线程模型
从Kafka 0.10.1.0版本开始,KafkaConsumer就变为了双线程的设计,即用户主线程和心跳线程。
用户主线程( Fetcher Thread)就是实例化KafkaConsumer并调用poll()方法的线程,心跳线程(Heartbeat Thread)只负责定期给对应的Broker机器发送心跳请求,以标识消费者应用的存活性(liveness)。心跳线程它能将心跳频率与主线程调用KafkaConsumer.poll方法的频率分开,从而解耦真实的消息处理逻辑与消费者组成员存活性管理。
实际的消息获取逻辑依然是在用户主线程中完成的。因此,在消费消息的这个层面上,我们依然可以安全地认为KafkaConsumer是单线程的设计。
所以当单个消费者消费某分区时,无论被分配了多少个分区,都是通过一个线程来借助网络来读取消息。
单个消费者单线程消费2个分区+心跳线程通信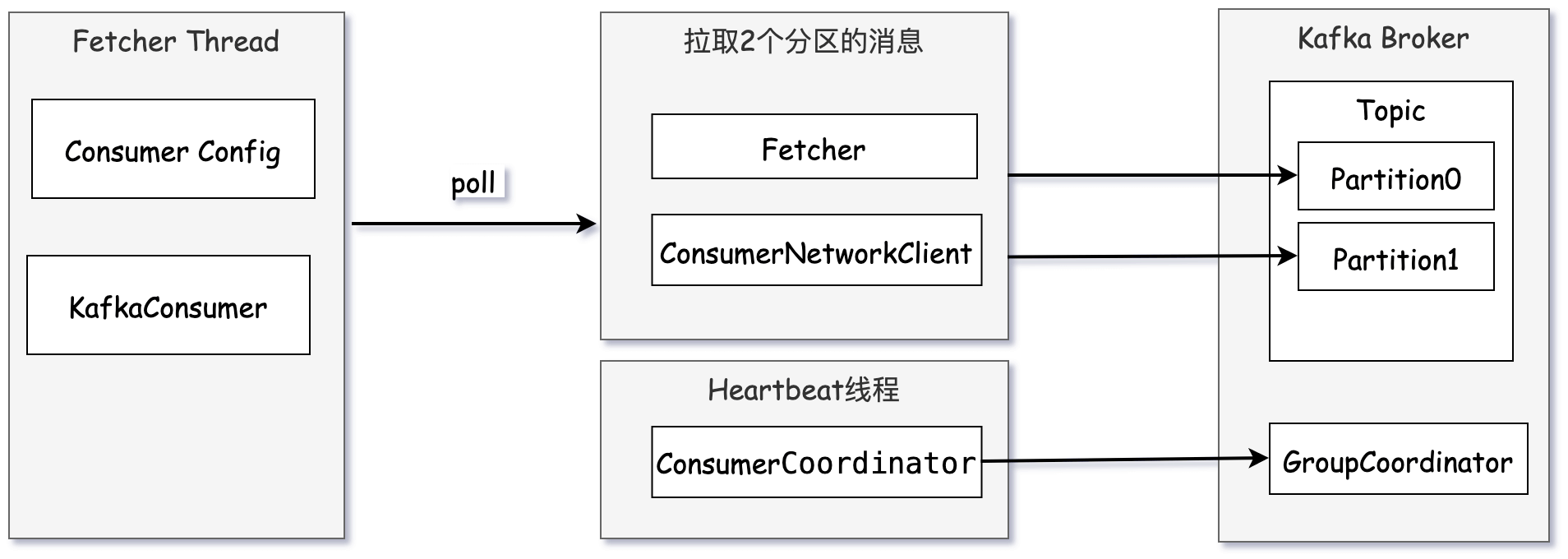
扩展到消费组层面分区消费分配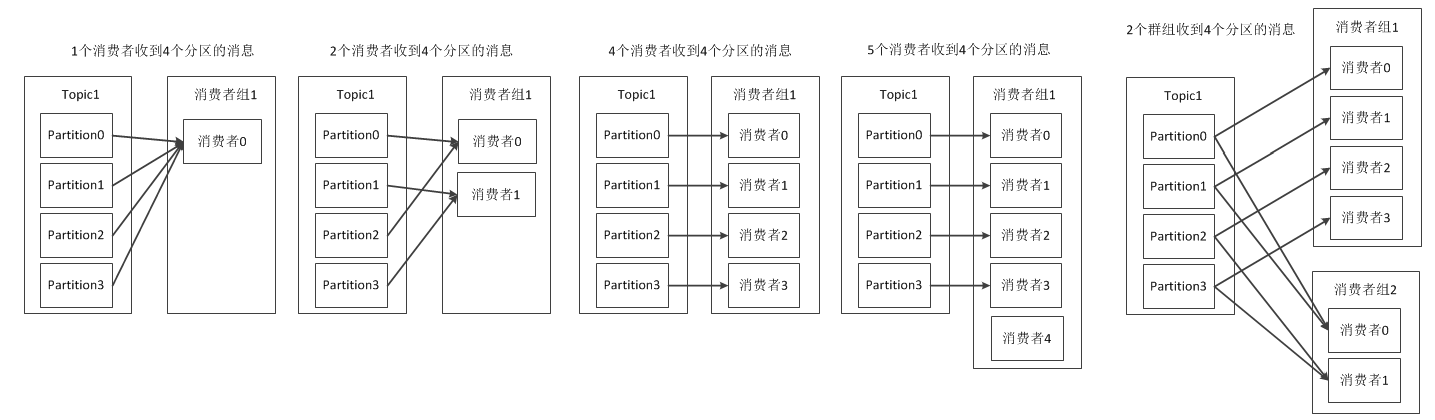
分区分配策略
Kafka消费者客户端可通过配置parition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略,默认情况下为,参数值为:org.apache.kafka.clients.consumer.RangeAssignor
即采用RangeAssignor分配策略,表示按跨度来分配。除此之外,Kafka还提供了另外两种分配策略:RoundRobinAssignor 和StickyAssignor.
RangeAssignor分配策略
RangeAssignor分配策略的原理是按照消费者总数与分区总数进行整除运算后获得一个跨度,然后将分区按照跨度进行平均分配,以保证尽可能的均匀的分配给所有消费者。对于每一个主题,RangeAssignor策略会将消费者组内所有订阅该主题的消费者按照名称的字典排序,然后为每个消费者划分一个固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会多分配一个分区。
计算逻辑为:假设n=分区数 / 消费者数量, m=分区数 % 消费者数量, 那么前m个消费者每个分配 n + 1个分区,后面的消费者(消费者数量-m) 每个分配n个分区。
假设主题A有7个分区,其中一个消费者组有3个消费者,7/3=2, 7%3=1, 所以分配如下:
消费者1分配: 3个, 消费者2:分配2个,消费3分配:2个
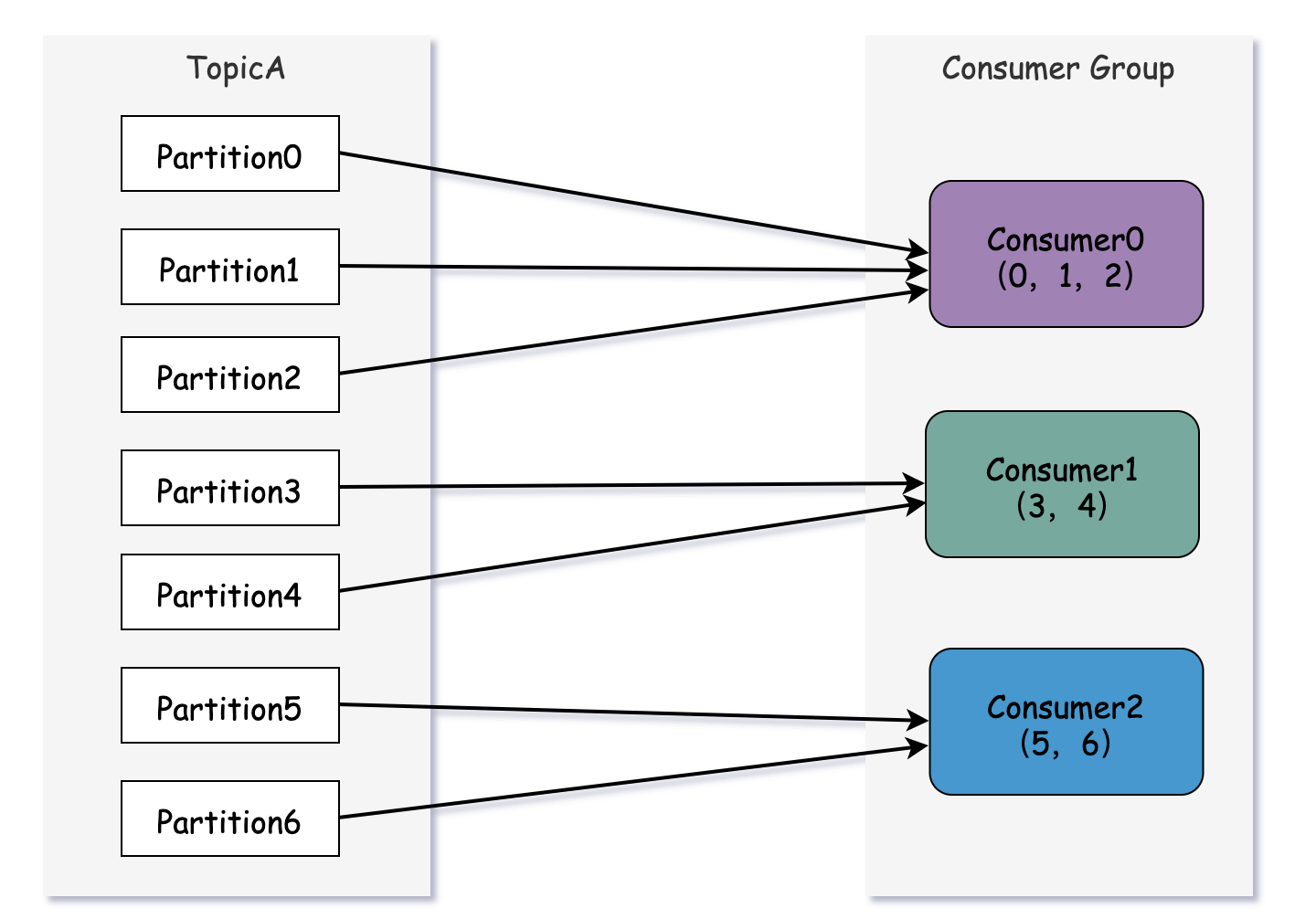
这种分配方式能尽量均匀分配,如果消费组订阅了2主题,那么会造成部分消费者订阅较多分区的情况。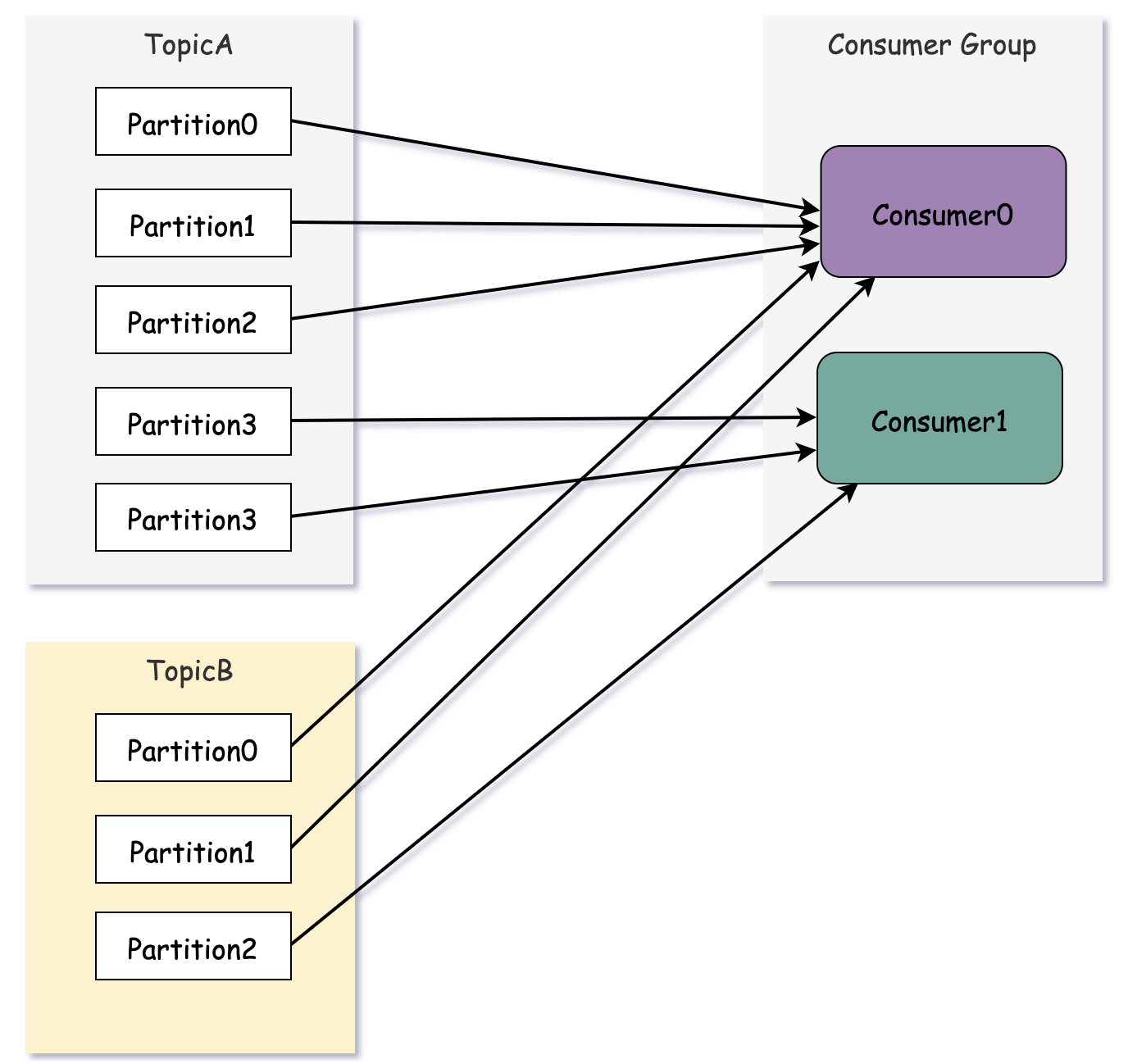
可以看到,消费者0分配了5个分区,消费1分配了3个分区。如果将类似的情况扩大,则有可能出现部分消费者过载的情况
RoundRobinAssignor分配策略
RoundRobinAssignor分配策略的原理是将消费者组内所有消费者及订阅的所有主题分区按照字典序排序,然后通过轮询方式逐个将分区一次分配给每个消费者。
如果同一个消费组内的所有消费者订阅信息是相同的,那么RoundRobinAssignor分配策略的分区分配是均匀的。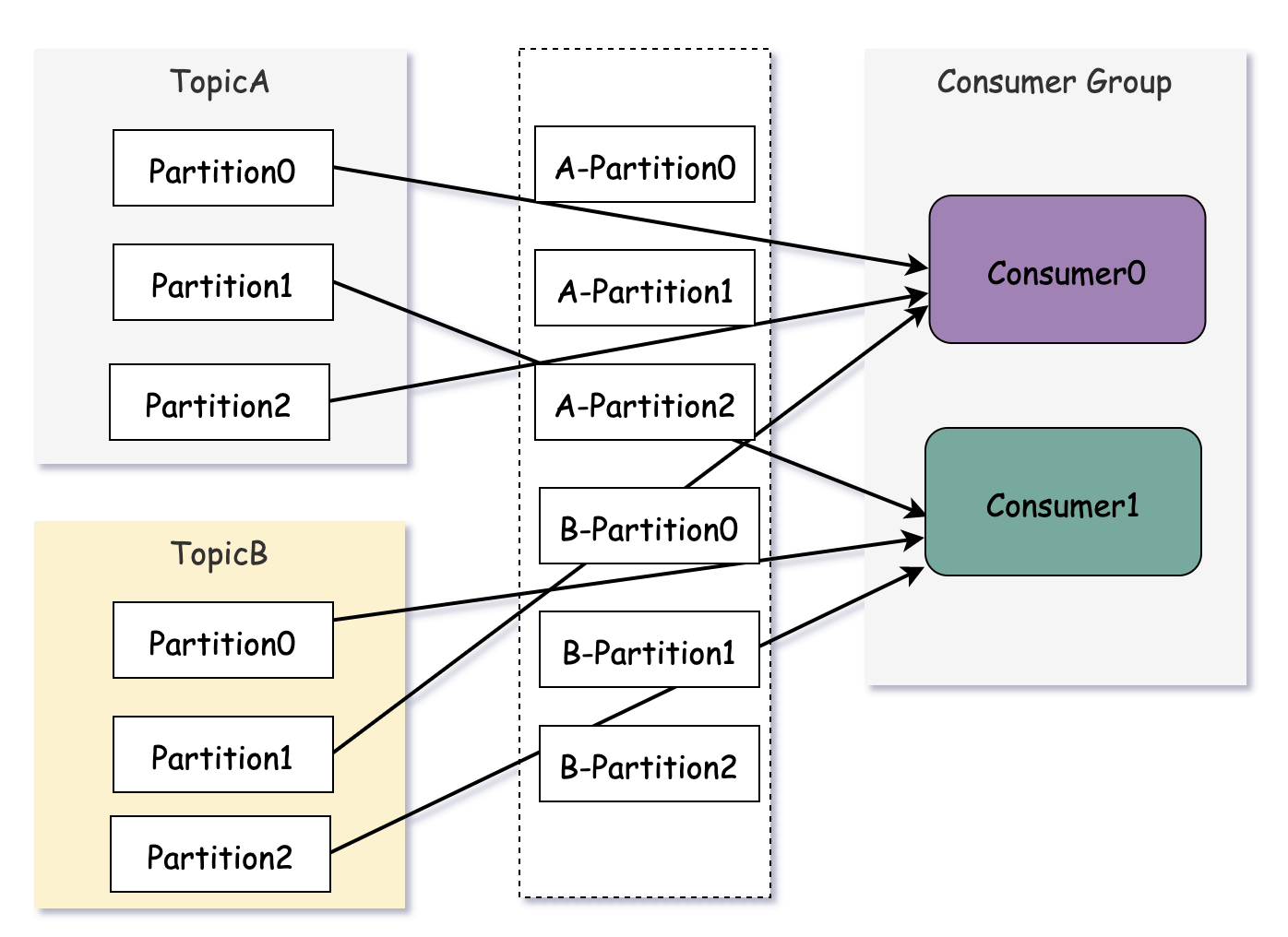
两个消费者,分配定义2个主题,一个主题有3个分区,那么每个消费者均衡分配到3个分区。
如果主题的分区信息不同,则仍然会导致消费者分配不均匀。
再均衡原理
Kafka消费者客户端通过再均衡来协同同一消费组内的消费者,如果消费者配置了不同的分区分配策略,需要裁决一个公共的策略,并下发最终的分区分配方案。
Kafka 消费者需要定期地发送心跳请求(Heartbeat Request)到Broker端的协调者,以表明它还存活着。在Kafka 0.10.1.0版本之前,发送心跳请求是在消费者主线程完成的,也就是你写代码调用KafkaConsumer.poll方法的那个线程。
这样做有诸多弊病,最大的问题在于,消息处理逻辑也是在这个线程中完成的。因此,一旦消息处理消耗了过长的时间,心跳请求将无法及时发到协调者那里,导致协调者“错误地”认为该消费者已“死”。自0.10.1.0版本开始,Kafka引入了一个单独的心跳线程来专门执行心跳请求发送,避免了这个问题。
再均衡的通信机制则是通过心跳线程来完成,客户端的消费者协调器(ConsumerCoordinator)与Broker端的组协调器(GroupCoordinator)通过心跳线程(HeartbeatThread)来完成交互与通信,最终完成再均衡流程,完成分区重新分配。当组协调者决定开启新一轮重平衡后,它会将“REBALANCE_IN_PROGRESS”封装进心跳请求的响应中,发还给消费者实例。当消费者实例发现心跳响应中包含了“REBALANCE_IN_PROGRESS”,就能立马知道重平衡又开始了,这就是再均衡的触发机制。
