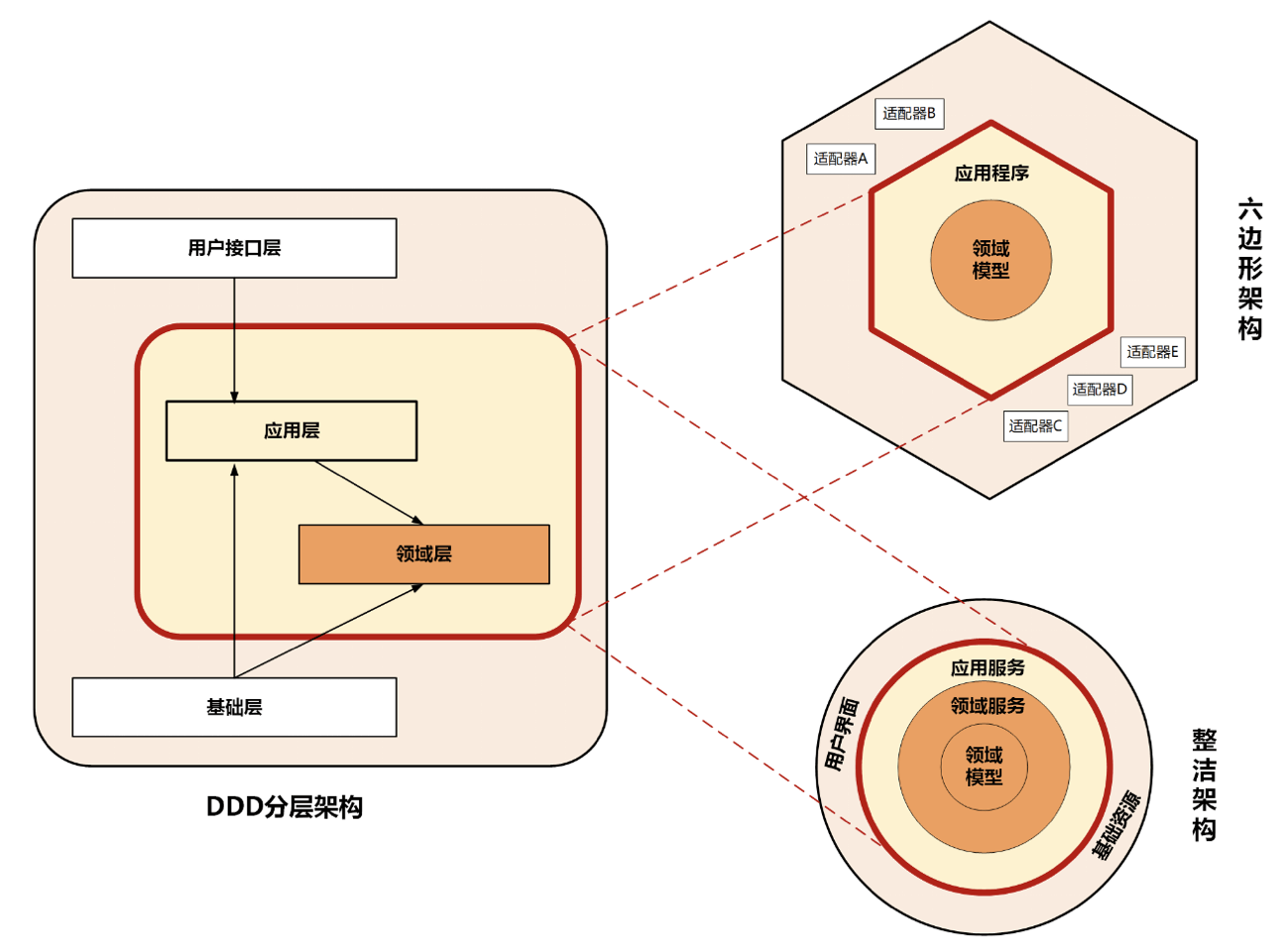
什么是好代码
灵活性(flexibility)、可扩展性(extensibility)、可维护性(maintainability)、可读性(readability)、可理解性(understandability)、易修改性(changeability)、可复用(reusability)、易测试性(testability)、模块化(modularity)、高内聚低耦合(high cohesion loose coupling)、高效(high effciency)、高性能(high performance)、安全性(security)、兼容性(compatibility)、易用性(usability)、整洁(clean)、清晰(clarity)、简单(simple)、直接(straightforward)、少即是多(less code is more)、文档详尽(well-documented)、分层清晰(well-layered)、正确性(correctness、bug free)、健壮性(robustness)、鲁棒性(robustness)、可用性(reliability)、可伸缩性(scalability)、稳定性(stability)、优雅(elegant)
我理解的什么是好代码
可维护
落实到编码开发,所谓的“维护”无外乎就是修改 bug、修改老的代码、添加新的代码之类的工作。所谓“代码易维护”就是指,在不破坏原有代码设计、不引入新的 bug 的情况下,能够快速地修改或者添加代码。所谓“代码不易维护”就是指,修改或者添加代码需要冒着极大的引入新 bug 的风险,并且需要花费很长的时间才能完成。
可读性
我们在编写代码的时候,时刻要考虑到代码是否易读、易理解。除此之外,代码的可读性在非常大程度上会影响代码的可维护性。毕竟,不管是修改 bug,还是修改添加功能代码,我们首先要做的事情就是读懂代码。代码读不大懂,就很有可能因为考虑不周全,而引入新的 bug.
