概要
Kafka通过主题来定义一个逻辑队列,每个队列有多个分区,分布在不同的Broker上。每个分区都有一份日志数据(目录文件+日志文件)。Kafka为每个分区的日志数据分配了1到N个副本,所以副本其本质就是只能追加写消息的提交日志。分区副本的数据都是一致的(在同一时刻,副本之间并非完全一样),只不过副本在逻辑角色上分为Leader副本,与Follower副本。Kafka在分区创建后或Broker启动时,会在所有Broker中选取分区的Leader副本,与Follower副本,并把选举结果写入到ZooKeeper中。
副本之间是「一主多从」的关系,Leader副本负责处理读写请求,Follower副本只负责与Leader副本的消息同步。
这就是说,任何一个Follower副本都不能响应消费者和生产者的读写请求。所有的请求都必须由Leader副本来处理,或者说,所有的读写请求都必须发往Leader副本所在的Broker,由该Broker负责处理。Follower副本不处理客户端请求,它唯一的任务就是从Leader副本异步拉取消息,并写入到自己的提交日志中,从而实现与Leader副本的同步。
如图: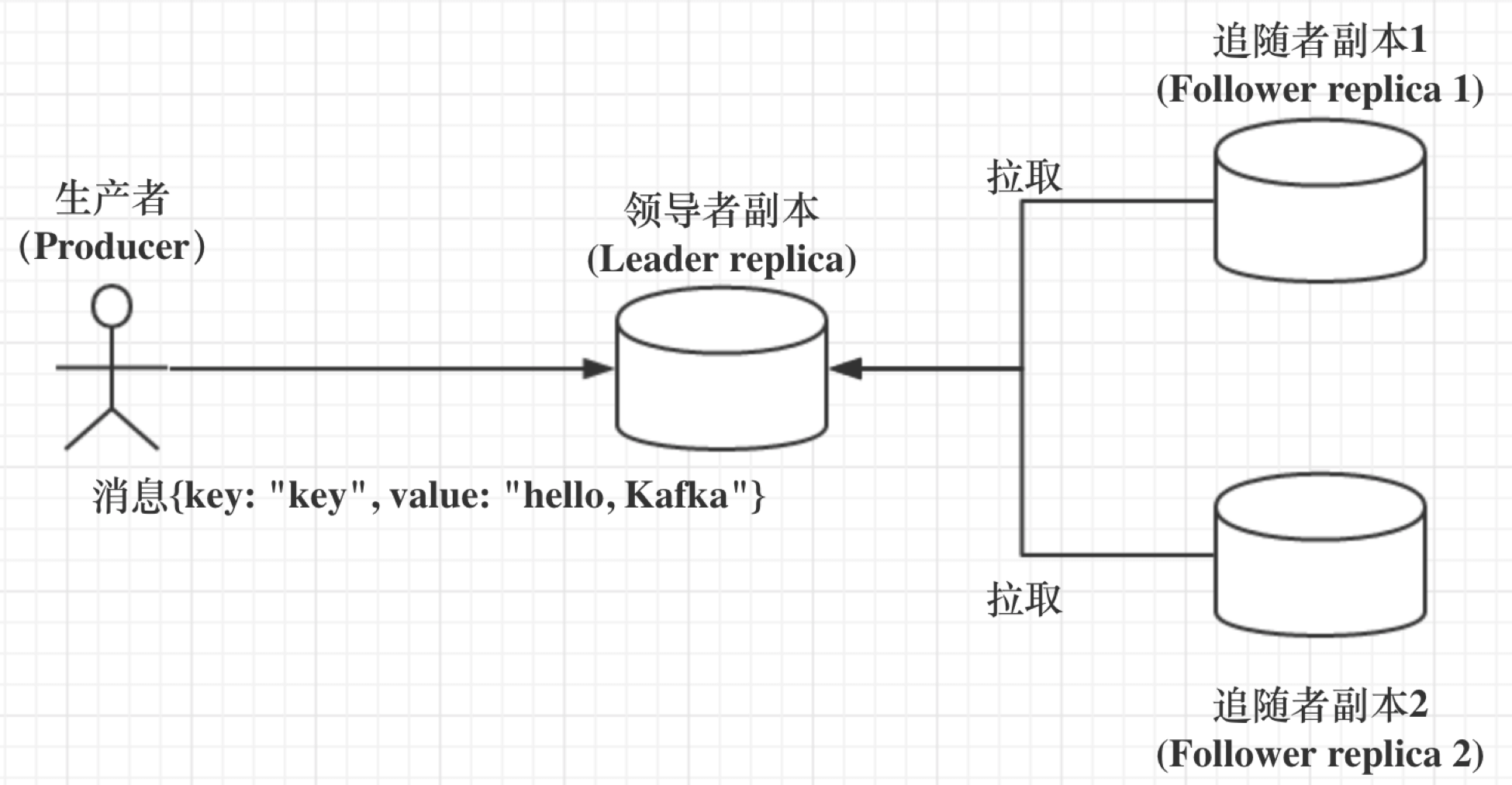
同一分区的副本处于不同的Broker中,当Leader副本出现故障时,Kafka通过控制器从Follower副本中重新选举新的Leader副本对外提供读写服务。
所以,Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个Broker失效时仍然能保证服务的可用性。
多副本架构
与其他分布式系统类似,Kafka采用多副本的机制来实现水平扩容,提供容灾能力,同时提升可用性与可靠性等。