再均衡让消费者具备高可用与扩展性,使得主题可以很安全的增加消费者或减少消费者. 触发再均衡流程目前一共有如下几种情形:
- 有新的消费者加入组
- 有消费者下线(宕机或长时间GC,网络延迟导致长时间不向GroupCoordinator发生心跳)
- 消费者主动退出消费组(发送LeaveGroupRequest)。比如调用consumer.close()方法或unsubscribe()方法取消订阅某主题
- 消费者所对应的GroupCoordinator发生了变更
- 消费组内所订阅的任一主题的分区数量发生变化
第一阶段-查找组协调器(Find_Coordinator)
消费者需要确定组对应的组协调器是哪个Broker,并创建与该Broker相互通信的网络连接。
如果当前消费者已经保存了消费组对应的GroupCoordinator的节点信息,且与他之间的网络连接是正常的,则可以直接进入第二阶段。
但是,消费者往往不知道集群中谁是GroupCoordinator Broker, 所以需要先查找。所以消费者成员需要向集群中最小负载节点发送 FindCoordinatorRequest 这里的最小负载节点即 leastLoadedNode, 查找算法与生产者获取元数据请求类似,具体见文档(https://www.yuque.com/scherrer/architect/vynde9#3477k)
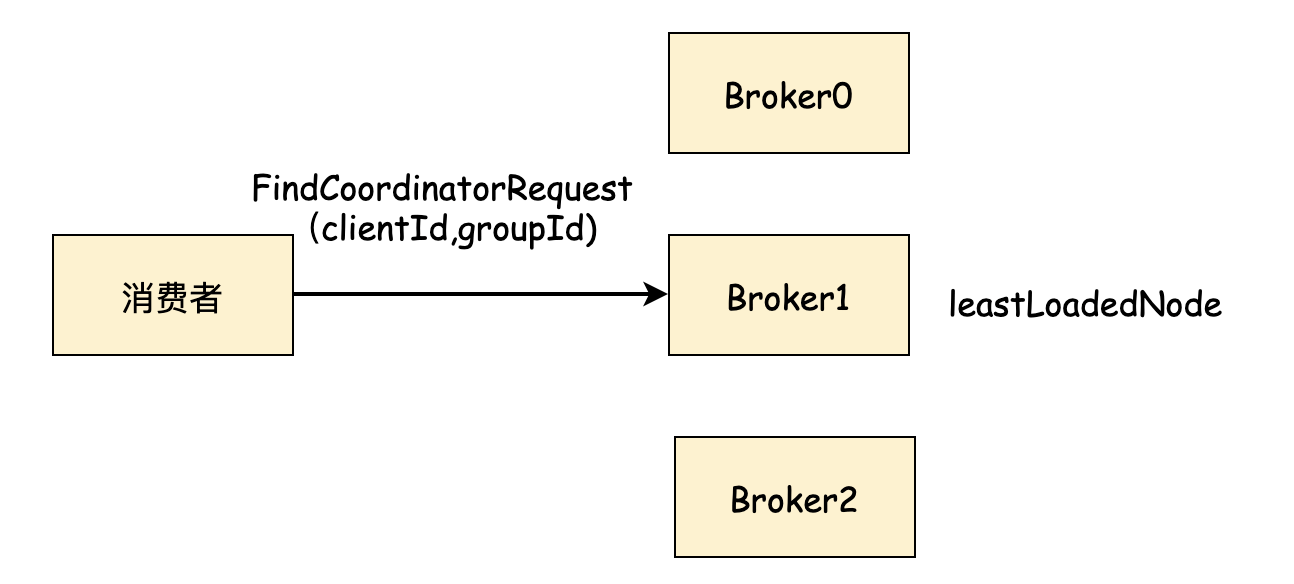
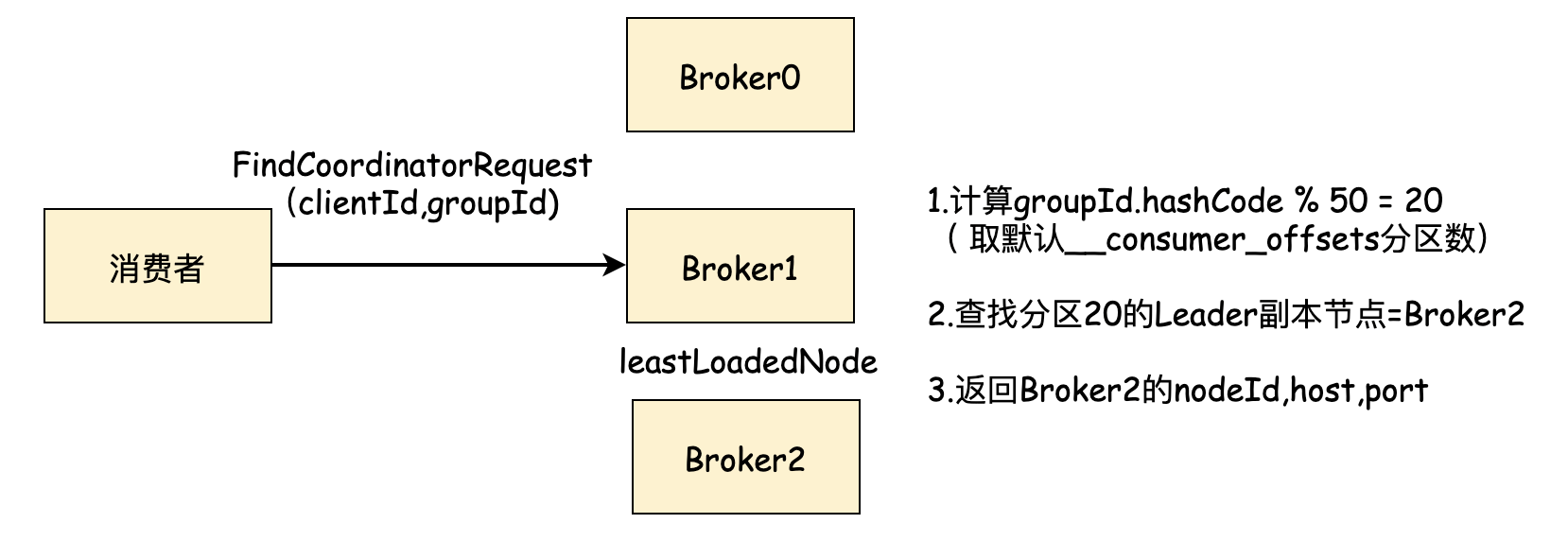
Kafka Broker收到FindCoordinatorRequest后,取出groupId, 查找GroupCoordinator节点,也就是组协调器节点,找到后返回节点对应的:nodeId, host, port信息
谁是组协调器节点
计算逻辑为:根据groupId的哈希值的绝对值 与 __consumer_offsets 内部位移主题的分区数取模。
Utils.abs(groupId.hashCode()) % groupMetadataTopicPartitionCount