我们需要看代码是否符合编码规范、命名是否达意、注释是否详尽、函数是否长短合适、模块划分是否清晰、是否符合高内聚低耦合等等.
code review 是一个很好的测验代码可读性的手段。如果你的同事可以轻松地读懂你写的代码,那说明你的代码可读性很好;如果同事在读你的代码时,有很多疑问,那就说明你的代码可读性有待提高了
可扩展
它表示我们的代码应对未来需求变化的能力。跟可读性一样,代码是否易扩展也很大程度上决定代码是否易维护。那到底什么是代码的可扩展性呢?代码的可扩展性表示,我们在不修改或少量修改原有代码的情况下,通过扩展的方式添加新的功能代码。说直白点就是,代码预留了一些功能扩展点,你可以把新功能代码,直接插到扩展点上,而不需要因为要添加一个功能而大动干戈,改动大量的原始代码. 主要使用OCP原则来应对。
灵活性
灵活性是一个挺抽象的评价标准,要给灵活性下个定义也是挺难的。不过,我们可以想一下,什么情况下我们才会说代码写得好灵活呢?我这里罗列了几个场景:
- 当我们添加一个新的功能代码的时候,原有的代码已经预留好了扩展点,我们不需要修改原有的代码,只要在扩展点上添加新的代码即可。这个时候,我们除了可以说代码易扩展,还可以说代码写得好灵活。
- 当我们要实现一个功能的时候,发现原有代码中,已经抽象出了很多底层可以复用的模块、类等代码,我们可以拿来直接使用。这个时候,我们除了可以说代码易复用之外,还可以说代码写得好灵活。
- 当我们使用某组接口的时候,如果这组接口可以应对各种使用场景,满足各种不同的需求,我们除了可以说接口易用之外,还可以说这个接口设计得好灵活或者代码写得好灵活。
可测试&易测试
测试方便,测试容易,很快速对变更代码作验证
可复用
简洁
尽量保持代码简单。代码简单、逻辑清晰,也就意味着易读、易维护。我们在编写代码的时候,往往也会把简单、清晰放到首位。
健壮性
