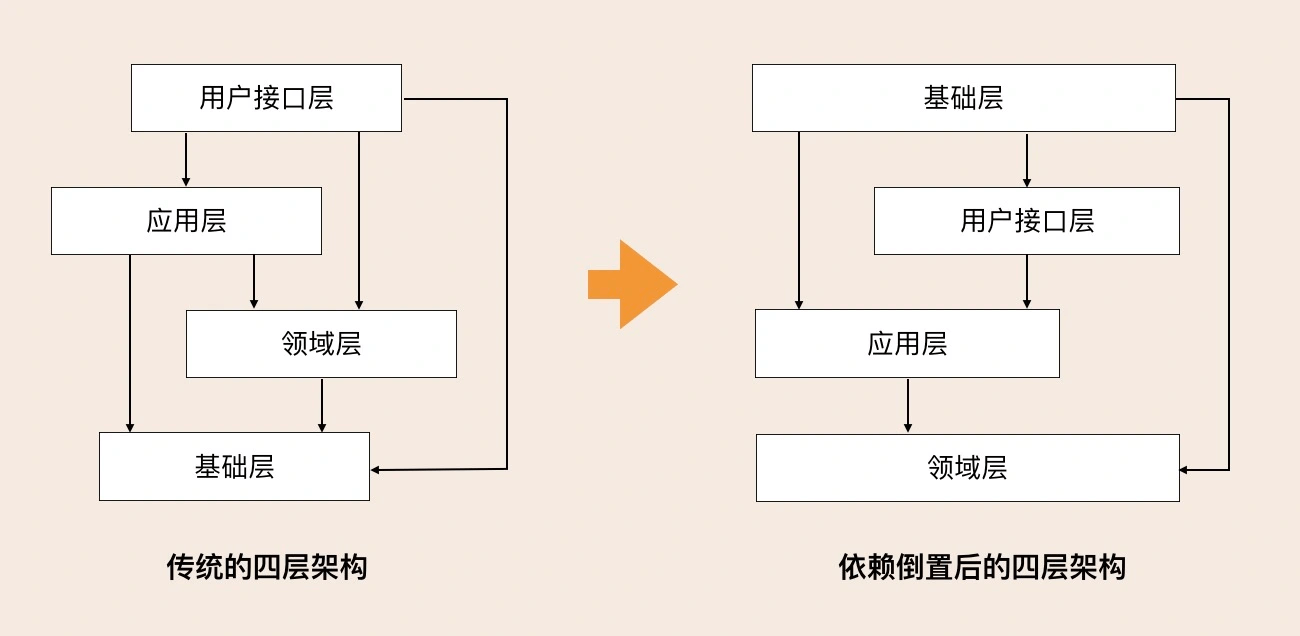
依赖倒置后的四层架构只是在源代码层面做了依赖调整,实现了各层对基础层的解耦。核心是更多的关注领域与模型,不关注基础设施。所以针对各层职责,整体指导原则如下: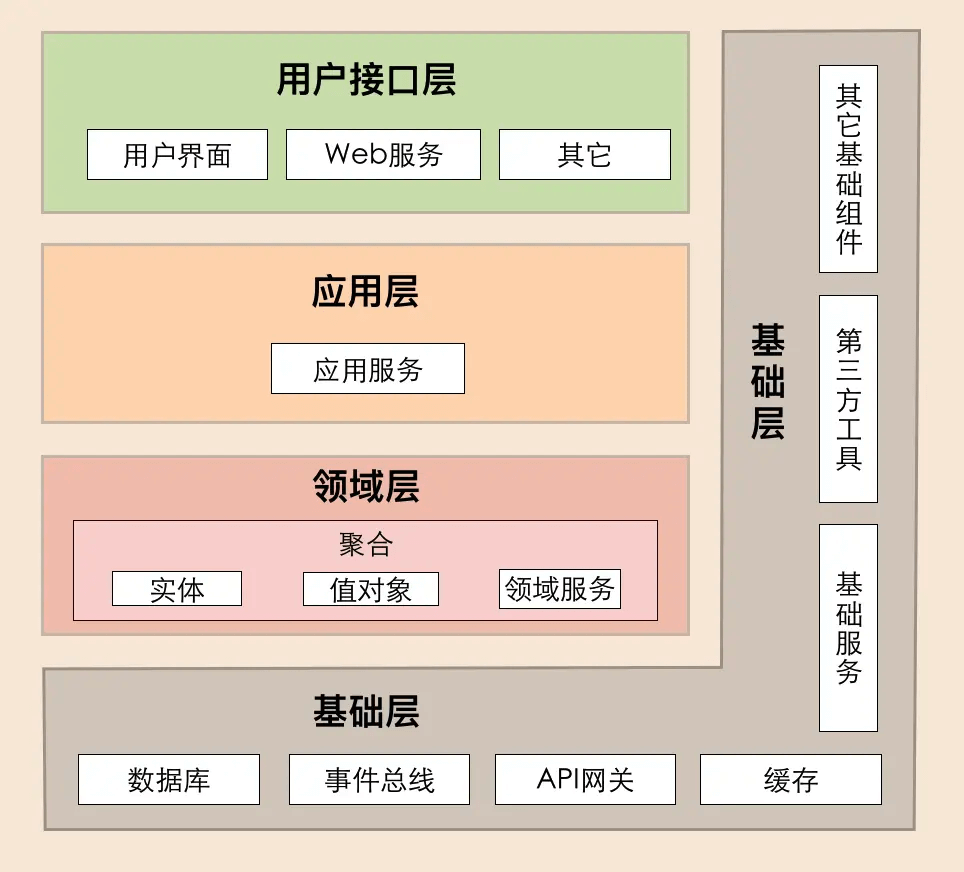
1.用户接口层
用户接口层负责向用户显示信息和解释用户指令。这里的用户可能是:用户、程序、自动化测试和批处理脚本等等。
2.应用层
应用层是很薄的一层,理论上不应该有业务规则或逻辑,主要面向用例和流程相关的操作。但应用层又位于领域层之上,因为领域层包含多个聚合,所以它可以协调多个聚合的服务和领域对象完成服务编排和组合,协作完成业务操作。
此外,应用层也是微服务之间交互的通道,它可以调用其它微服务的应用服务,完成微服务之间的服务组合和编排。
在设计和开发时,不要将本该放在领域层的业务逻辑放到应用层中实现。因为庞大的应用层会使领域模型失焦,时间一长,业务逻辑会变得混乱,最终演化为传统的三层架构。
另外,应用服务是在应用层的,它负责服务的组合、编排和转发,负责处理业务用例的执行顺序以及结果的拼装,以粗粒度的服务通过API网关向前端发布。还有,应用服务还可以进行安全认证、权限校验、事务控制、发送或订阅领域事件等。
3.领域层
领域层的作用是实现核心业务逻辑,通过各种校验手段保证业务的正确性。领域层主要体现领域模型的业务能力,它用来表达业务概念、业务状态和业务规则。领域层包含聚合根、实体、值对象、领域服务等领域模型中的领域对象。领域模型的业务逻辑主要是由实体和领域服务来实现的,其中实体会采用充血模型来实现所有与之相关的业务功能。其次,实体和领域服务在实现业务逻辑上不是同级的,当领域中的某些功能,单一实体(或者值对象)不能实现时,则需要领域服务,它可以组合聚合内的多个实体(或者值对象),实现复杂的业务逻辑。
4.基础层
基础层是贯穿所有层的,它的作用就是为其它各层提供通用的技术和基础服务,包括第三方工具、驱动、消息中间件、网关、文件、缓存以及数据库等。比较常见的功能还是提供数据库持久化。