groupMetadataTopicPartitionCount 为内部主题__consumer_offsets的分区数量,默认为50,副本因子默认为3。可通过Broker端参数 offsets.topic.num.partitions, offsets.topic.replication.factor来配置。
通过groupId 按照上述计算逻辑,找到__consumer_offsets 的分区编号后,在寻找此分区的Leader副本所在是Broker节点,该Broker节点即为当前groupId对应的组协调器节点。 消费者groupId最终的分区分配方案及组内消费者所提交的位移信息都会发送给此分区Leader副本所在的Broker节点。
所以此Broker节点既是组协调器GroupCoordinator,又负责保存分区分配方案和组内消费者位移。
**
然后Broker返回FindCoordinatorResponse,消费者获取到组协调器后,发起与该Broker的连接,进入加入消费组阶段。
第二阶段-加入消费组(Join_Group)
在此阶段,消费者向组协调器发起JoinGroupRequest请求,并等待响应。发送的参数主要有:
1)client_id 即当前消费者参数配置的client.id
2)group_id 即当前消费组的id
3)session_timeout 对应消费端参数session.timeout.ms 默认值为10000,即10秒。GroupCoordinator在超过session_timeout指定的时间内没有收到心跳报文则认为此消费者已经下线
4)rebalance_timeout 默认为5分钟,表示消费组再均衡过程的最大时间,GroupCoordinator会等待各个消费者重新加入的最长等待时间
5)member_id 表示GroupCoordinator分配给消费者的id表示,第一次请求时为null
6)分区分配策略的name,如果不同的消费者配置了多个,则都需要带上
7)主题订阅信息,表示当前消费者订阅了哪些主题信息
memberId生成
服务端收到JoinGroupRequest请求后,交给GroupCoordinator来处理。如果消费者是第一次加入组,请求中的member_id值为null, 需要为它生成一个唯一标识。生成逻辑为:
如果client.id非空字符串,则:memberId = clientId + “-“ + UUID.randomUUID().toString();
如果client.id为空字符串,则:memberId = groupId + 当前消费者序号 + UUID.randomUUID().toString();