写的代码对抗不符合预期的参数或数据时,会做什么响应? 例如在Map里取不确定是否存在的值时,建议通过MapUtills来操作。比如解析国际化的语言时,遇到不符合预期的locale,不能抛出异常阻断解析。
这里我们建议多用工具类来防控,但是也要了解工具类底层原理,才能有的放矢。
如何写出可读性好的代码
写注释
我们为什么要写注释,因为还写不出自解释的代码。所以还是从写注释开始。写好注释一小步,是好代码的一大步。
范围
类,public方法,接口,常量,必写。
protected,private方法,关键代码块 ,建议写
参考规范

其他
1)类代码行,不要太长,参考值300~500行,函数行数,不超过IDE的一屏幕,参考值50~80行
2)把代码分割成更小的单元块,大块的复杂逻辑提炼成类或者方法。
把逻辑复杂的方法分解成命名良好的小方法,各个方法的细节需要在同一逻辑层面,同一层逻辑不能使用底层或高层的逻辑语义 —-代码金字塔
示例:
foo(Request req) {方法A();方法B();方法C();}方法A() {方法A1();方法A2();}方法B() {方法B1();方法B2();}
3)public方法不要用参数来控制逻辑,否则职责不单一,可以选择方法重载,private方法可以,但是不建议大量使用。
if (isVip) vip用户逻辑
4)循环,if-else 嵌套不要超过2层:否则变得不可读,混乱
坚持CR
CR别人的代码,同时让别人CR你的代码
如何写可复用、可测试的代码
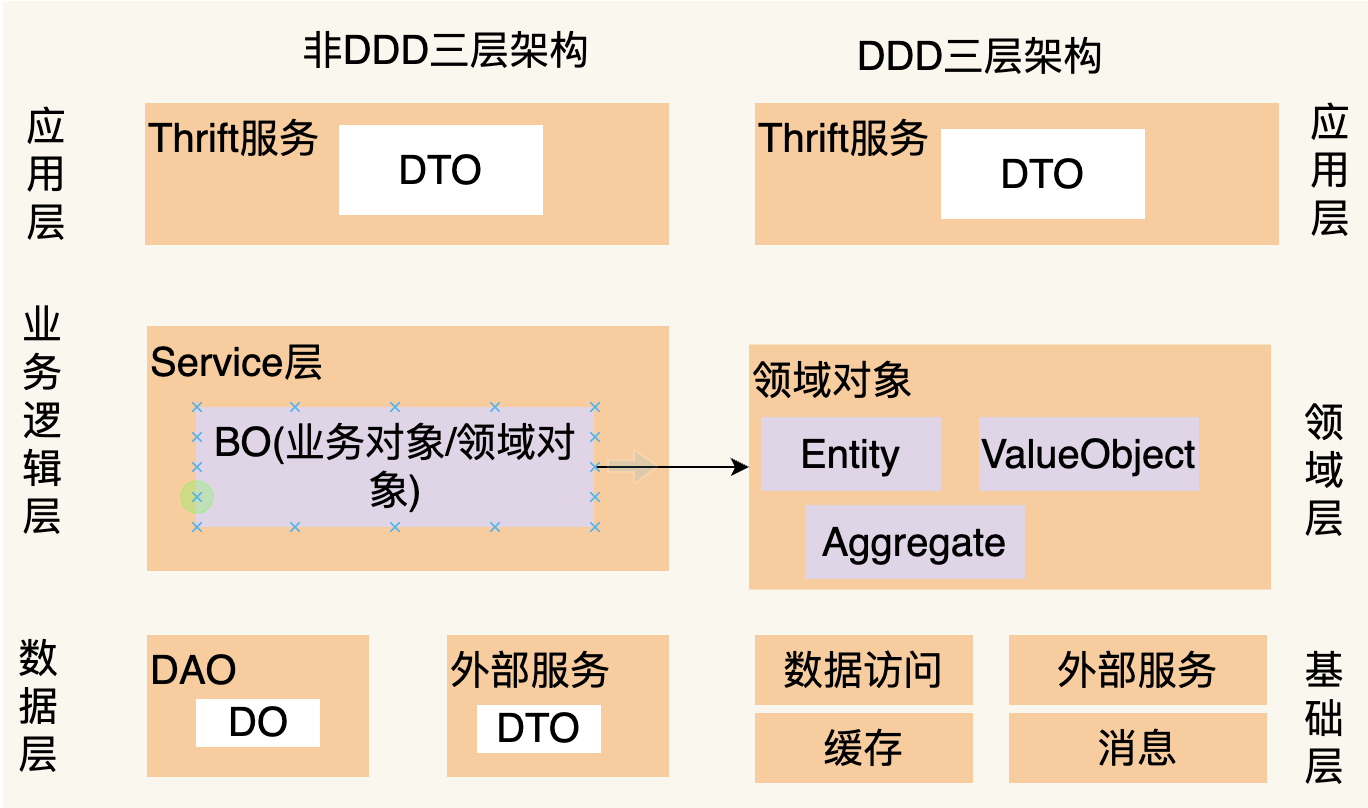
贫血模型 VS 与充血模型
贫血模型开发模式: 只包含数据,不包含行为(业务逻辑)的模型对象。业务逻辑都交由Service或Manager来完成。在贫血模型中,数据和业务逻辑被分割到不同的类中。