如下图,集群有4个Broker,主题TestTopic有3个分区,分别为P0, P1, P2, 副本因子(副本个数)为3,因此每个分区有1个Leader副本与2个Follower副本,生产者与消费者只与Leader副本进行交互,Follower副本只负责拉取消息作同步。实际场景中,Follower副本中的消息相对Leader副本有一定的滞后性。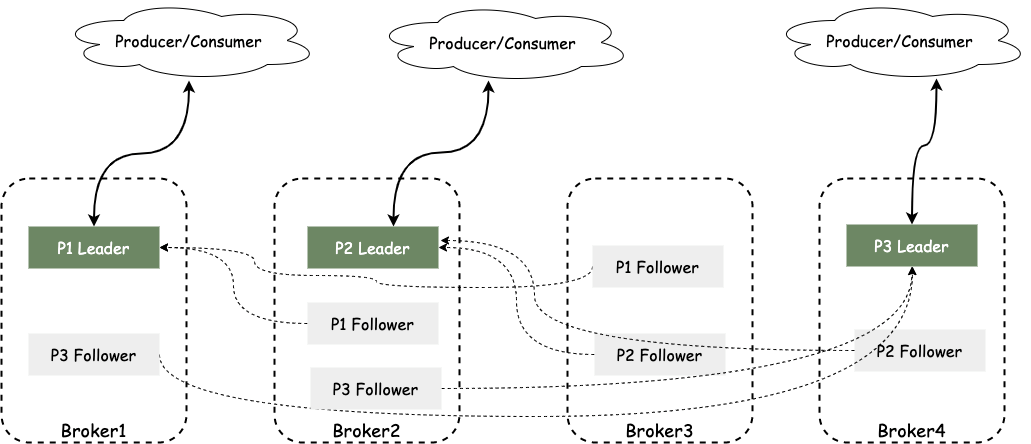
副本同步中的相关概念
AR
分区中的所有副本统称为AR,Assigned Replicas
ISR
所有与Leader副本保持一定程度同步的副本,包括Leader副本组成的集合叫ISR,In-Sync Replicas. ISR集合是AR集合的一个子集。
OSR
与Leader副本同步滞后的副本(不包括Leader副本)集合叫OSR,Out-of-Sync Replicas.
由此可见:AR = ISR + OSR,正常情况下,AR=ISR,OSR为空
默认情况下,当Leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的Leader,而OSR集合中个副本则没有机会,不过当Broker端参数unclean.leader.election.enable=true时,默认值为false, 则可以选取OSR中的副本为Leader,Kafka内部称为unclean选举,开启Unclean Leader选举可能会造成数据丢失,但好处是,它使得分区Leader副本一直存在,不至于停止对外提供服务,因此提升了高可用性。反之,禁止Unclean Leader选举的好处在于维护了数据的一致性,避免了消息丢失,但牺牲了高可用性。
这就是CAP!一个分布式系统通常只能同时满足一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)中的两个。在这个问题上,Kafka赋予用户选择C或A的权利。一般我们建议不要开启这个开关。
LogStartOffset
表示分区日志文件的起始偏移量。在Kafka中,LogStableOffset简称LSO.