实际Debug图示: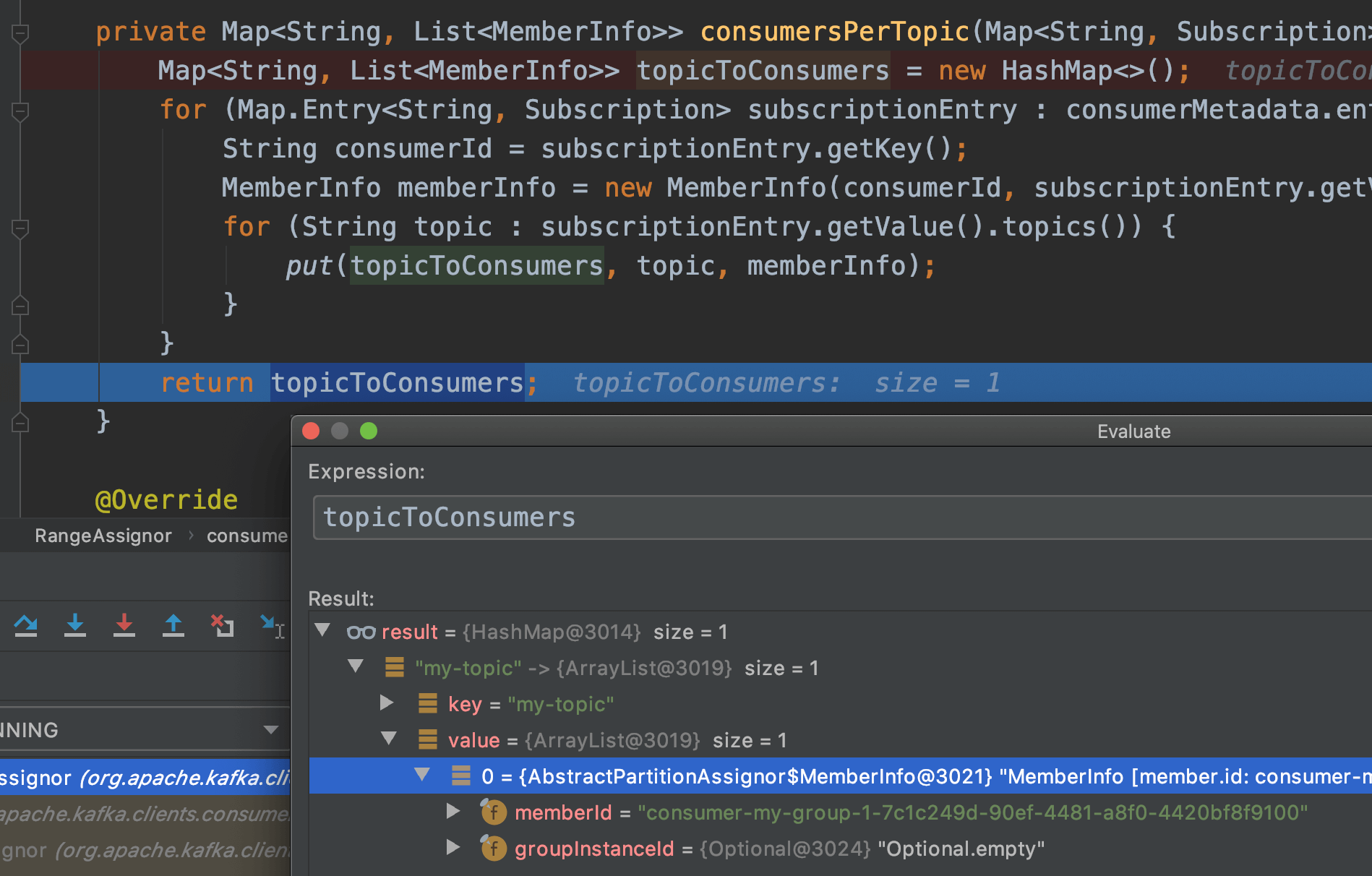
选举消费组的Leader消费者
GroupCoordinator需要为消费组内的消费者选出一个Leader,选举算法很简单。分为两种情况:
1)如果组内还没有Leader,那么第一个加入组的消费者成为Leader消费者
2)如果某时刻Leader消费者因为某些原因退出了消费组,则取GroupCoordinator维护的HashMap
所以追求简单是才是最佳设计
选举分区分配策略
GroupCoordinator还需要从消费者发送过来的JoinGroupRequest中取出分配策略,并基于类似投票的算法来选举最终的分区分配策略,具体选举过程如下:
1)收集各个消费者支持的所有分配策略,组成选举候选集candidates
2) 每个消费者从候选集中找出第一个自身支持的策略,为这个策略投上一票(就是计数器)
3) 计算候选集中各个策略的选票数,选票数最多的策略即为消费组的分配策略
实际情况中,同一个消费组一般配置的策略都是相同的,很少有不一致的,建议也不要配成不一致的,增加了复杂度与维护成本。
之后,协调器选举完分区分配策略后,需要分别发送不同的数据给消费者,分为Leader的响应与普通消费者的响应,发送给Leader消费者包含了所有其他消费者的成员信息,而普通消费者则没有。结构大致为:
member主要是消费者成员信息及主题分区定义信息,包含主题是什么,分区及分区数量
整体图示
1)每个消费者都想GroupCoordinator发送JoinGroupRequest请求,带上各自的分区分配策略和订阅信息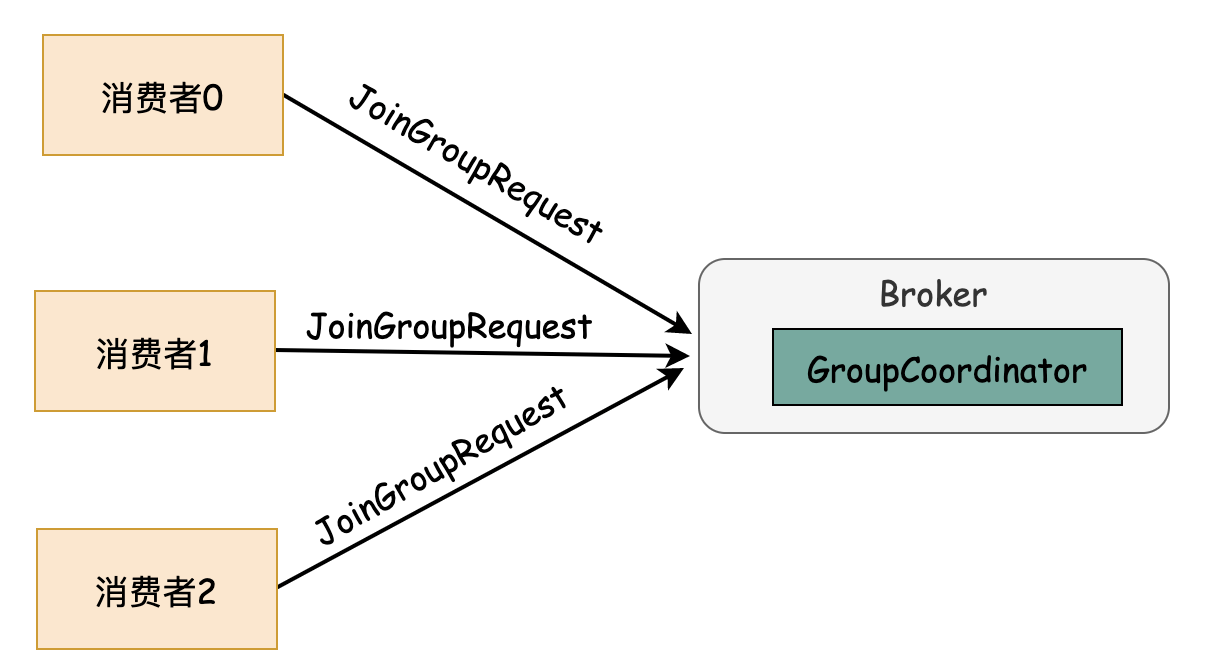
2)JoinGroupResponse回执中包含组协调器投票选举出的分区分配策略,Leader节点回执包含了各个消费者的定义信息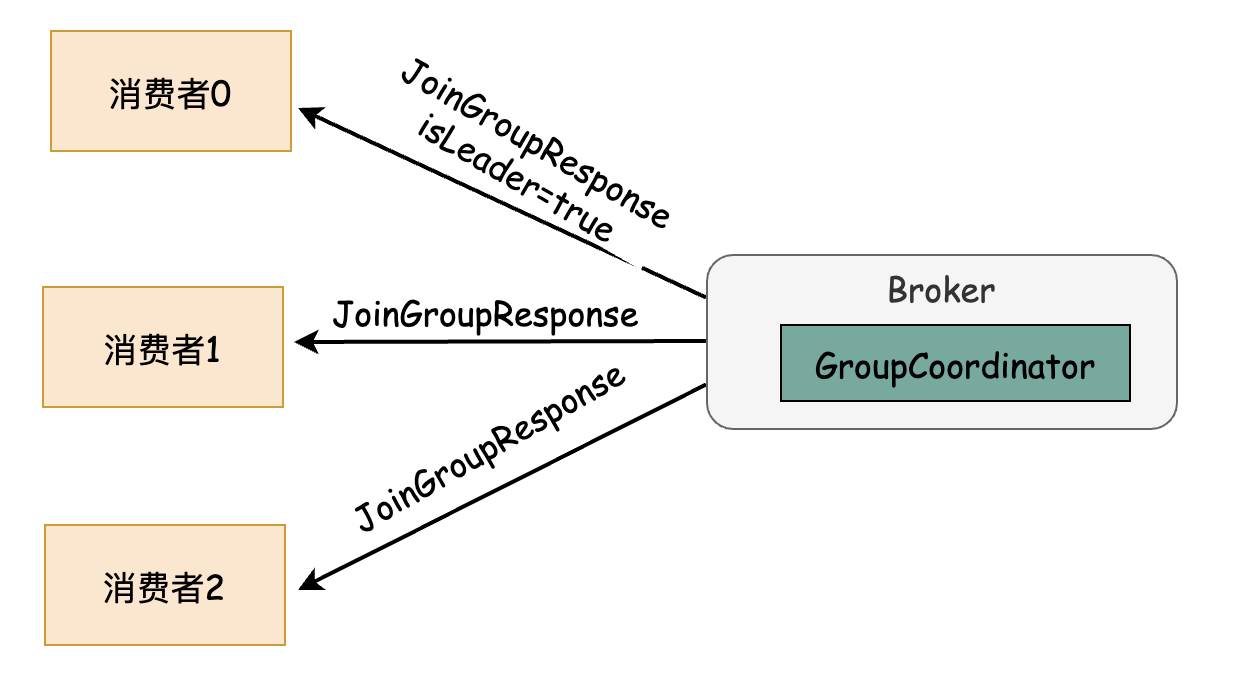
第三阶段-同步组(Sync_Group)
Leader消费者根据第二阶段选举的分区分配策略来实施分区分配,具体来说是执行ConsumerPartitionAssignor的assign方法。如果分配方案是range, 则执行org.apache.kafka.clients.consumer.RangeAssignor的分配逻辑,即按范围分配.
