从最基本的层面上看,数据库只需要做两件事:数据保存,数据查询,即数据的读写,数据库一般通过存储引擎来实现,目前流行的两大类存储引擎家族:
- 日志结构的存储引擎(log-structured)
- 面向页的存储引擎(B-Tree)
为了高效的查找数据库中特定Key的值,需要新的数据结构:索引
哈希索引
先把key先写入到文件中,然后再把Key映射到文件的字节偏移量,并把记录保存到内存中的Hashmap中。读取时根据key找偏移量的位置,最后通过指定偏移量读取key的长度,即可读取key的真实内容。 如果写入较大文件,则可以拆分为多个段文件。Bitcask采用了这种算法模型。
哈希索引缺陷为:数据量太大会导致内存吃不下,索引量巨大,需要大量的随机IO,且区间查询不友好。
SSTables和LSM-Tree
每个日志结构的存储端都是一组Key-Value的序列,写入时按照Key的顺序排序,这种格式成为排序字符串表,简称SSTable,他只允许追加式更新和删除过时的文件,如BitCask,SSTables, LSM-tree, LevelDB, Cassandra, Hbase, Lucene等属于此类。
追加写日志优点:
- 追加和分段合并是顺序写,比随机写快很多
- 对于并发和崩溃恢复简单得多,不必担心部分旧值和新值混杂在一起的文件
- 合并旧段可以避免随着时间推移数据文件出现碎片化问题
如何构建和维护SSTables?(LSM-Tree)
- 写入时,将其添加到内存中的平衡树数据结构(如红黑树),这个内存树有时被称为内存表(memtable)
- 当内存表大于某个阈值时,将其作为SSTable文件写入磁盘
- 为了提供读取请求,首先尝试在内存表中找到关键字,然后在最近的磁盘段中,然后在下一个较旧的段中找到该关键字
- 后台运行合并和压缩过程以组合段文件并丢弃覆盖或删除的值
B-Tree:始见于1970年,关系型数据库的标准索引实现,经受了长久时间考验。
B-Tree将数据库分成固定大小的块(block)或页(page)(一般4KB),页是内部读写最小单元,这种设计更接近底层硬件。
对比B-Tree和LSM-Tree:根据经验,LSM-Tree通常对于写入较快,B-Tree对读取更快