充血模型开发模式: 数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象编程风格。
为什么充血模型能解决可测试性与复用性?(注:解决复用还有其他方法,这里只解释充血模型)
充血模型依赖的数据由Service提供,内部不依赖任何的上下文环境,如DB,RPC等。只关注该模型对象的业务行为或业务逻辑。但也是一个普通的POJO,直接可以在main函数或单元测试方法中,new出该对象,几秒钟便可测试其行为是否正确。由于模型对象是可以复用的,其内部的业务逻辑设置为public,自然业务逻辑可复用。
对于贫血模型,大量的业务逻辑都写到Service里,一是代码不容易测试,因为Service一般依赖上下文环境,如Manger提供DB数据,RPC提供外部数据,每次测试一段Service里的代码,需要启动容器,加载环境,如DB,外部RPC实例,造成一定的启动时间成本,如果外部环境不稳定,还需要Mock RPC服务,导致测试变得复杂,因此很容易放弃单元测试,然后采用集成测试,从而间接降低了效率。
典型的场景:维护老系统时,在贫血模型的代码里不一定好改,有时候改动局部几行(如增加一个if-else)不好测试,因为老系统依赖太多,用的是老框架,老技术,本地无法启动,只能部署到开发或测试环境。
充血模型写在哪里
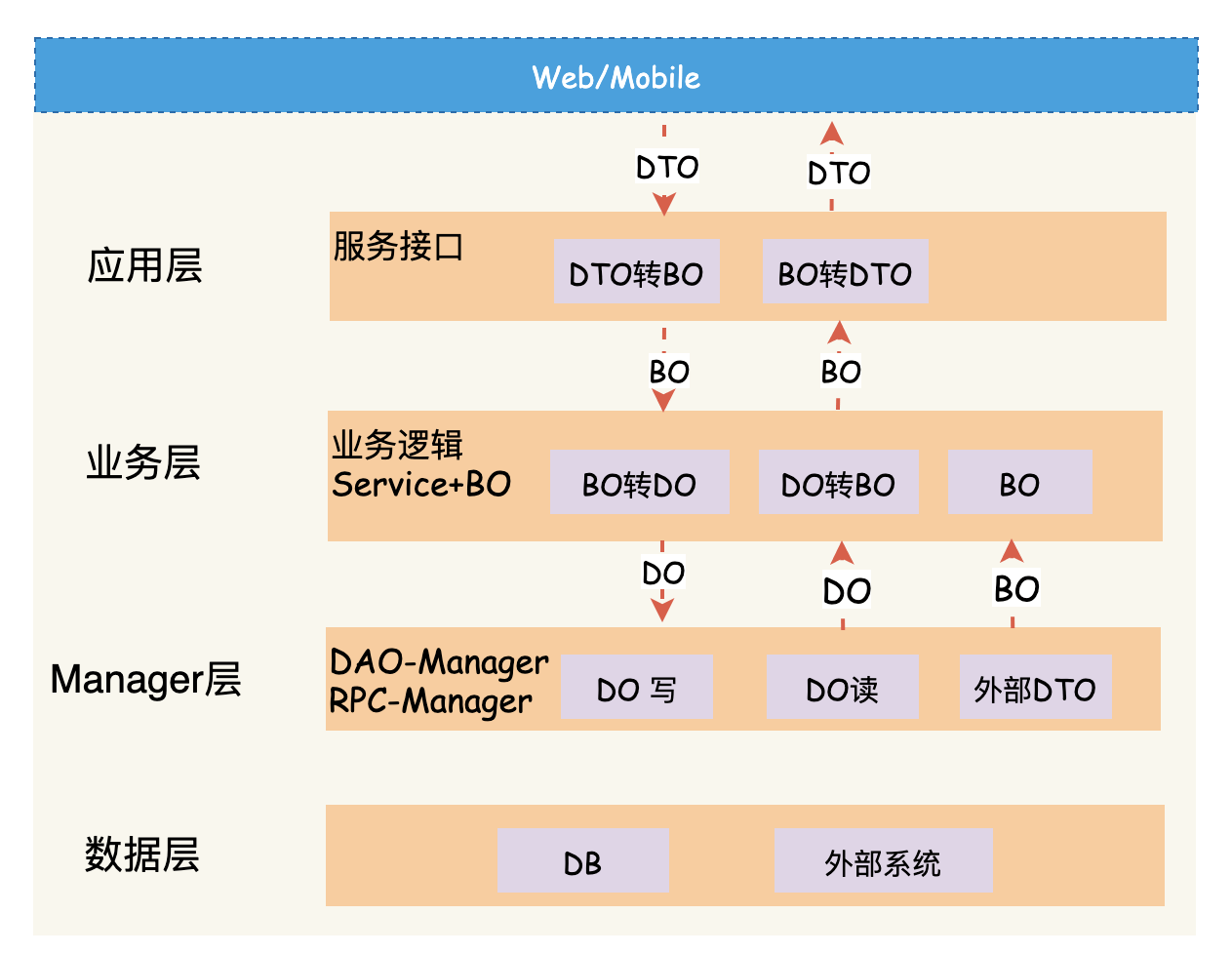
充血模型的技巧
1)直接使用当前模型的数据,并做数据操作,一般是无参数,如果当前模型的字段太多,可基于场景单独抽取新的模型对象(BO)
2)依赖另一个模型的数据,通过参数传入
3)依赖外部Service提供数据,用接口传入, 面向接口, 便于测试或依赖注入
4)依赖外部Service提供数据,用Function传入,适合一元参数,是接口的一种简写,不用定义新接口
如何写可扩展、可维护的代码
单一职责(SRP)
定义