如果RangeAssignor分配的Debug图示: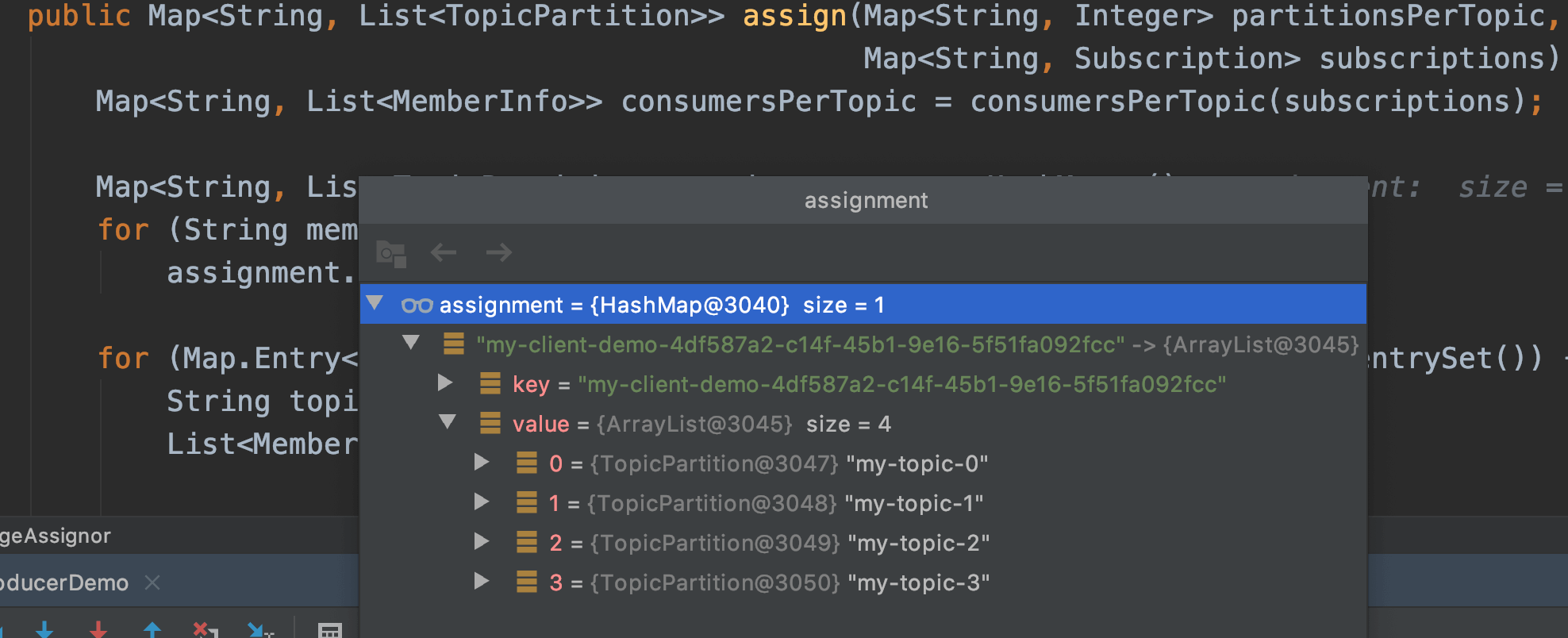
assign方法执行之后, 需要把分配的方案同步给各个消费者,Leader不负责直接同步方案给其他消费者,而是通过组协调器来完成。Leader及其他所有消费者都会向GroupCoordinator发送SyncGroupRequest请求,请求结构大致为: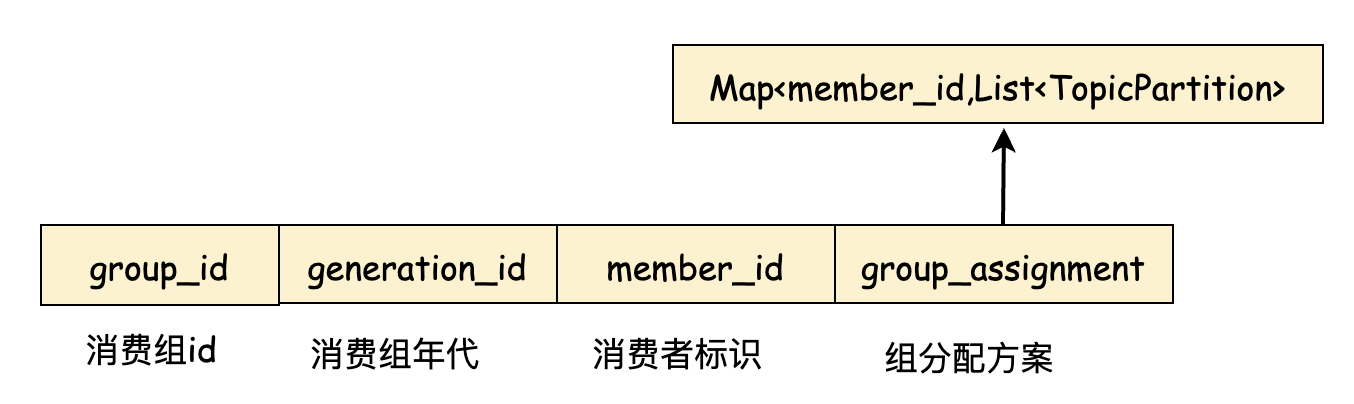
只有Leader的SyncGroupRequest请求才会带上group_assignment,即为具体的分配方案,是一个Map结构,Key为消费者的MemberId, Value为List,表示当前消费者消费哪些主题的哪些分区号。其他的消费者的group_assignent则为空。
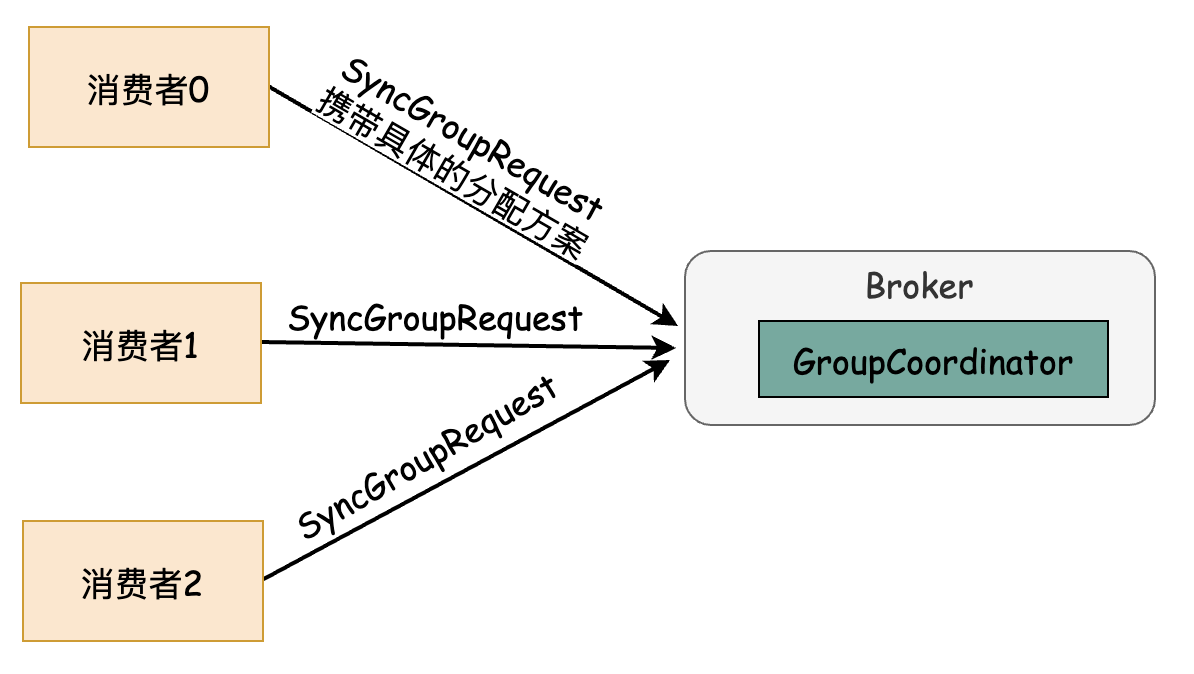
服务端收到消费者发送的SyncGroupRequest请求后,仍然交给GroupCoordinator协调器来负责具体的逻辑处理。
取出Leader发送的分配方案,读取整个消费组的元数据信息一起写入Kafka的__consumer_offsets主题中,然后发送SyncGroupResponse,即各个消费者各自所属分配方案。
当消费者收到所属的分配方案之后会调用ConsumerPartitionAssignor的onAssignment方法,然后再调用ConsumerRebalanceListener的onPartitionsAssigned方法。之后开启心跳任务,定期向服务端的GroupCoordinator发送HeartbeatRequest请求,用以确定存活性。
消费者元数据
消费组元数据(GroupMetadata)与消费者位移的写入机制类似,都是存储到Kafka内部主题__confumer_offsets中, 具体来说每个消费组的元数据信息都是一条消息,消息只定义了Key与Value字段的具体内容,不依赖具体版本的消息格式。简要结构为: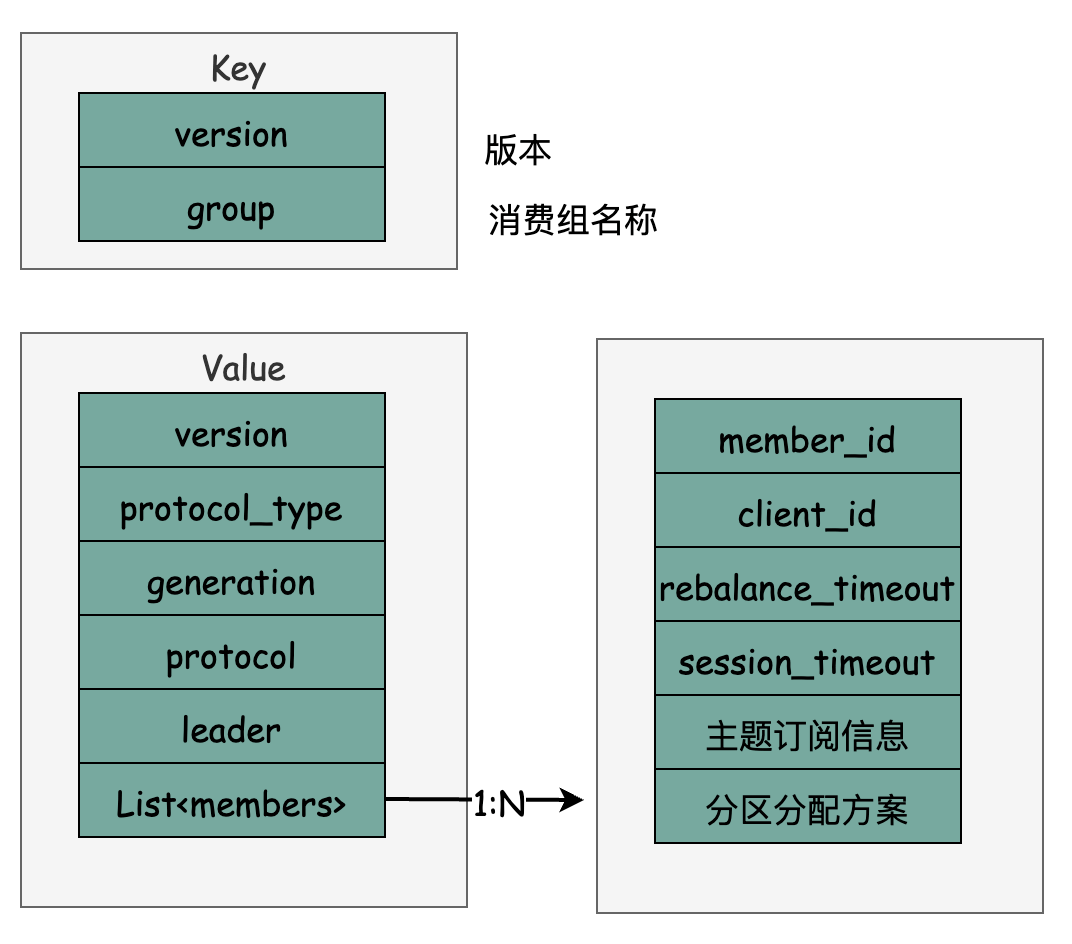
重要的字段释义如下:
1)group 为消费组名称,与FindGroupRequest,JoinGroupRequest中传入的groupId一致,用同样的算法找到内部主题的分区号
2)protocol: 消费组选取的分区分配策略
3)leader: 消费组Leader的标识
4)members: 数组类型,包含了消费者的成员情况与分区分配信息
简要处理逻辑为:通过group计算出分区编号,然后查找分区的Leader节点,然后把元数据消息发送给该Broker.