LEO
LogEndOffset, 表示分区日志文件中下一条待写入消息的offset,相当于最后一条消息的offset加1.
HW
HW 即 High Watermark, 俗称高水位,它标识了一个特定的消息偏移量offset,消费者只能拉取到这个offset之前的消息。ISR中最小的LEO即为HW。
如下图,它表示一个日志文件,这个日志文件中有9条消息,第一条消息的起始偏移量为0,最后一条消息的offset为8,offset为9的消息用虚线框表示,代表下一条待写入的消息的offset. 日志文件的HW为6,表示消费者只能拉取到0到5之间的消息,表示已提交的最大偏移量。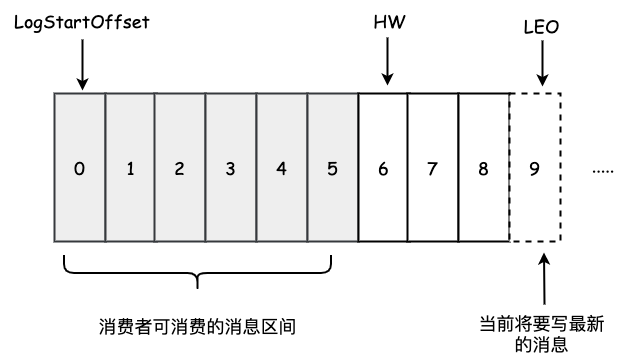
分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为整个分区的HW, 对消费者而言只能消费HW之前的消息,表示只能拉取到所有分区副本中最小的已提交的消息偏移量。
如果不取最小的LEO,那么当前Leader挂掉后,切换到其他副本时,造成读取不到消息的问题。
生产者发送的一条消息首先会被写入分区的Leader副本,然后等待ISR中的副本都同步完成后,该消息才会认为是已提交,之后才会更新HW,进而消费者才可以消费到这条消息。
注:等待ISR副本同步消息的过程,Kafka通过延时操作实现,具体见另一篇文章:Kafka服务端
LEO与HW的状态变化