一个类或者模块或方法只负责完成一个职责(或者功能):只做一件事
单一职责原则是为了实现代码高内聚、低耦合,提高代码的复用性、可读性、可维护性。
评价一个类的职责是否足够单一,我们并没有一个非常明确的、可以量化的标准,可以说,这是件非常主观、仁者见仁智者见智的事情。在平时开发中,我们也没必要过于未雨绸缪,过度设计。所以
我们可以先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,这个时候,我们就可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构.
重构参考原则:
类中的代码行数(参考值:超过200行~300)函数或者属性过多(参考值:超过10)
类依赖的其他类过多
私有方法过多;
比较难给类起一个合适的名字;
类中大量的方法都是集中操作类中的某几个属性
场景:重构拆分类
场景:不要通过参数来走不同的逻辑
对扩展开放对修改关闭(OCP)
定义
添加一个新的功能,应该是通过在已有代码基础上扩展代码(新增模块、类、方法、属性等),而非修改已有代码(修改模块、类、方法、属性等)的方式来完成。关于定义,我们有两点要注意。第一点是,开闭原则并不是说完全杜绝修改,而是以最小的修改代码的代价来完成新功能的开发。第二点是,同样的代码改动,在粗代码粒度下,可能被认定为“修改”;在细代码粒度下,可能又被认定为“扩展”。
比如典型的修改如下:
1. 修改public的方法签名,被调用的地方都受影响,都需要回归,都需要验证
2. 修改一个类的字段,被引用的地方都受影响(比如发布成SDK里,前端,其他系统都受影响)
3. 修改一个静态方法,被调用的地方都受影响
4. 修改一个局部方法,添加if-else来解决新需求
