开始
按M阶B+树的定义:
- 任意非叶子节点最多有M个子节点;且M>2;
- 除根节点以外的非叶子节点至少有 M/2个子节点;
- 根节点至少有2个子节点;
- 除根节点外每个节点存放至少M/2和至多M个关键字;(至少2个关键字)
- 非叶子节点的子树指针与关键字个数相同;
- 所有节点的关键字:K[1], K[2], …, K[M];且K[i] < K[i+1];
- 非叶子节点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树;
- 所有叶子节点位于同一层;
- 为所有叶子节点增加一个链指针;
- 所有关键字都在叶子节点出现;
模拟一颗简要版B+树如图A: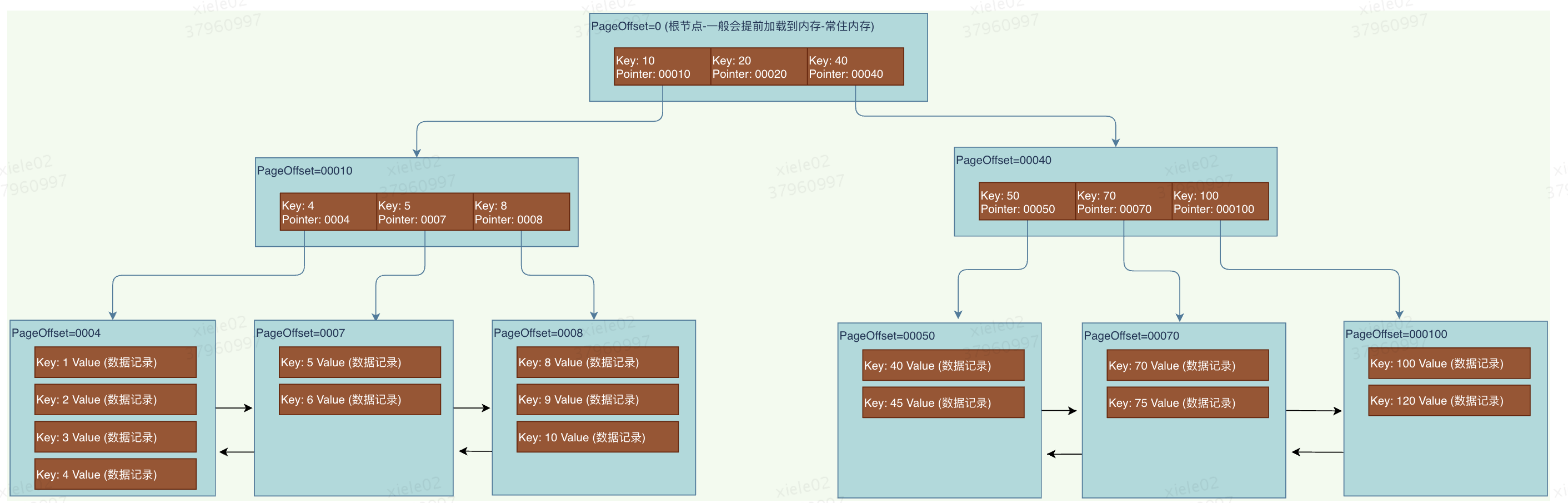
那一颗B+树大概能存多少条数据呢?要回答这个问题,需要先理解存储单元。
理解存储单元
我们都知道计算机在存储数据的时候,有最小存储单元。在计算机中磁盘存储数据最小单元是扇区,一个扇区的大小是 512 字节,而文件系统(例如XFS/EXT4)他的最小单元是块,一个块的大小是 4KB,而对于我们的 InnoDB 存储引擎也有自己的最小储存单元——页(Page),一个页的大小是 16KB。
如一个只有2字节的文件在磁盘上要占用4KB的空间来存储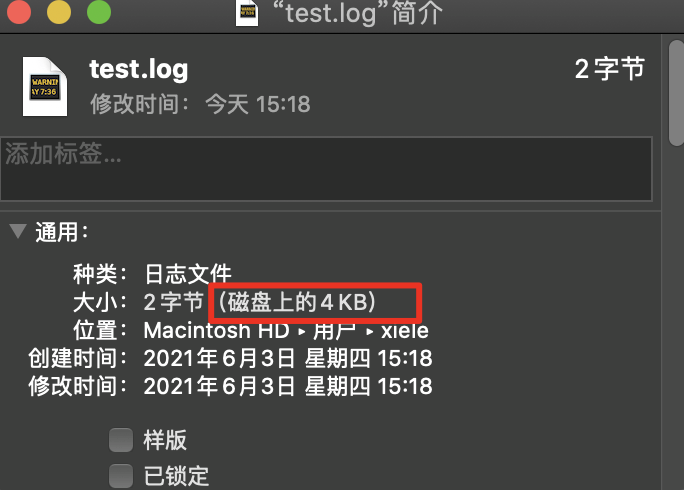
磁盘扇区、文件系统、InnoDB 存储引擎都有各自的最小存储单元,对比如下: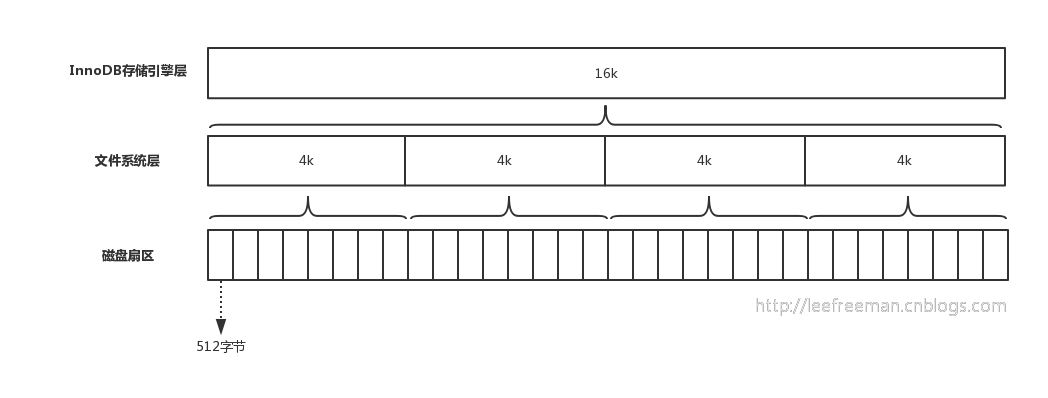
预读理论
磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。因此磁盘存取主要消耗在寻道和磁臂旋转,现在主流的商用磁盘的平均存取时间在8~11ms范围内。
计算机科学中的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用,程序运行期间所需要的数据通常比较集中。所以当磁头定位到相应的磁道时,顺序读取盘片相邻的扇区而不用再旋转磁臂,这也是顺序读取效率高的原因,此时,预读可以提供I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
索引组织表
当InnoDB读取16KB的最小单元页时,通过文件系统读取磁盘时,往往会读取多个扇区。所以InnDB读取完成一页后,完成一次IO。
InnoDB采用B+树来组织数据,所以也称为索引组织表。在B+树索引结构里,数据页可以放一行一行的数据(叶子节点),也可以放主键+指针(非叶子节点)。