假如某分区有3个副本,1个Leader, 2个Follower, 所有的副本都已写入消息0,所以分区的LEO与HW都是1. 消息1和消息2从生产者发出后先写入Leader副本,其中的LEO与HW的状态变化如下图: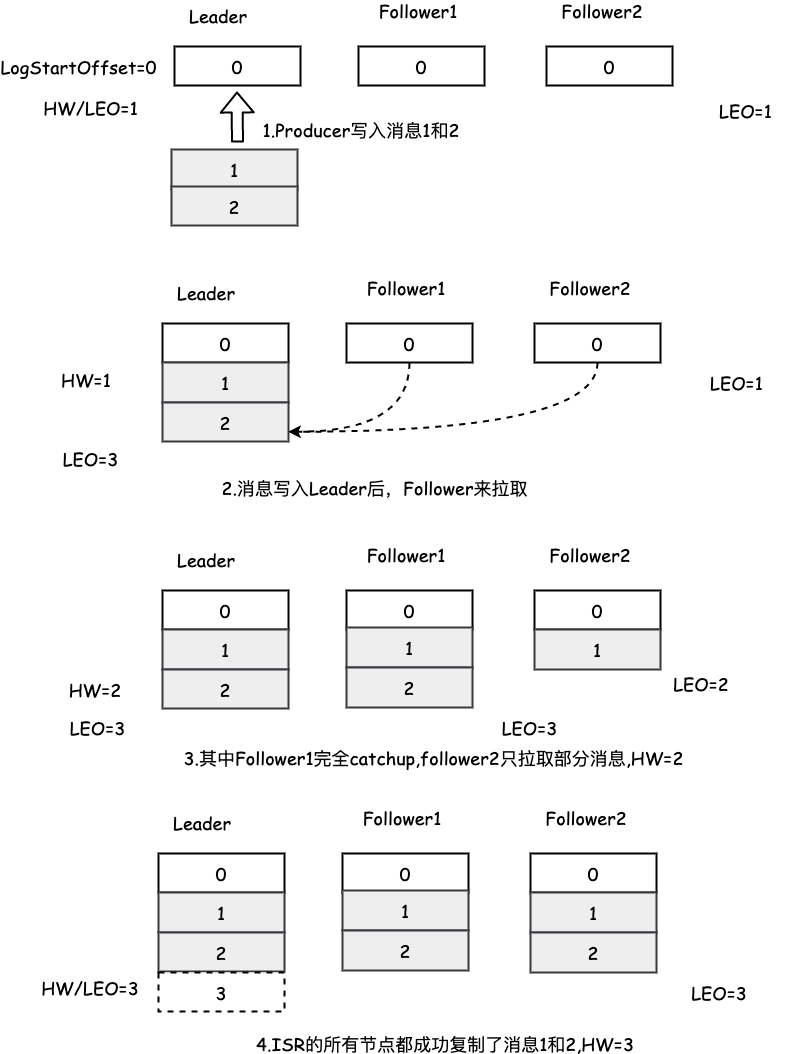
ISR的伸缩
正常情况下,ISR=AR,但是ISR中的副本可能会失效。当ISR集合中的某个Follower副本滞后Leader副本的时间超过replica.lag.time.max.ms参数指定的值 (Broker端可配置,默认10秒),则判定同步失败,则判定该Follower为失效副本,则会从ISR中剔除。
具体的原理为:当Follower副本将Leader副本的LEO之前的消息全部同步完成时,则认为该Follower已经追赶上Leader副本,此时更新该副本的**lastCaughtUpTimeMs**标识。Kafka副本管理器会启动一个副本过期检查定时任务,而这个定时任务会定期检查当前时间与副本的lastCaughtUpTimeMs的差值是否大于参数replica.lag.time.max.ms 指定的值。如果小于则认为该Follower副本处于同步中,大于则认为处于未同步中,判定为失效副本。进而更新ISR集合,见下图: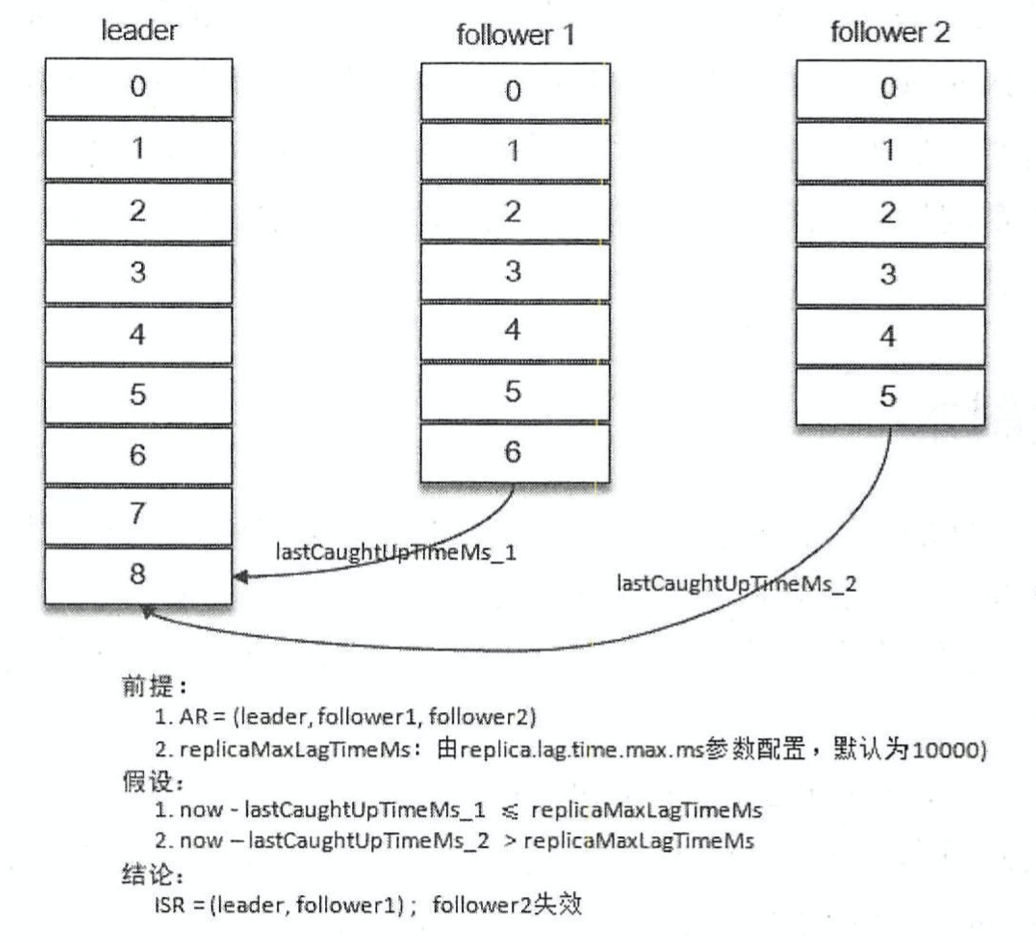
注:一般有2中情况会导致副本失效
