概述
Each unit should have only limited knowledge about other units: only units “closely” related to the current unit. Or: Each unit should only talk to its friends; Don’t talk to strangers.
每个模块(unit)只应该了解那些与它关系密切的模块(units: only units “closely” related to the current unit)的有限知识(knowledge)。或者说,每个模块只和自己的朋友“说话”(talk),不和陌生人“说话”(talk)。
不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口(也就是定义中的“有限知识”)。
1. 如何理解“高内聚、松耦合”?
“高内聚、松耦合”是一个非常重要的设计思想,能够有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。“高内聚”用来指导类本身的设计,“松耦合”用来指导类与类之间依赖关系的设计。
所谓高内聚,就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中。所谓松耦合指的是,在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动也不会或者很少导致依赖类的代码改动。
2. 如何理解“迪米特法则”?
不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。迪米特法则是希望减少类之间的耦合,让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少
“内聚”和“耦合”之间的关系
前面也提到,“高内聚”有助于“松耦合”,同理,“低内聚”也会导致“紧耦合”。关于这一点,我画了一张对比图来解释。图中左边部分的代码结构是“高内聚、松耦合”;右边部分正好相反,是“低内聚、紧耦合”。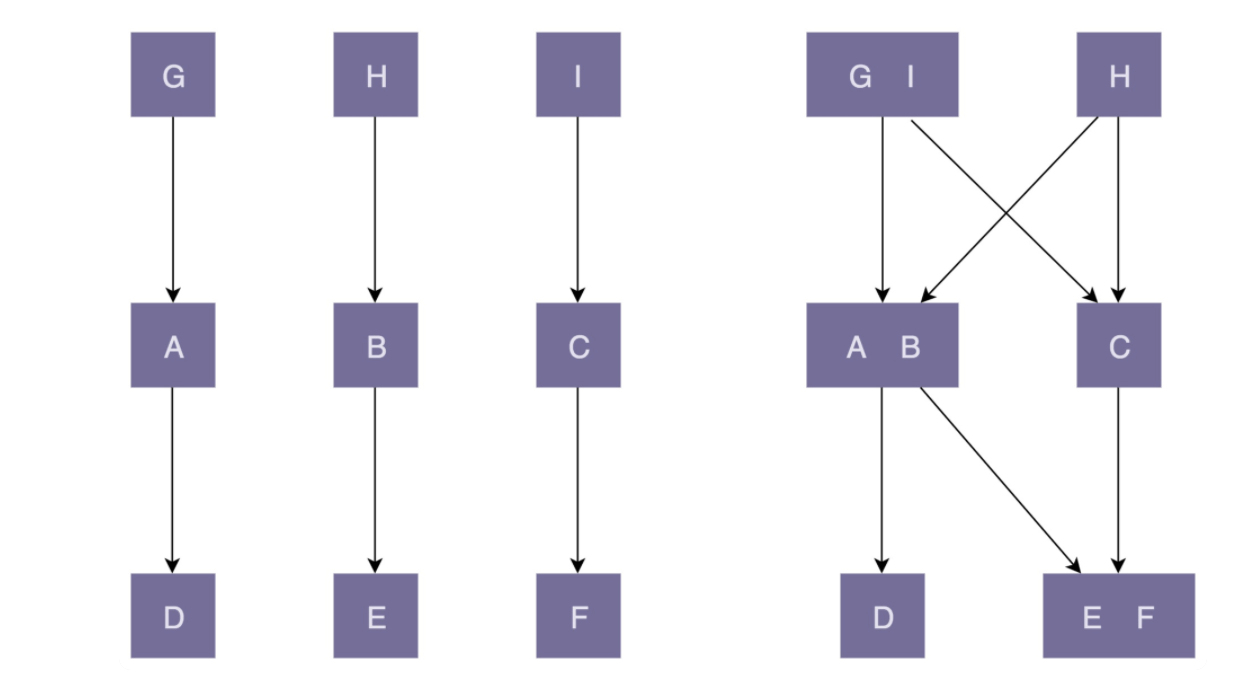
(A,B,C分别表示不同的功能,方框表示该功能放到一个类里)
图中左边部分的代码设计中,类的粒度比较小,每个类的职责都比较单一。相近的功能都放到了一个类中,不相近的功能被分割到了多个类中。这样类更加独立,代码的内聚性更好。因为职责单一,所以每个类被依赖的类就会比较少,代码低耦合。一个类的修改,只会影响到一个依赖类的代码改动。我们只需要测试这一个依赖类是否还能正常工作就行了。
图中右边部分的代码设计中,类粒度比较大,低内聚,功能大而全,不相近的功能放到了一个类中。这就导致很多其他类都依赖这个类。当我们修改这个类的某一个功能代码的时候,会影响依赖它的多个类。我们需要测试这三个依赖类,是否还能正常工作。这也就是所谓的“牵一发而动全身”。除此之外,从图中我们也可以看出,高内聚、低耦合的代码结构更加简单、清晰,相应地,在可维护性和可读性上确实要好很多。

若有收获,就点个赞吧
0 人点赞