基础层包含基础服务,它采用依赖倒置设计,封装基础资源服务,实现应用层、领域层与基础层的解耦,降低外部资源变化对应用的影响。比如说,在传统架构设计中,由于上层应用对数据库的强耦合,很多公司在架构演进中最担忧的可能就是换数据库了,因为一旦更换数据库,就可能需要重写大部分的代码,这对应用来说是致命的。那采用依赖倒置的设计以后,应用层就可以通过解耦来保持独立的核心业务逻辑。当数据库变更时,我们只需要更换数据库基础服务就可以了,这样就将资源变更对应用的影响降到了最低。
DDD分层架构原则
在《实现领域驱动设计》一书中,DDD分层架构有一个重要的原则:每层只能与位于其下方的层发生耦合。
而架构根据耦合的紧密程度又可以分为两种:严格分层架构和松散分层架构。优化后的DDD分层架构模型就属于严格分层架构,任何层只能对位于其直接下方的层产生依赖。而传统的DDD分层架构则属于松散分层架构,它允许某层与其任意下方的层发生依赖。
那我们怎么选呢?建议采用严格分层架构。
在严格分层架构中,领域服务只能被应用服务调用,而应用服务只能被用户接口层调用,服务是逐层对外封装或组合的,依赖关系清晰。而在松散分层架构中,领域服务可以同时被应用层或用户接口层调用,服务的依赖关系比较复杂且难管理,甚至容易使核心业务逻辑外泄。
3种分层架构模式对比
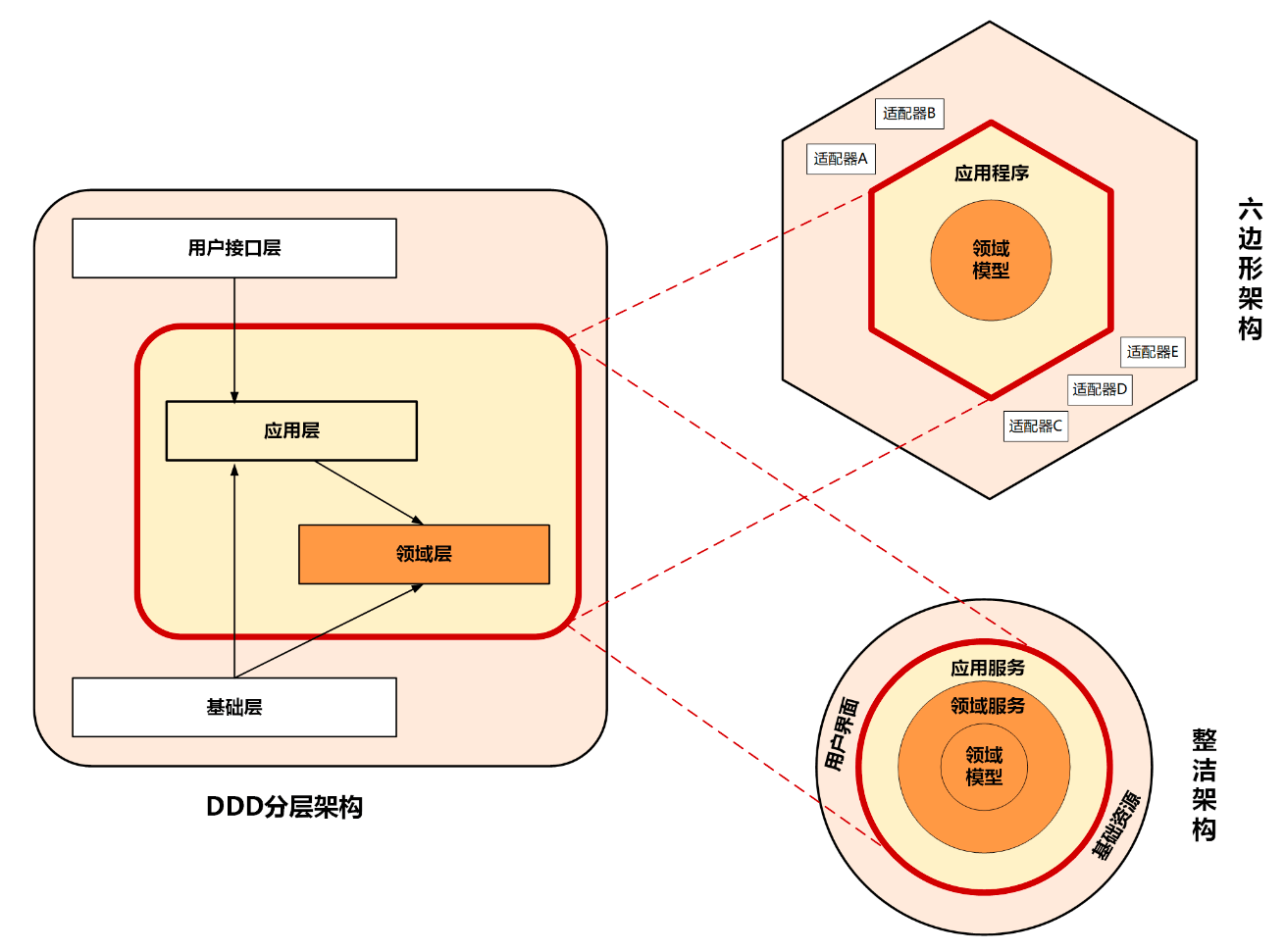
可以看到,三种模式其核心都是红色区域内,它的作用就是将核心业务逻辑与外部应用、基础资源进行隔离。
红色框内部主要实现核心业务逻辑,但核心业务逻辑也是有差异的,有的业务逻辑属于领域模型的能力,有的则属于面向用户的用例和流程编排能力。按照这种功能的差异,我们在这三种架构中划分了应用层和领域层,来承担不同的业务逻辑。
领域层实现面向领域模型,实现领域模型的核心业务逻辑,属于原子模型,它需要保持领域模型和业务逻辑的稳定,对外提供稳定的细粒度的领域服务,所以它处于架构的核心位置。
应用层实现面向用户操作相关的用例和流程,对外提供粗粒度的API服务。它就像一个齿轮一样进行前台应用和领域层的适配,接收前台需求,随时做出响应和调整,尽量避免将前台需求传导到领域层。应用层作为配速齿轮则位于前台应用和领域层之间。