- Follower副本进程卡主,在一段时间里没有向Leader发送FetchRequest,比如频繁的FullGC
- Follower副本同步较慢,比如I/O开销过大
总结:Kafka控制器通过副本过期检测定时任务定期检查ISR中的副本同步情况,基于lastCaughtUpTimeMs来控制ISR的缩减。同时通过isr变更检查定时任务结合zoopkeeper的通知机制来维护isr的扩充。
高水位HW与LEO的更新
高水位HW和LEO是副本对象的两个重要属性,Kafka的Leader副本与Follower副本都有HW与LEO,但Leader Broker保留了所有的副本的HW与LEO。但Leader副本的HW代表了分区的高水位,分区的高水位就是其Leader副本的高水位。
对于同一分区,Leader上的副本称为本地副本,而该分区的Follower Broker上副本称为远程副本。
Leader副本所在的Broker记录了自身的高水位与LEO,同时还记录了所有Follower的HW与LEO,Follower副本则只保留自身的HW与LEO。如下图: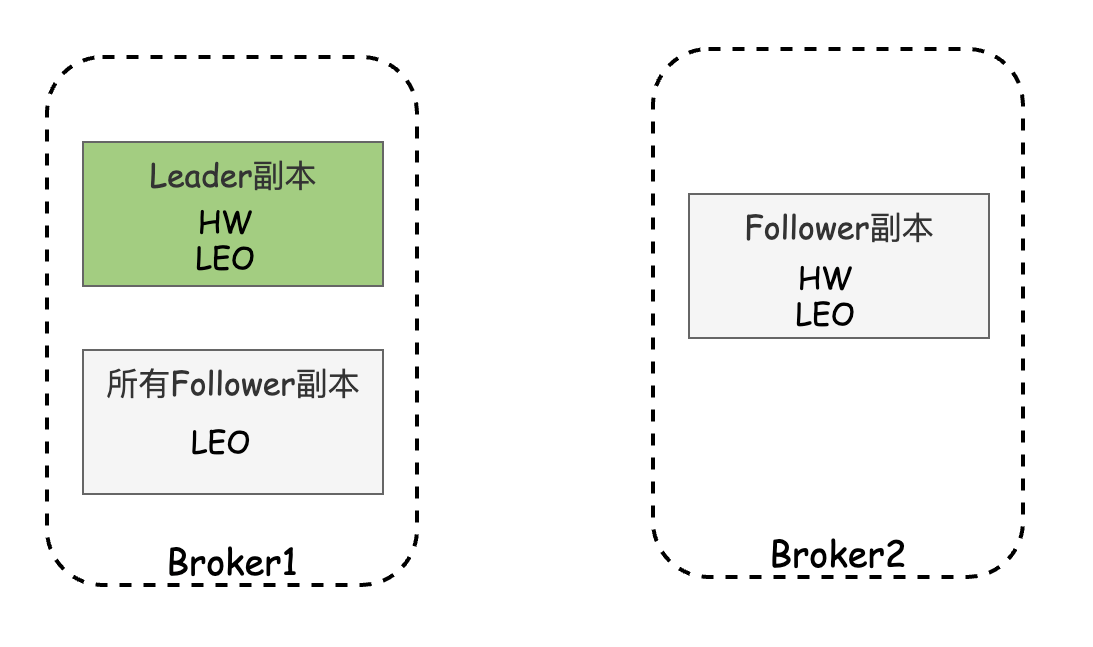
注:Follower拉取Leader消息的频率通过参数**replica.lag.time.max.ms**来控制,默认是10s。一般需要修改。
1)Leader副本收到生产者的消息后,首先先更新自身LEO与HW。