流程概要
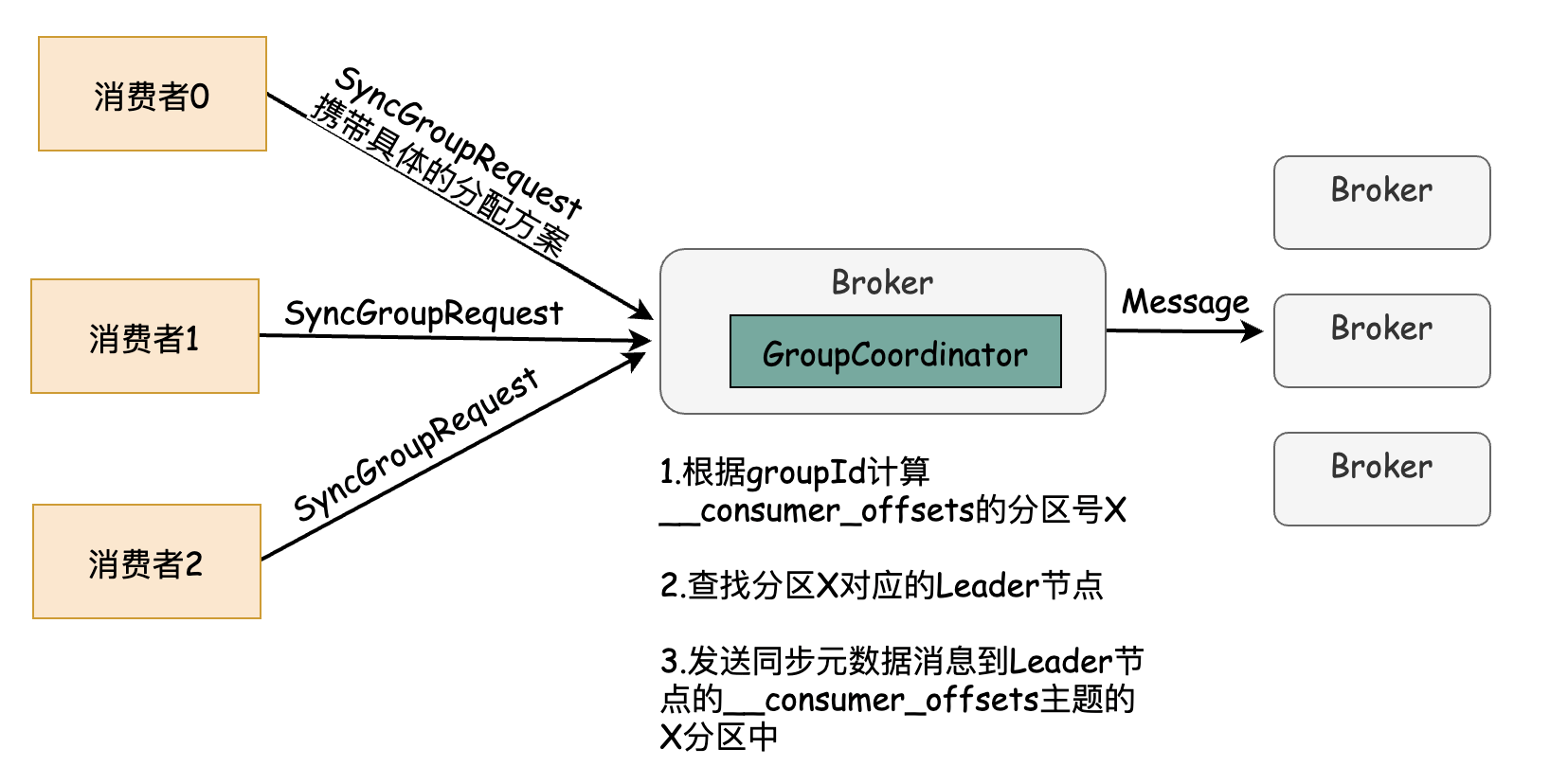
第四阶段-心跳(Heartbeat)
进入这个阶段后,消费组中的所有消费者就会处于正常状态中。在正式消费前还需要确定拉取消息的起始位置。如果之前已经提交过位移信息,GroupCoordinator则已经保存到Kafka内部主题__consumer_offsets中。消费者可以通过OffsetFetchRequest请求获取上次提交的消费位移并从此处继续消费。
然后消费者通过向GroupCoordinator发送心跳来维持他们与消费组的从属关系,以及他们对分区的所有权关系。
如上文提到的,心跳线程是一个独立的线程,可以在轮询消息的空挡,通过心跳线程间隔性的发送心跳给协调者。如果消费者停止发送心跳的时间足够长,则整个会话会被组协调者判断为过期,组协调者也会认为这个消费者已经「死亡」,就会触发一次再均衡行为。消费者的心跳间隔时间由参数heartbeat.interval.ms 指定,默认为3000,即3秒。一般情况下,该参数需要不超过session.timeout.ms 配置值的1/3。
如果一个消费者发送崩溃,并停止读取消息,那么组协调器GroupCoordinator会等待session.timeout.ms,所配置的时间,默认为5秒,确认这个消费者死亡之后才会发起再均衡。
内部主题__consumer_offsets
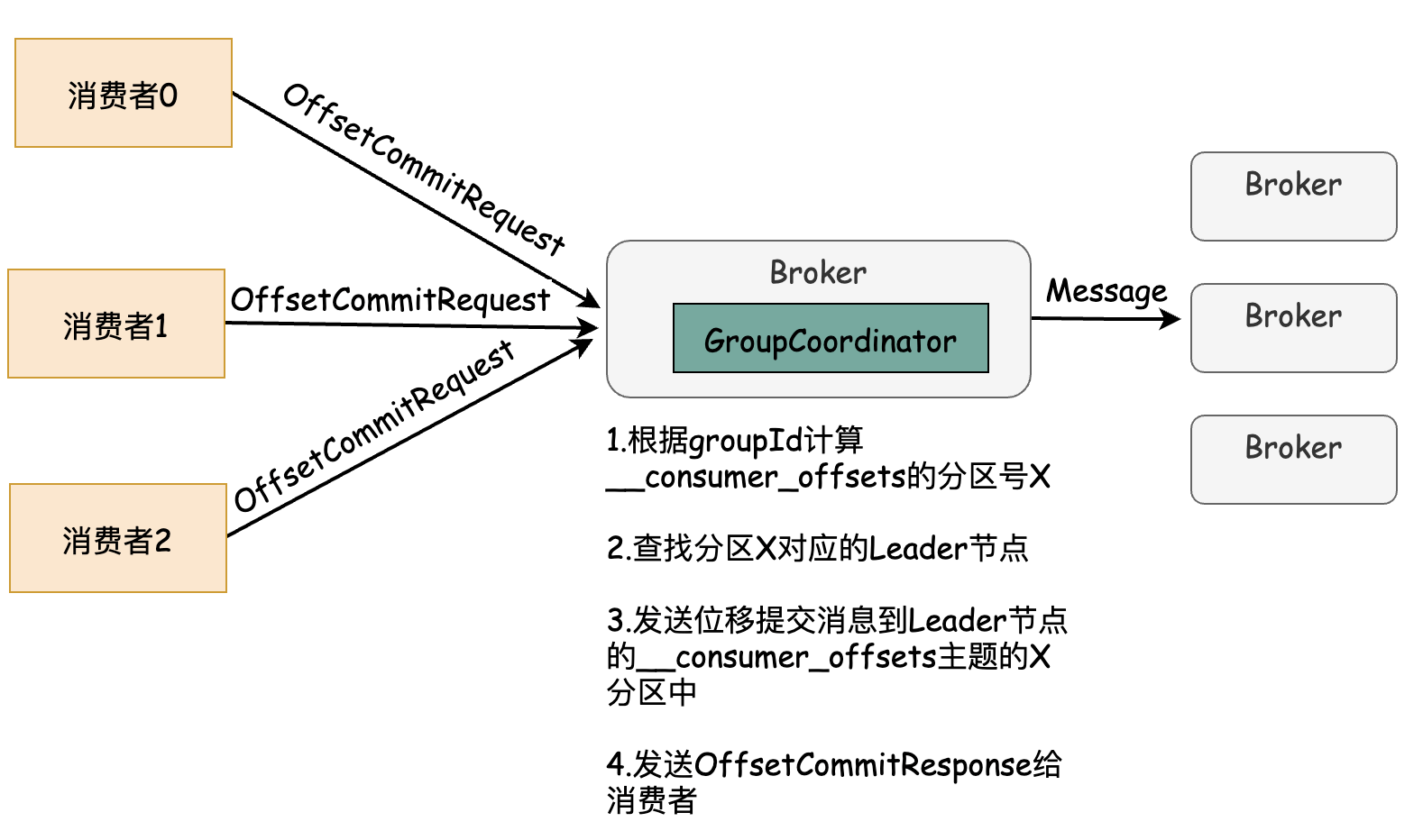
一般情况下,当集群中第一次有消费者消费消息时会自动创建主题__consumer_offsets. 副本因子可通过offsets.topic.replication.factor参数设置,默认为3. 分区数可通过offsets.topic.num.partititions 参数设置,默认为50. 客户端提交消费位移时会发送OffsetCommitRequest 请求,然后通过协调器以消息的形式发送到Kafka内部主题consumer_offsets的分区中。(通过groupId找到consumer_offsets的某个分区)
OffsetCommitRequest定义简要如下:
public class OffsetCommitRequestData implements ApiMessage {String groupId; // 消费组名称int generationId; // 消费组年代信息String memberId; // 消费组标识String groupInstanceId;long retentionTimeMs; // 客户端设置的,消息保留时间. 固定为-1。Kafka会使用服务端配置的消息保留时间List<OffsetCommitRequestTopic> topics;}public static class OffsetCommitRequestTopic implements Message {String name; // topic 名称List<OffsetCommitRequestPartition> partitions;}public static class OffsetCommitRequestPartition implements Message {int partitionIndex; // 分区编号long committedOffset; // 提交的位移int committedLeaderEpoch;long commitTimestamp;String committedMetadata;}