可以说,这三种架构都考虑了前端需求的变与领域模型的不变。需求变幻无穷,但变化总是有矩可循的,用户体验、操作习惯、市场环境以及管理流程的变化,往往会导致界面逻辑和流程的多变。但总体来说,不管前端如何变化,在企业没有大的变革的情况下,核心领域逻辑基本不会大变,所以领域模型相对稳定,而用例和流程则会随着外部应用需求而随时调整。把握好这个规律,我们就知道该如何设计应用层和领域层了。
架构模型通过分层的方式来控制需求变化从外到里对系统的影响,从外向里受需求影响逐步减小。面向用户的前端可以快速响应外部需求进行调整和发布,灵活多变,应用层通过服务组合和编排来实现业务流程的快速适配上线,减少传导到领域层的需求,使领域层保持长期稳定。
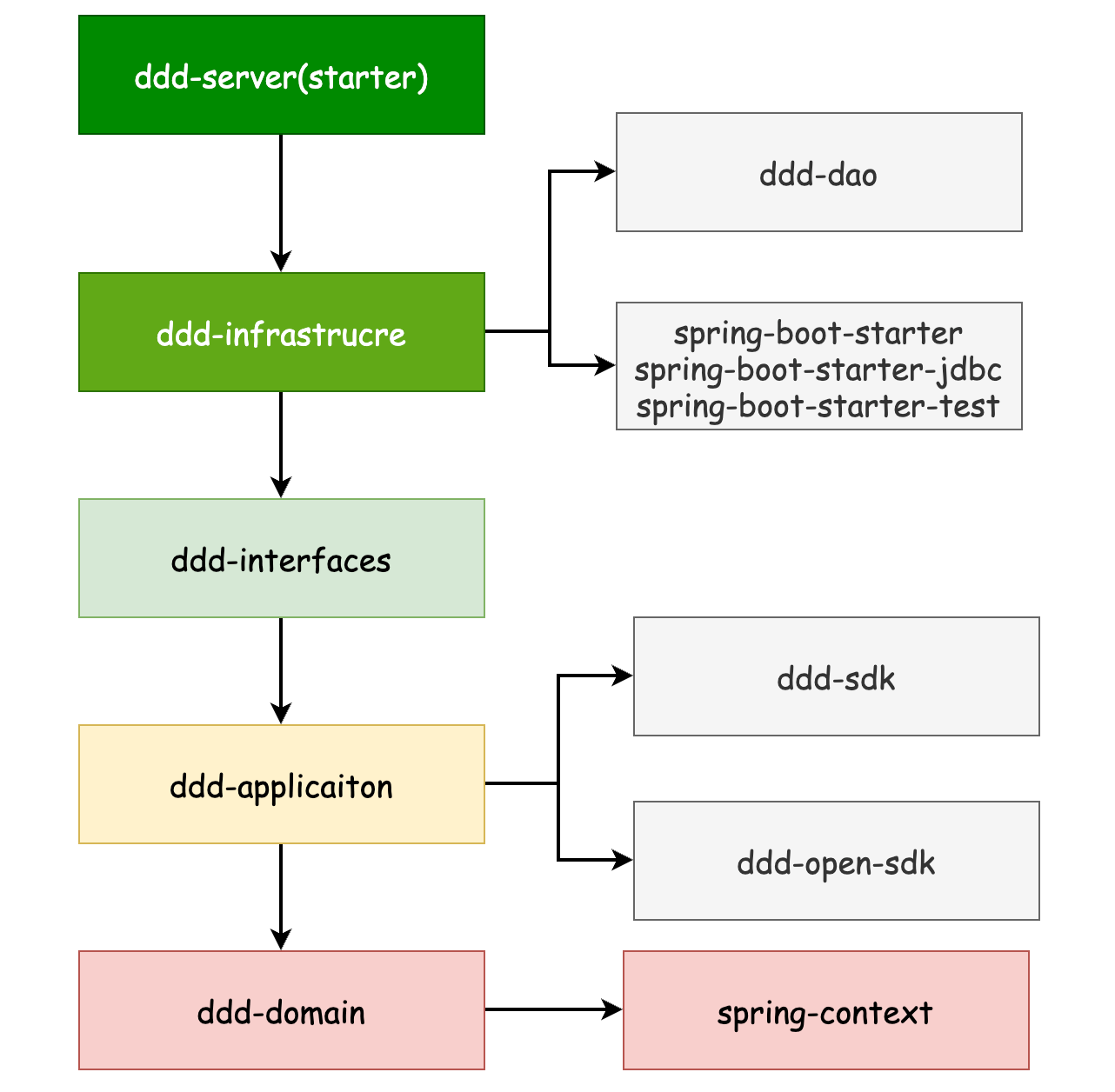
依赖倒置工程结构
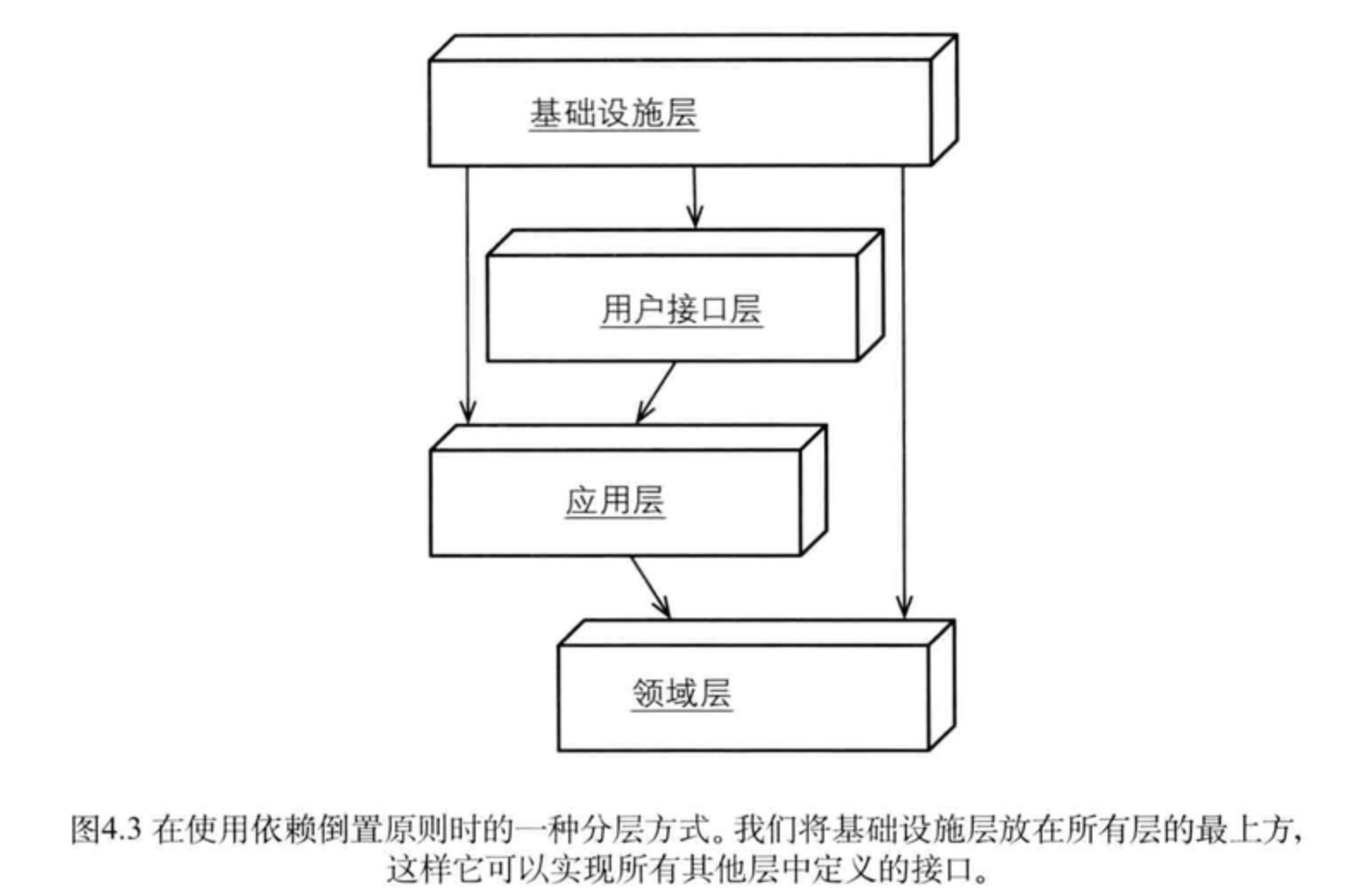
1)工程内部一般还有对外前端提供的API或对外提供的OpenAPI,所以需要有独立的SDK模块或OpenSDK模块
2)基础设施如DAO层会通过自动生成,所以采用单独的模块较好
3)基础设施收敛依赖外部的服务,缓存,消息等中间件,注:外部依赖的服务可看成是基础设施
4) 每层按模块或子域分包
通用模块依赖图
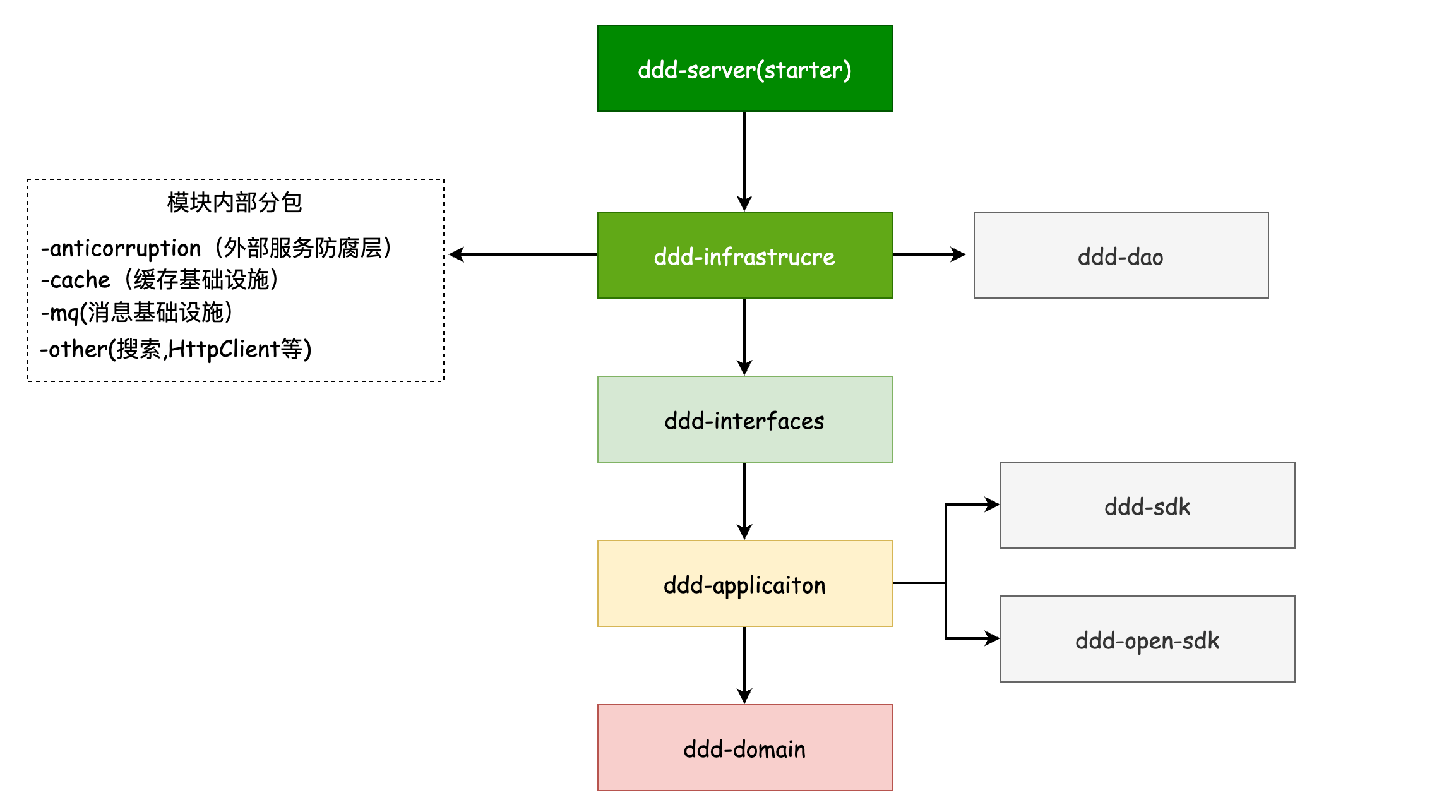
纯POJO的依赖分析树
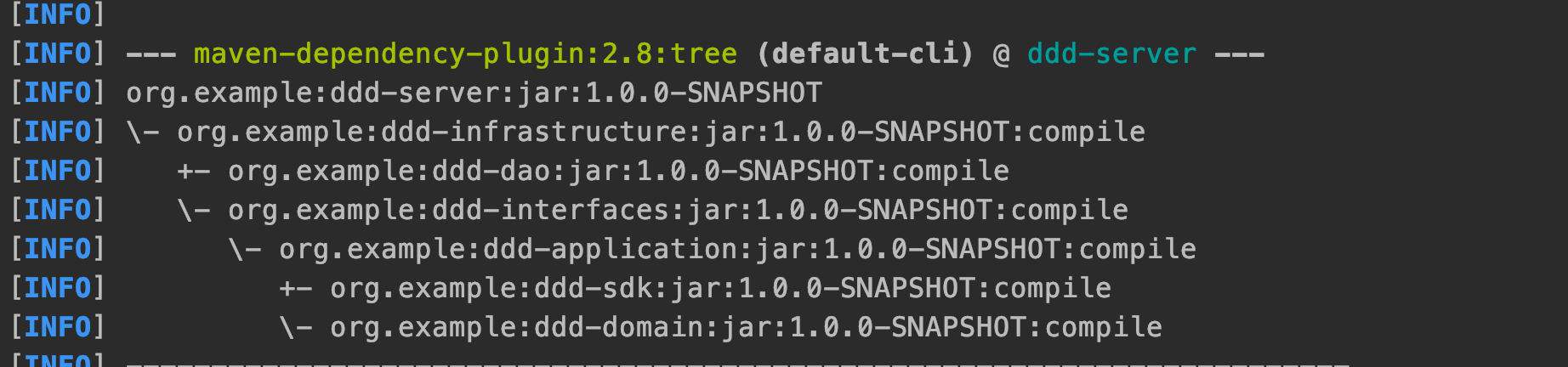
引入SpringBoot后的模块
工程父模块POM
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.2</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>org.example</groupId><artifactId>ddd-project</artifactId><version>1.0.0-SNAPSHOT</version><modules><module>ddd-server</module><module>ddd-infrastructure</module><module>ddd-application</module><module>ddd-domain</module><module>ddd-dao</module><module>ddd-sdk</module><module>ddd-interfaces</module></modules><packaging>pom</packaging><name>ddd-project</name><url>http://maven.apache.org</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencyManagement><dependencies><!-- SpringBoot --><!-- <dependency>--><!-- <groupId>org.springframework.boot</groupId>--><!-- <artifactId>spring-boot-starter-parent</artifactId>--><!-- <version>2.6.2</version>--><!-- <type>pom</type>--><!-- <scope>import</scope>--><!-- </dependency>--><dependency><groupId>org.example</groupId><artifactId>ddd-dao</artifactId><version>1.0.0-SNAPSHOT</version></dependency><dependency><groupId>org.example</groupId><artifactId>ddd-infrastructure</artifactId><version>1.0.0-SNAPSHOT</version></dependency><dependency><groupId>org.example</groupId><artifactId>ddd-application</artifactId><version>1.0.0-SNAPSHOT</version></dependency><dependency><groupId>org.example</groupId><artifactId>ddd-interfaces</artifactId><version>1.0.0-SNAPSHOT</version></dependency><dependency><groupId>org.example</groupId><artifactId>ddd-domain</artifactId><version>1.0.0-SNAPSHOT</version></dependency><dependency><groupId>org.example</groupId><artifactId>ddd-sdk</artifactId><version>1.0.0-SNAPSHOT</version></dependency><dependency><groupId>org.example</groupId><artifactId>ddd-server</artifactId><version>1.0.0-SNAPSHOT</version></dependency></dependencies></dependencyManagement><dependencies></dependencies></project>
工程模块截图
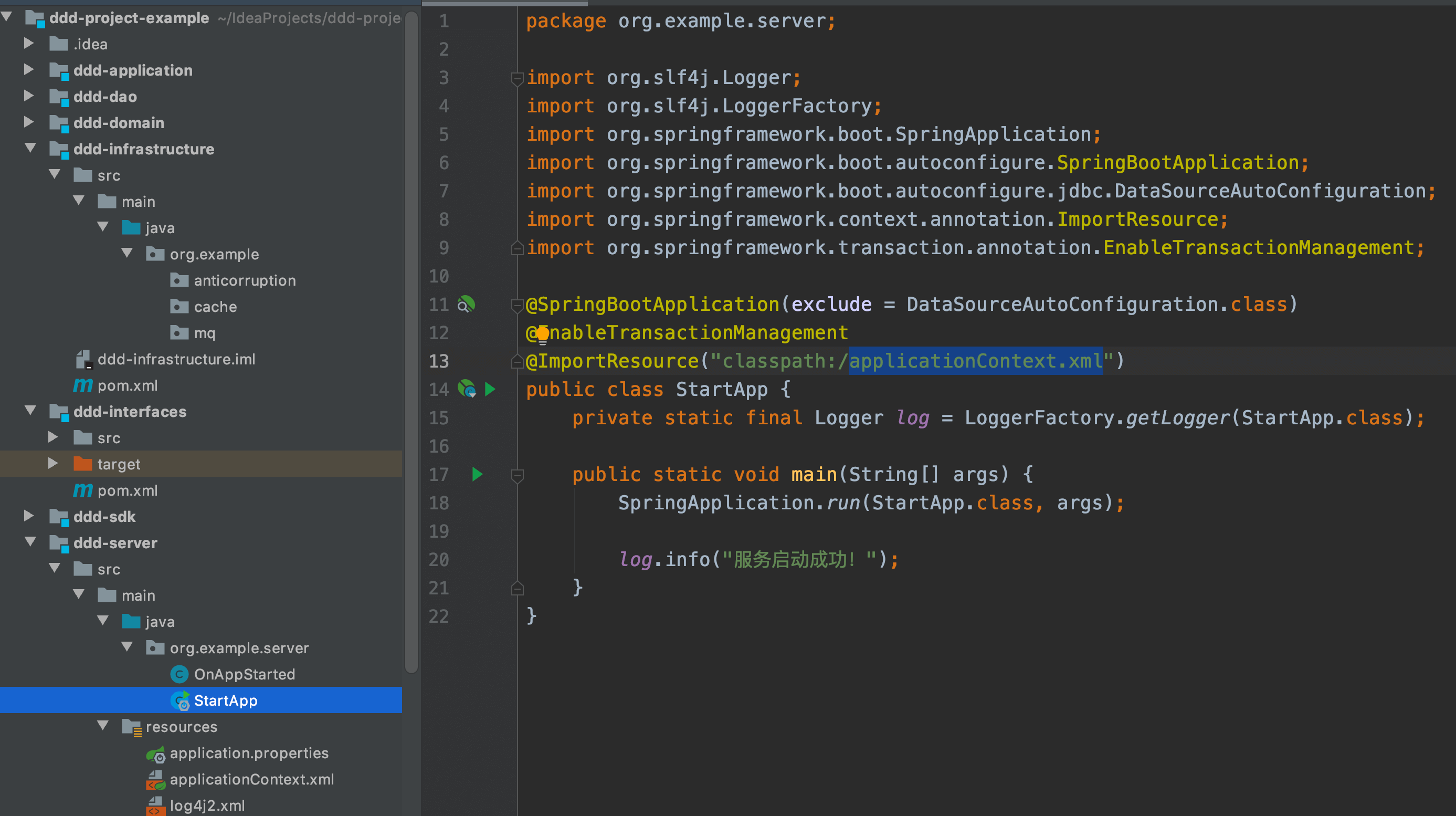
工程包结构示例
package: com.company.业务.限界上下文(模块/子域)|-- ddd-server|---- StartApp|---- OnAppStarted|-- ddd-sdk|---- constant|---- rpc|------ 模块(子域)|-------- dto|-------- service|---- event|---- utils|-- ddd-open-sdk|-- ddd-infrastructure|---- common(公共枚举/常量/切面配置/Bean配置)|------ constant|------ enums|------ utils|---- 通用公共模块(子域)的基础设施实现|----- persistence(DB的实现)|----- cache|----- cal|----- mq|---- 模块1或领域模型的的基础设施实现|------- persistence(DB的实现)|------- cache|------- mq(producer)|------- acl(防腐层实现)|------- search(搜索)|---- 模块2(或领域模型)的基础设施实现|-- ddd-dao|---- 通用模块或子域的DAO实现|------ criteria (DAO查询条件)|------ dao(DAO)|------ domain(数据库表对象)|------ mappter(数据库表对象Mappter)|---- 业务模块1DAO实现|-- ddd-interfaces|---- thrift(rpc)|---- mq|---- schedule|---- web(http)|---- cli(命令行)|---- other(其他)|-- ddd-application|---- 模块1(子域)|------ command|------ query|------ converter|------ ApplicationService|---- 模块2(子域)|-- ddd-domain|---- 模块1(子域)|------ model|------ factory|------ event(领域事件)|------ service(领域服务)|------ repository|-------- acl(防腐层接口,在基础设施中实现)|-------- extpoint(领域扩展点)|-------- search|---- 模块2(子域)
基于业务的分包
参考来源:https://insights.thoughtworks.cn/backend-development-ddd/
所谓基于业务分包即通过软件所实现的业务功能进行模块化划分,而不是从技术的角度划分(比如首先划分出service和infrastruture等包)。在DDD的战略设计中,我们关注于从一个宏观的视角俯视整个软件系统,然后通过一定的原则对系统进行子域和限界上下文的划分。在战术实践中,我们也通过类似的提纲挈领的方法进行整体的代码结构的规划,所采用的原则依然逃离不了“内聚性”和“职责分离”等基本原则。此时,首先映入眼帘的便是软件的分包。
在DDD中,聚合根(下文会讲到)是主要业务逻辑的承载体,也是“内聚性”原则的典型代表,因此通常的做法便是基于聚合根进行顶层包的划分。在示例电商项目中,有两个聚合根对象Order和Product,分别创建order包和product包,然后在各自的顶层包下再根据代码结构的复杂程度划分子包,比如对于product包:
├── order│ ├── OrderApplicationService.java│ ├── OrderController.java│ ├── OrderNotFoundException.java│ ├── OrderRepository.java│ ├── OrderService.java│ └── model│ ├── Order.java│ ├── OrderFactory.java│ ├── OrderId.java│ ├── OrderItem.java│ └── OrderStatus.java
可以看到,ProductRepository和ProductController等多数类都直接放在了product包下,而没有单独分包;但是展现类ProductSummaryRepresentation却做了单独分包。这里的原则是:在所有类已经被内聚在了product包下的情况下,如果代码结构足够的简单,那么没有必要再次进行子包的划分,ProductRepository和ProductController便是这种情况;而如果多个类需要做再次的内聚,那么需要另行分包,比如通过REST API接口返回Product数据时,代码中涉及到了两个对象ProductRepresentationService和ProductSummaryRepresentation,这两个对象是紧密关联的,因此将他们放在representation子包下。而对于更加复杂的Order,分包如下:
├── order│ ├── OrderApplicationService.java│ ├── OrderController.java│ ├── OrderPaymentProxy.java│ ├── OrderPaymentService.java│ ├── OrderRepository.java│ ├── command│ │ ├── ChangeAddressDetailCommand.java│ │ ├── CreateOrderCommand.java│ │ ├── OrderItemCommand.java│ │ ├── PayOrderCommand.java│ │ └── UpdateProductCountCommand.java│ ├── exception│ │ ├── OrderCannotBeModifiedException.java│ │ ├── OrderNotFoundException.java│ │ ├── PaidPriceNotSameWithOrderPriceException.java│ │ └── ProductNotInOrderException.java│ ├── model│ │ ├── Order.java│ │ ├── OrderFactory.java│ │ ├── OrderId.java│ │ ├── OrderIdGenerator.java│ │ ├── OrderItem.java│ │ └── OrderStatus.java│ └── representation│ ├── OrderItemRepresentation.java│ ├── OrderRepresentation.java│ └── OrderRepresentationService.java
可以看到,我们专门创建了一个model包用于放置所有与Order聚合根相关的领域对象;另外,基于同类型相聚原则,创建command包和exception包分别用于放置请求类和异常类。

若有收获,就点个赞吧
0 人点赞