2)Follower副本向Leader副本拉取消息,在请求头中会带有自身的LEO,这个LEO信息对应的是FetchRequest 请求中的fetch_offset , Leader副本收到Follower副本的FetchRequest后,先从自己的日志文件中读取数据,然后更新Broker上的Follower副本的LEO,然后Leader取出Broker上的所有远程副本的LEO与当前自己的LEO,取最小值作为Leader的HW。
3)Follower副本的FetchRequest对应的响应为FetchResponse, Leader会把自身HW信息设置到high_watermark 字段中,Follower副本收到响应时,先写入消息到自己的日志文件里,然后更新自己的LEO。同时Follower副本还会更新自己的HW,更新算法是比较当前LEO与Leader副本传送过来的HW的值,取较小值作为自己的HW。
总结如下: Follower拉取消息时,会带上自己的LEO,Leader把Follower的带过来的LEO记下来,并取所有Follower的LEO与Leader的LEO为Leader的HW。
Leader发送响应时,会带上自己的HW,Follower会先更新自己的LEO,然后取自己的LEO与Leader发送过来的HW的最小值作为当前Follower的HW.
举个例子
初始状态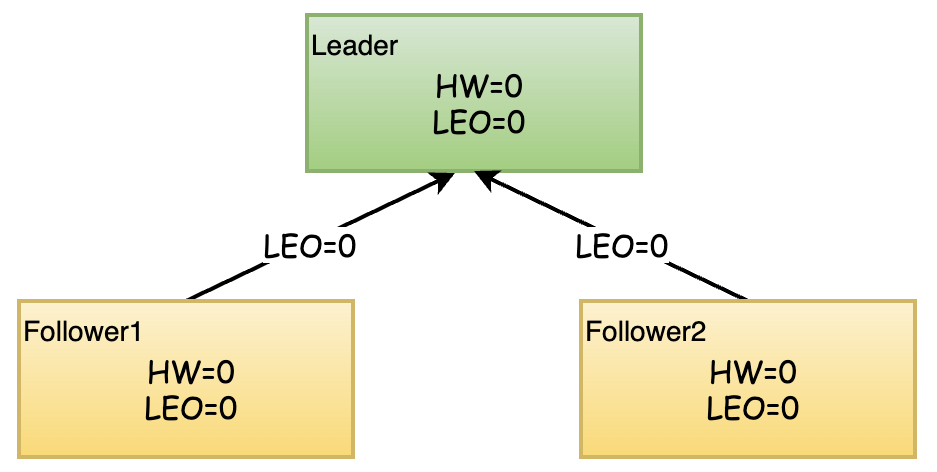
Leader收到5条消息并处理,2个Follower分别在某个时刻开始拉取消息.
