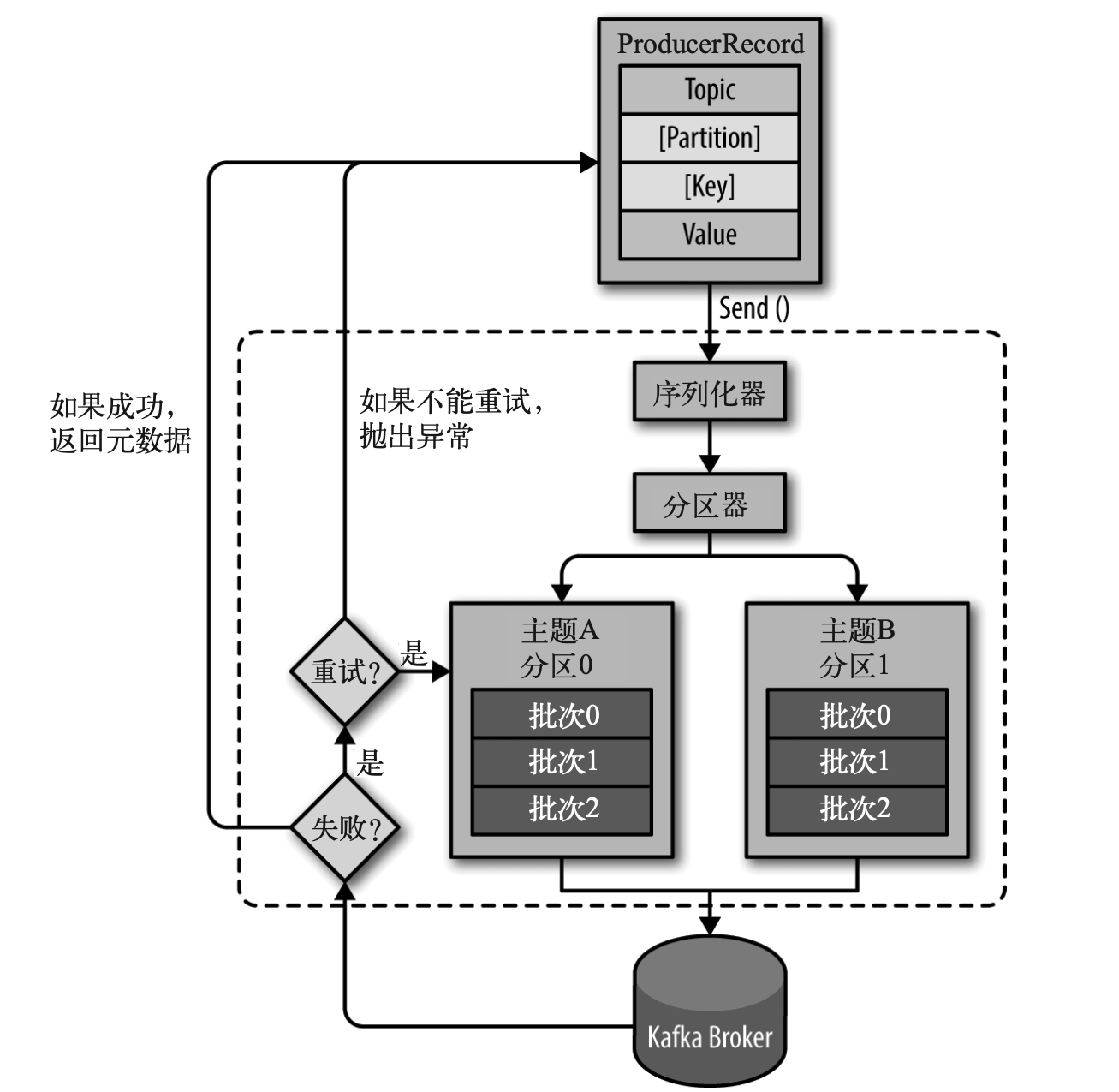
生产者组件图
摘要
Kafka定义了一个分区策略接口, 通过具体的实现策略来指定消息发送的分区。
public interface Partitioner extends Configurable, Closeable {/*** Compute the partition for the given record.** @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes The serialized key to partition on( or null if no key)* @param value The value to partition on or null* @param valueBytes The serialized value to partition on or null* @param cluster The current cluster metadata*/public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);/*** This is called when partitioner is closed.*/public void close();}
Kafka内置了多种分区策略,同时也支持自定义分区策略,通过实现Partitioner接口,并在配置中指定partitioner.class 属性等于自定义策略Class的全限定名称。
默认策略(粘性分区策略+随机)
Kafka2.7.0版本里,默认策略命名为: DefaultPartitioner 主要逻辑为:
- 如果消息记录里指定了分区,则使用
- 如果消息记录里未指定分区,但是包含Key, 则基于Key做Hash,然后取hash值与分区数量取模
- 如果消息里未指定分区,且Key为空,则采用粘性分区策略(消息记录对应的消息批次满了后,通过随机策略更换新的分区)
代码里通过ThreadLocalRandom.current().nextInt()来获取随机数,然后转为正数后与分区数量取模,
所以这里明显就是采用的随机算法!