如上图A所示,就是一颗聚簇索引树的大致结构。它先将数据记录按照主键排序,放在不同的页中,下面一行是数据页。上面的非叶子节点,存放主键值和一个指向页的指针。
假如一行数据大小是1k,那么理论上一页就可以放16条数据。那一页可以放多少主键+指针呢?
粗略估算
假如我们的主键id为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节。这样算下来就是 16384 / 14 = 1170,就是说一个页上可以存放1170个指针。
一个指针指向一个存放记录的页,一个页里可以放16条数据,那么一颗高度为2的B+树就可以存放 1170 16=18720 条数据。同理,高度为3的B+树,就可以存放 1170 1170 * 16 = 21902400 条记录。
理论上就是这样,在InnoDB存储引擎中,B+树的高度一般为2-4层,就可以满足千万级数据的存储。查找数据的时候,一次页的查找代表一次IO,那我们通过主键索引查询的时候,其实最多只需要2-4次IO就可以了。
实际情况会有些许差异,因为16KB的页不止只存储全部的数据,还有其他结构(具体可见:链接)所以实际的数据量会小很多,但是量级是相当的)
查找过程
InnDB B+树索引本身并不能直接找到具体的一条记录,只能知道该记录在哪个页上,数据库会把页载入到内存,再通过二分查找定位到具体的记录。
当我们通过主键来查询的时候,比如id=1的条件,就是通过这颗B+树来查找数据的过程。
1)它先找到根页(page offset=0)一般根页是固定的,存在表空间了,并常住内存。然后通过二分查找,定位到id=1的数据在指针为00010的页上, 加载该页所有的数据到内存,然后计算还需要读取pageoffset=0004的页(1次IO)
2)然后进一步读取page offset=0004的页,读取该页所有的数据到内存,然后通过二分查找读取到Id=1的数据(1次IO)
所以3层高的B+树最多需要2次IO即可完成千万级别的数据量的单次查询。
其他
为什么MySQL的索引要使用B+树而不是其它树形结构?比如B树?
简单来说,其中有一个原因就是B+树的高度比较稳定,因为它的非叶子节点不会保存数据,只保存键值和指针的情况下,一个页能承载大量的数据。如果B树它的非叶子节点也会保存数据的,同样的一行数据大小是1kb,那么它一页最多也只能保存16个指针,在大量数据的情况下,树高就会速度膨胀,导致IO次数就会很多,查询就会变得很慢。

若有收获,就点个赞吧
0 人点赞