Follower1拉取到3条消息,拉取到的Leader的HW为0,更新自己的LEO,更新自己的HW=Min(Leader_HW, Self_HW) = 0
Follower2拉取到4条消息,拉取到的Leader的HW为0,更新自己的LEO,更新自己的HW=Min(Leader_HW, Self_HW) = 0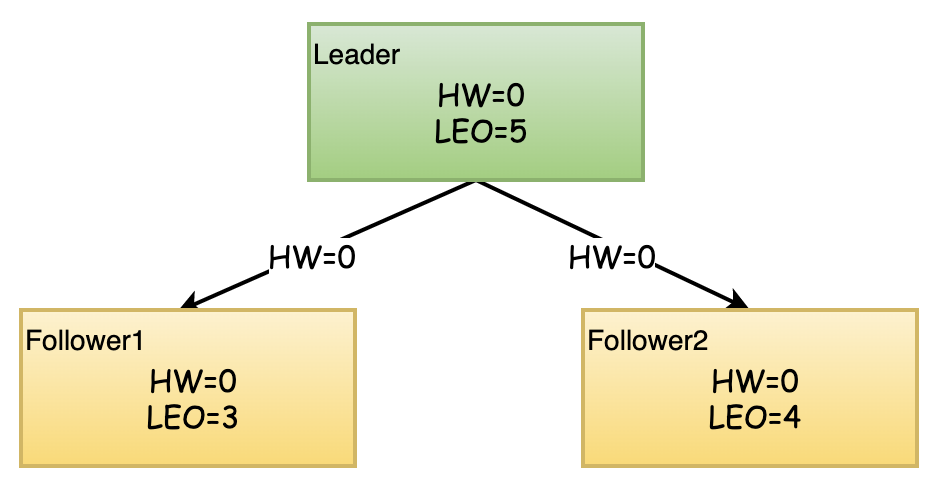
接下来Follower副本再次请求拉取Leader副本的消息,此时带上各自的LEO。由于Leader副本一直在接收消息,Follower上次拉取消息后,Leader已经写入了最新的消息,此时Leader的LEO到达了10。
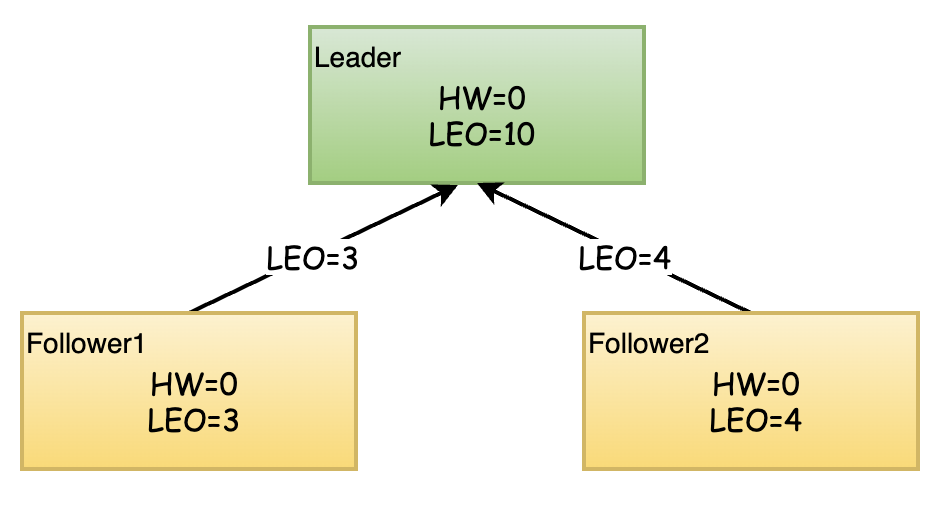
Leader在收到两个Follower的拉取请求时,先更新Leader远程副本的LEO,然后选取所有远程副本的LEO与自己的HW的最小值作为Leader新的HW, 然后把更新后的HW返回给Follower, Follower再次更新自己的HW. 此时可能把Leader的最新的消息也拉取成功,Follower更新自己的LEO为10.