if (availablePartitions.size() < 1) {Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = random % partitions.size();} else if (availablePartitions.size() == 1) {newPart = availablePartitions.get(0).partition();} else {while (newPart == null || newPart.equals(oldPart)) {Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = availablePartitions.get(random % availablePartitions.size()).partition();}}
随机策略
所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示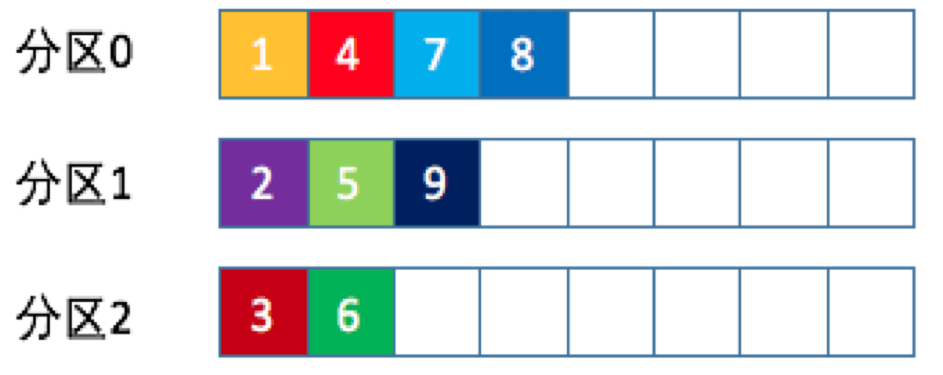
策略实现
未指定Key,委托到内部的StickyPartitionCache 来实现分区。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {if (keyBytes == null) {return stickyPartitionCache.partition(topic, cluster);}// hash the keyBytes to choose a partitionreturn Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}
轮询策略(RoundRobinPartitioner)
即顺序分配。比如一个主题下有3个分区,那么第一条消息被发送到分区0,第二条被发送到分区1,第三条被发送到分区2,以此类推。当生产第4条消息时又会重新开始,即将其分配到分区0,就像下面这张图展示的那样.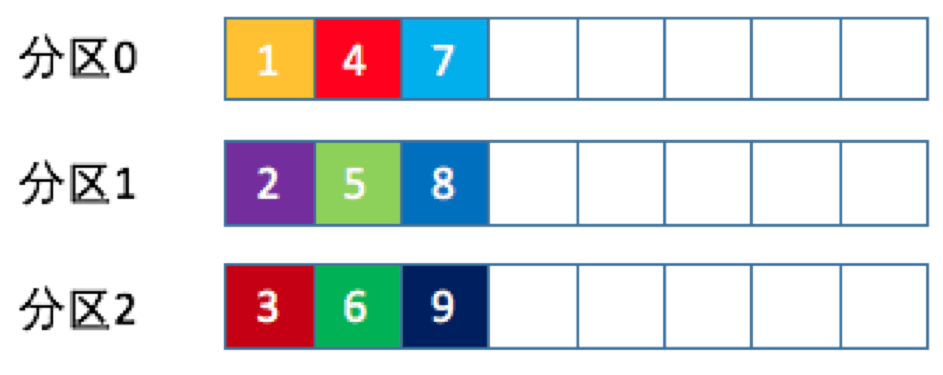
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一.