指导思想:为了尽量写出扩展性好的代码,我们要时刻具备扩展意识、抽象意识、封装意识。开发的时候,思考一下这段代码是否需要预留接口,预留扩展点。以便在未来需求变更的时候,在不改动代码整体结构、做到最小代码改动的情况下,将新的代码灵活地插入到扩展点上。
但是我们要认识到,添加一个新功能,不可能任何模块、类、方法的代码都不“修改”,这个是做不到的。类需要创建、组装、并且做一些初始化操作,才能构建成可运行的的程序,这部分代码的修改是在所难免的。我们要做的是尽量让修改操作更集中、更少、更上层,尽量让最核心、最复杂的那部分逻辑代码满足开闭原则
最常用来提高代码扩展性的方法有:多态、依赖注入、基于接口而非实现编程,以及大部分的设计模式(比如,装饰、策略、模板、职责链)
如何做到OCP
多if 场景:抽取接口,把逻辑放到不同的实现类,添加到执行链里,for循环执行,并是否阻断
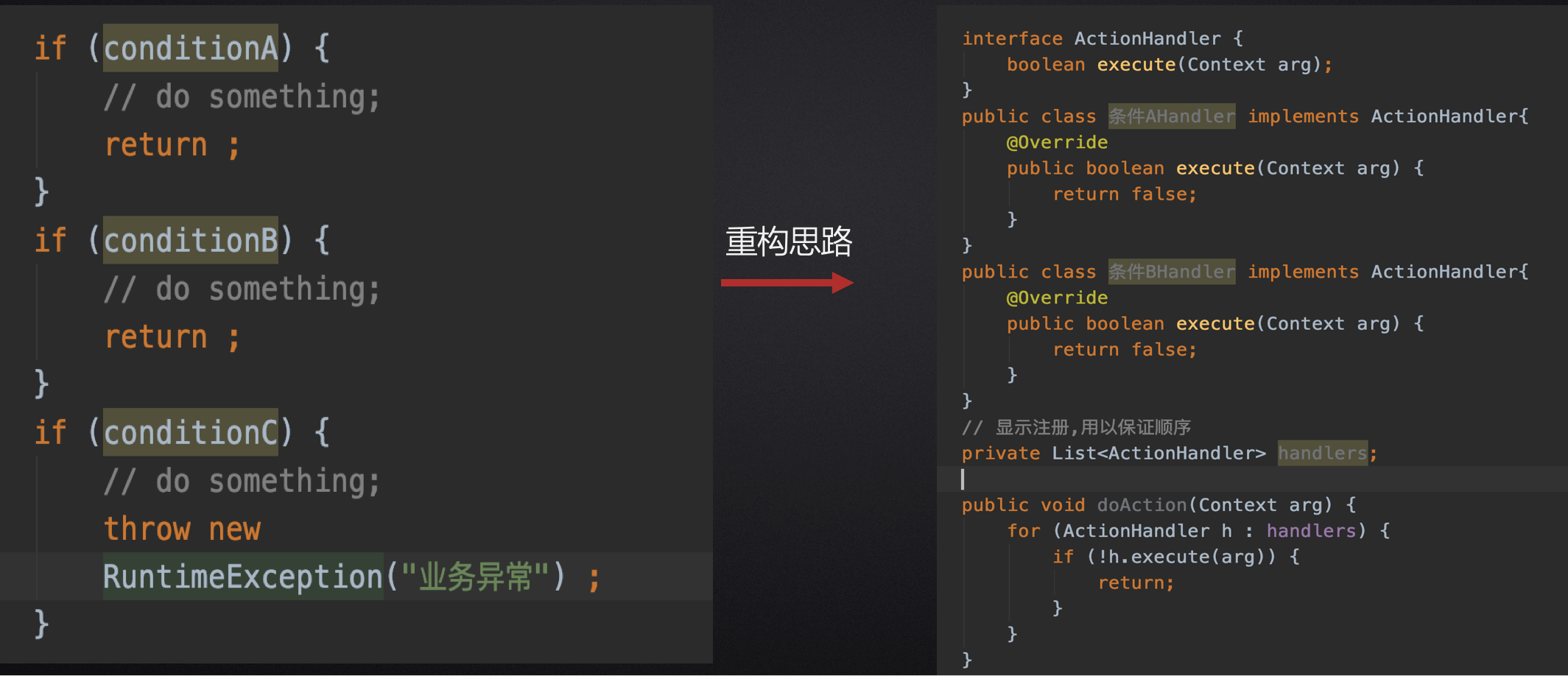
复杂逻辑方法:抽取接口,把逻辑放到不同的实现类,链式执行
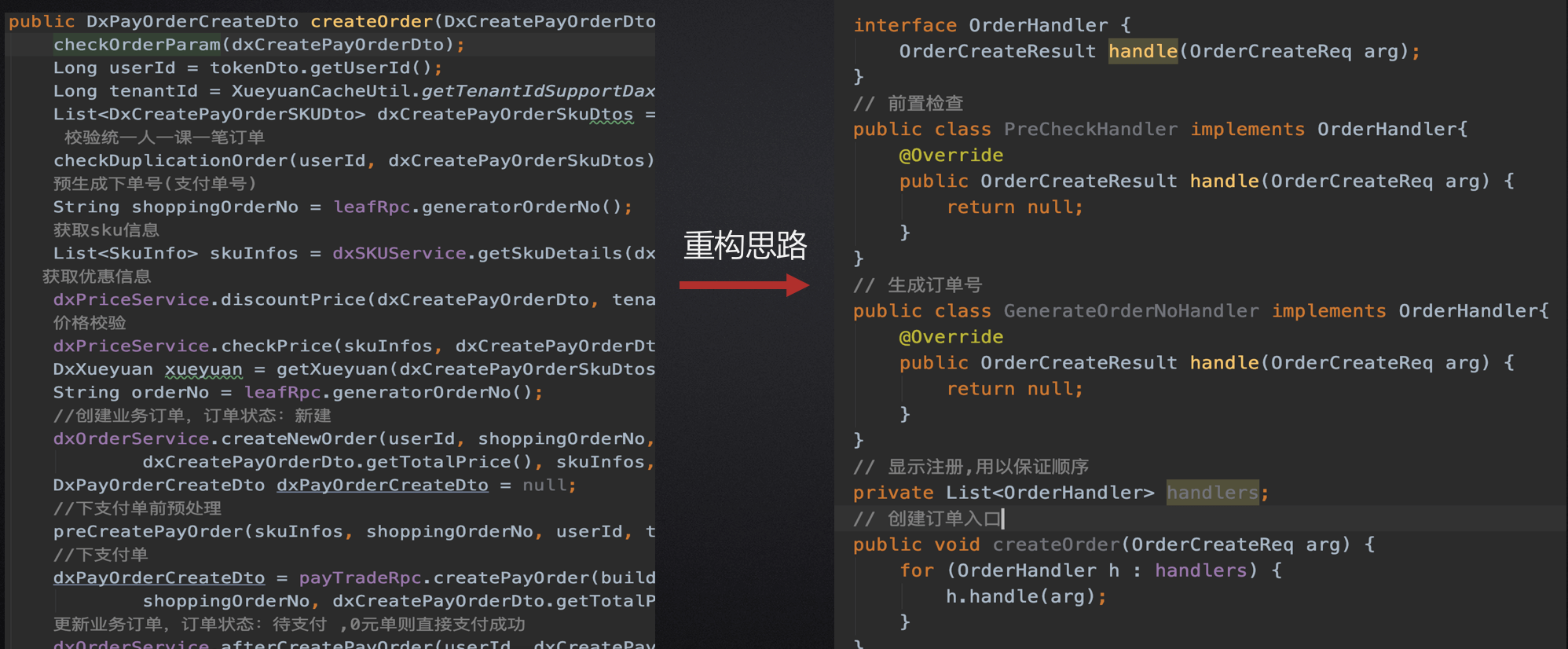
重构if-else:采用策略模式
1、采用策略模式,抽取接口
2、把逻辑放到不同的实现类
3. 把策略注册到容器里,然后查找策略执行
抽象
比如,我们代码中通过 Kafka 来发送异步消息。对于这样一个功能的开发,我们将其抽象成一组跟具体消息队列(Kafka)无关的异步消息接口。所有上层系统都依赖这组抽象的接口,并且通过依赖注入的方式来调用。当我们要替换新的消息队列的时候,比如将Kafka 替换成 RocketMQ,可以很方便地拔掉老的消息队列实现,插入新的消息队列实现(示例来自网络)
关于其他几个原则
接口隔离原则(ISP)
调用不应该依赖他不需要的接口(不依赖他不需要的服务接口集合,接口类,方法等)
示例: 不用依赖额外的接口或方法
里式替换(LSP)