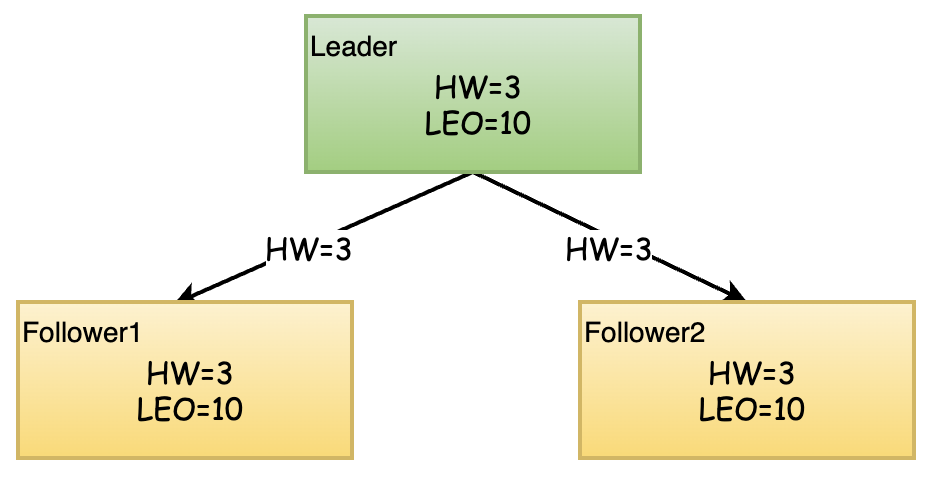
所以,在某一时刻,Leader的HW=3,也就是分区的HW为3,消费者只能拉取到的消息HW=3之前的消息
也就是说,Kafka用LEO与HW来控制不同副本间数据同步,并用来保证消息的一致性
总结
| 更新对象 | 更新时机 |
|---|---|
| Leader副本的LEO | Leader收到生产者发送的消息,写入磁盘后,更新LEO |
| Follower副本的LEO | Follower拉取Leader的消息写入自己的磁盘后,更新LEO |
| Follower副本的HW | Follower副本更新完自己的LEO后,与Leader发来的HW作比较,取最小值更新自己的HW |
| Leader的远程副本的LEO | Follower发起拉取消息的请求时,带上自己的LEO,Leader读取消息后,会用这个值更新远程副本的LEO |
| Leader副本的HW | 主要有2个时机,一是Leader副本更新自己的LEO后,二是更新完远程副本的LEO后,用自己的LEO与所有的远程副本的LEO作比较,取最小值为自己的HW |
Leader Epoch
Leader副本与Follower副本之间通过FetchRequest/FetchResponse协作完成消息的同步,但是最终同步到一致的HW时,中间存在一定的时间差。也就是说,Leader副本HW更新和Follower副本HW更新在时间上是存在错配的,这种错配很容易导致“数据丢失”或“数据不一致”问题。基于此,Kafka从0.11版本开始引入了Leader Epoch概念,来规避因高水位更新错配导致的各种不一致问题。
如下示例,在某个时刻,Follower拉取了2条消息,更新了LEO。但是拉取到的HW仍然为1(当初Leader返回的HW=1)。此时该Follower发送FetchRequest后,Leader的HW已经更新为2.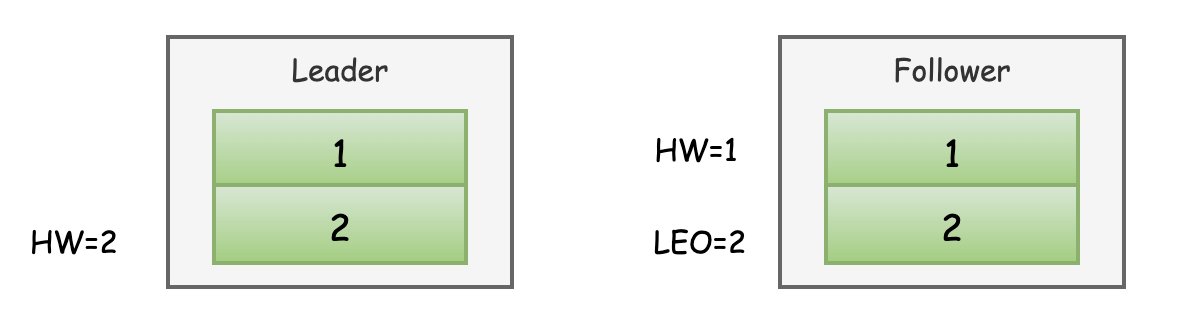
Leader还未发送响应给Follower之前,Follower宕机了。那么Follower重启之后会根据之前的HW位置(这个值会写入本地的复制点文件replication-offset-checkpoint中)进行日志截断,此时会把之前拉取的消息2删除,此时Follower中只剩下消息1,之后Follower再次向Leader发起FetchRequest请求拉取消息。
如果此时Leader再次宕机,那么Follower被选举为Leader,之前的Leader恢复后成为Follower.由于Follower副本的HW不能比Leader副本的HW高,所以还会做一次截断,依次将HW调整为1,这样消息2就丢失了。(两个副本中都没有消息2)
Leader Epoch类似于给Leader增加了一个版本号,每次截取日志时增加Leader版本号的判断,如果不匹配则截不截取日志。

若有收获,就点个赞吧
0 人点赞