策略实现
关键逻辑:内部在内存里维持了一个Topic到AtomicInteger的ConcurrentHashMap, 计算分区时,通过AtomicInteger.getAndIncrement() 与主题分区数取模。如果AomicInteger自增溢出后,通过与Integer.MAX_VALUE取与,转换为整数, 继续与分区数取模,得到分区的轮询值
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();int nextValue = nextValue(topic);List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (!availablePartitions.isEmpty()) {int part = Utils.toPositive(nextValue) % availablePartitions.size();return availablePartitions.get(part).partition();} else {// no partitions are available, give a non-available partitionreturn Utils.toPositive(nextValue) % numPartitions;}}
轮询验证
/*** @author xiele on 2021/2/19*/public class RoundRobin {private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();private static final String topic = "mockTopic";private static final int partitionNums = 10;public static void main(String[] args) {RoundRobin rr = new RoundRobin();rr.modForPartitionsWhenOverflow();}/**Case1: AtomicInteger在正数范围类自增,与分区数取模* 验证轮询取模算法nextValue=0, mod=0nextValue=1, mod=1nextValue=2, mod=2nextValue=3, mod=3nextValue=4, mod=4nextValue=5, mod=5nextValue=6, mod=6nextValue=7, mod=7nextValue=8, mod=8nextValue=9, mod=9nextValue=10, mod=0nextValue=11, mod=1...nextValue=97, mod=7nextValue=98, mod=8nextValue=99, mod=9*/private void modForPartitions() {int nextValue;while ((nextValue = nextValue(topic)) < 100) {int mod = nextValue % partitionNums;System.out.println("nextValue=" + nextValue + ", mod=" + mod);}}/**Case2: AtomicInteger自增到异常-转为正式继续自增,与分区数取模* 验证内存里的AtomicInteger轮询溢出的情况nextValue=2147483647,newNextValue=2147483647,mod=7nextValue=-2147483648,newNextValue=0,mod=0nextValue=-2147483647,newNextValue=1,mod=1nextValue=-2147483646,newNextValue=2,mod=2nextValue=-2147483645,newNextValue=3,mod=3nextValue=-2147483644,newNextValue=4,mod=4nextValue=-2147483643,newNextValue=5,mod=5nextValue=-2147483642,newNextValue=6,mod=6nextValue=-2147483641,newNextValue=7,mod=7nextValue=-2147483640,newNextValue=8,mod=8nextValue=-2147483639,newNextValue=9,mod=9nextValue=-2147483638,newNextValue=10,mod=0nextValue=-2147483637,newNextValue=11,mod=1*/private void modForPartitionsWhenOverflow() {AtomicInteger count = new AtomicInteger(Integer.MAX_VALUE);int i = 0;while (i++ < 100) {int nextValue = count.getAndIncrement();int newNextValue = Utils.toPositive(nextValue);System.out.println("nextValue=" + nextValue + ",newNextValue=" + newNextValue + ",mod=" + (newNextValue % partitionNums));}}private int nextValue(String topic) {AtomicInteger counter = topicCounterMap.computeIfAbsent(topic, k -> new AtomicInteger(0));return counter.getAndIncrement();}}
消息Key保序策略
也称Key-ordering策略。Kafka允许为每条消息定义消息键,简称为Key。这个Key的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务ID等;也可以用来表征消息元数据。特别是在Kafka不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进Key里面的。一旦消息被定义了Key,那么你就可以保证同一个Key的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略,如下图所示。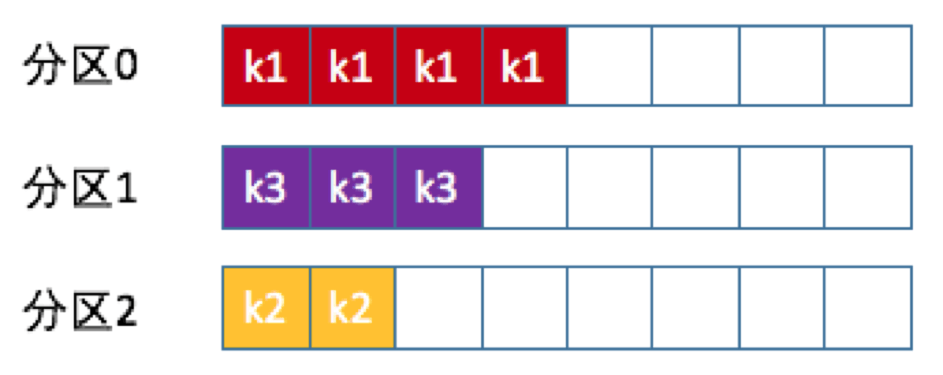
如相同类型的Key, 相关规则的Key, 位于同一分区. Kafka默认的分区策略中也包含了基于Key Hash的策略。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {// hash the keyBytes to choose a partitionreturn Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}
其他/自定义
基于实际场景来抉择,例如地理位置,商家信息,大客户。
以下示例为某个大客户的数据单独指定固定的分区,避免与其他耦合在一起,隔离数据,提升处理性能。
public class BananaPartitioner implements Partitioner {public void configure(Map<String, ?> configs) {} ➊public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if ((keyBytes == null) || (!(key instanceOf String)))throw new InvalidRecordException("We expect all messages to have customer name as key")if (((String) key).equals("Banana"))return numPartitions; // Banana总是被分配到最后一个分区// 其他记录被散列到其他分区return (Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1)) }public void close() {}}

若有收获,就点个赞吧
0 人点赞