子类对象(object of subtype/derived class)能够替换程序(program)中父类对象(object of base/parent class)出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏.
依赖反转原则(DIP)
高层模块(high-level modules)不要依赖低层模块(low-level)。高层模块和低层模块应该通过抽象(abstractions)来互相依赖。除此之外,抽象(abstractions)不要依赖具体实现细节(details),具体实现细节(details)依赖抽象(abstractions).
简言之:都依赖接口,通过注入具体的实现实例
迪米特法则(LOD)
又叫作最小知识原则,不该有直接依赖关系的类之间,不要有依赖;
有依赖关系的类之间,尽量只依赖必要的接口(不要引入不用的类或方法)
KISS
Keep it simple and stupid.在实际代码里,用简单的方式实现,不用过度设计,但是也不能完全没有设计。
YAGNI
You Ain’t Gonna Need it.
不要去设计当前用不到的功能;不要去编写当前用不到的代码,不要过度设计.
最佳实践
最佳实践:在不引入设计模式情况下,只要写好注释后,把大块代码按代码金字塔结构拆分为不同的小方法,递归的拆,直到最小。这样就已经完成了好代码的80%,剩下的就是根据需求,决定是否需要持续重构(引入扩展性设计)
常用设计模式

关于设计模式
设计模式要干的事情就是解耦,也就是利用更好的代码结构将一大坨代码拆分成职责更单一的小类,小方法,让其满足高内聚低耦合等特性.
创建型模式是将创建和使用代码解耦,结构型模式是将不同的功能代码解耦,行为型模式是将不同的行为代码解耦。
而解耦的主要目的是应对代码的复杂性。
设计模式就是为了解决复杂代码问题而产生的。

若有收获,就点个赞吧
0 人点赞