LSM-Tree优点:LSM树通常能够比B树支持更高的写入吞吐量;
LSM-Tree缺点:压缩过程(compaction)会影响正在进行的读写操作,磁盘有限带宽;压缩的另一个问题出现在高写入吞吐量:磁盘的有限写入带宽需要在初始写入(记录和刷新内存表到磁盘)和在后台运行的压缩线程之间共享。写入空数据库时,可以使用全磁盘带宽进行初始写入,但数据库越大,压缩所需的磁盘带宽就越多。
由于反复压缩和合并SSTables,日志结构索引也会重写数据。这种影响 —— 在数据库的生命周期中写入数据库导致对磁盘的多次写入 —— 被称为写放大(write amplification)。需要特别注意的是固态硬盘,固态硬盘的闪存寿命在覆写有限次数后就会耗尽。
B树的一个优点是每个键只存在于索引中的一个位置,而日志结构化的存储引擎可能在不同的段中有相同键的多个副本。这个方面使得B树在想要提供强大的事务语义的数据库中很有吸引力:在许多关系数据库中,事务隔离是通过在键范围上使用锁来实现的。
B树在数据库体系结构中是非常根深蒂固的,为许多工作负载提供始终如一的良好性能,所以它们不可能很快就会消失。在新的数据存储中,日志结构化索引变得越来越流行。没有快速和容易的规则来确定哪种类型的存储引擎对你的场景更好,所以值得进行一些经验上的测试。
OLTP与OLAP
针对事务处理的OLTP,存储引擎有两大流派:日志结构流派和原地更新流派。OLTP系统通常面向用户,请求查询中磁盘寻道时间往往是瓶颈;
针对数据分析的OLAP,需要短时间内扫描数百万条记录,磁盘带宽通常是瓶颈,面向列的存储对于这种工作负载成为日益流行的解决方案(列式存储(Column-Oriented))
列式存储
不要将每一行的所有值存在一起,而是将每列中的所有值存在一起。如果每个列存在一个单独的文件中,查询只需要读取和解析在该查询中使用的那些列。这样可以节省大量的过滤工作。见下图:按列存储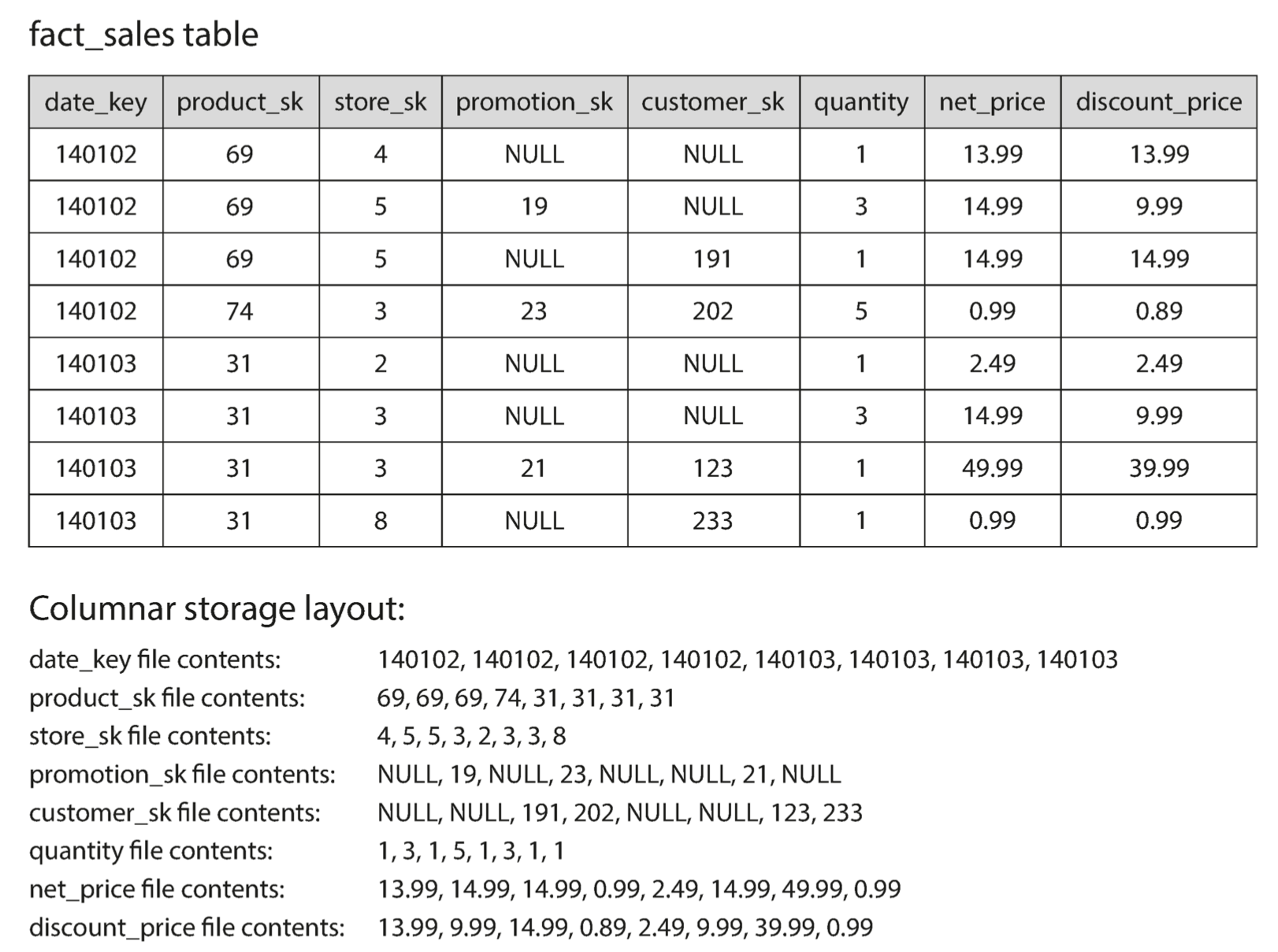
如果列的内容是枚举型,还可以做压缩存储。底层可通过位图来实现。

若有收获,就点个赞吧
0 人点赞