同消费组元数据信息一样,最终提交的消费位移也会以消息的形式发送到__consumer_offsets的某个分区中。具体流程简要为:消费组发送OffsetCommitRequest 到组协调者,然后协调者取出对应的分区消费位移信息,构造一个消息体,其结构只定义了Key和Value, 不依赖具体版本的消息格式。如下图: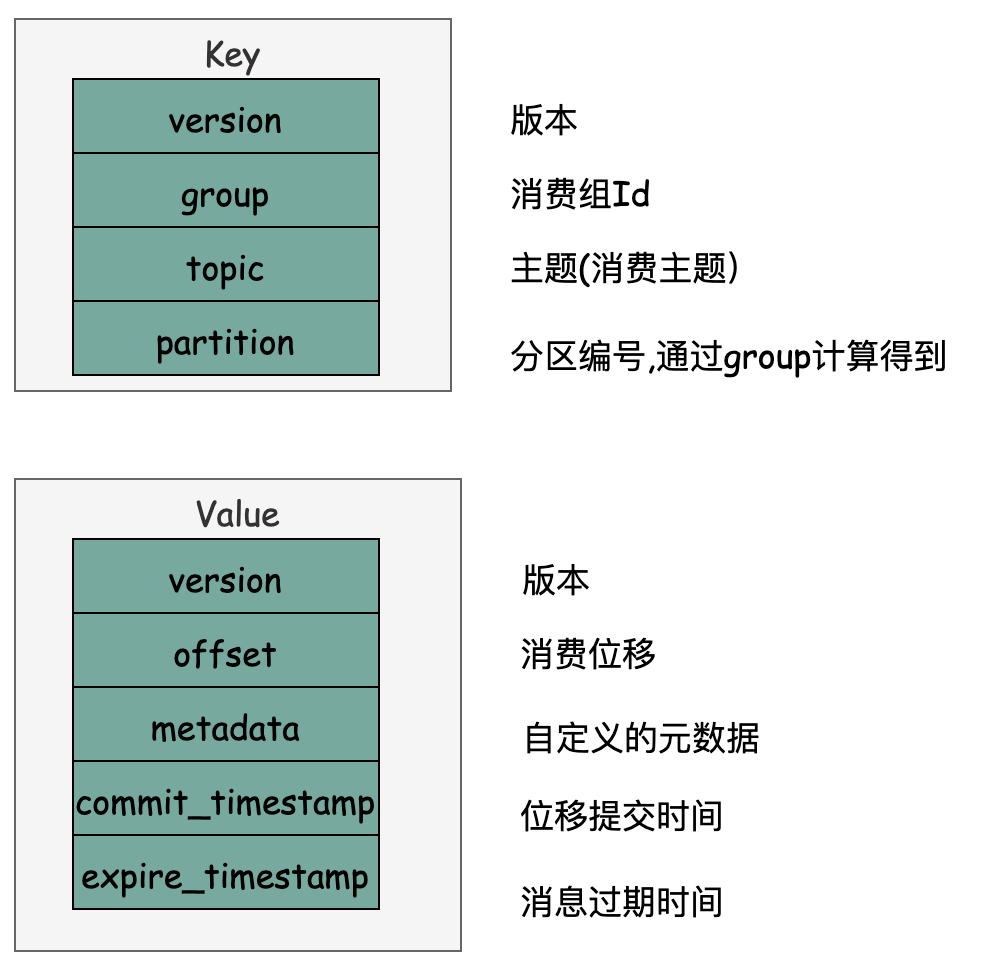
协调者发送完成位移提交消息后,然后返回OffsetCommitResponse给客户端,主要信息为分区的提交位移。
流程概要
查看位移提交信息
bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server localhost:9092--formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"--consumer.config config/consumer.properties --from-beginning
默认的Consumer配置如下:
bootstrap.servers=localhost:9092# consumer group idgroup.id=test-consumer-group
结果为:
[test-consumer-group,__consumer_offsets,29]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1618146773905, expireTimestamp=None)[test-consumer-group,__consumer_offsets,34]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1618146773905, expireTimestamp=None)[test-consumer-group,__consumer_offsets,10]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1618146773905, expireTimestamp=None)[test-consumer-group,__consumer_offsets,32]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1618146773905, expireTimestamp=None)[test-consumer-group,__consumer_offsets,40]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1618146773905, expireTimestamp=None)
OffsetsMessageFormatter的日志前3列输出格式占位符为:group, topic, partition

若有收获,就点个赞吧
0 人点赞
