2020年发生的新冠肺炎疫情灾难给各国人民的生活造成了诸多方面的影响。
有的同学是收入上的,有的同学是感情上的,有的同学是心理上的,还有的同学是体重上的。
本文基于中国2020年3月之前的疫情数据,建立时间序列RNN模型,对中国的新冠肺炎疫情结束时间进行预测。
import osimport datetimeimport importlibimport torchkeras#打印时间def printbar():nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print("\n"+"=========="*8 + "%s"%nowtime)#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
准备数据
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt
%matplotlib inline%config InlineBackend.figure_format = 'svg'df = pd.read_csv("../data/covid-19.csv",sep = "\t")df.plot(x = "date",y = ["confirmed_num","cured_num","dead_num"],figsize=(10,6))plt.xticks(rotation=60);
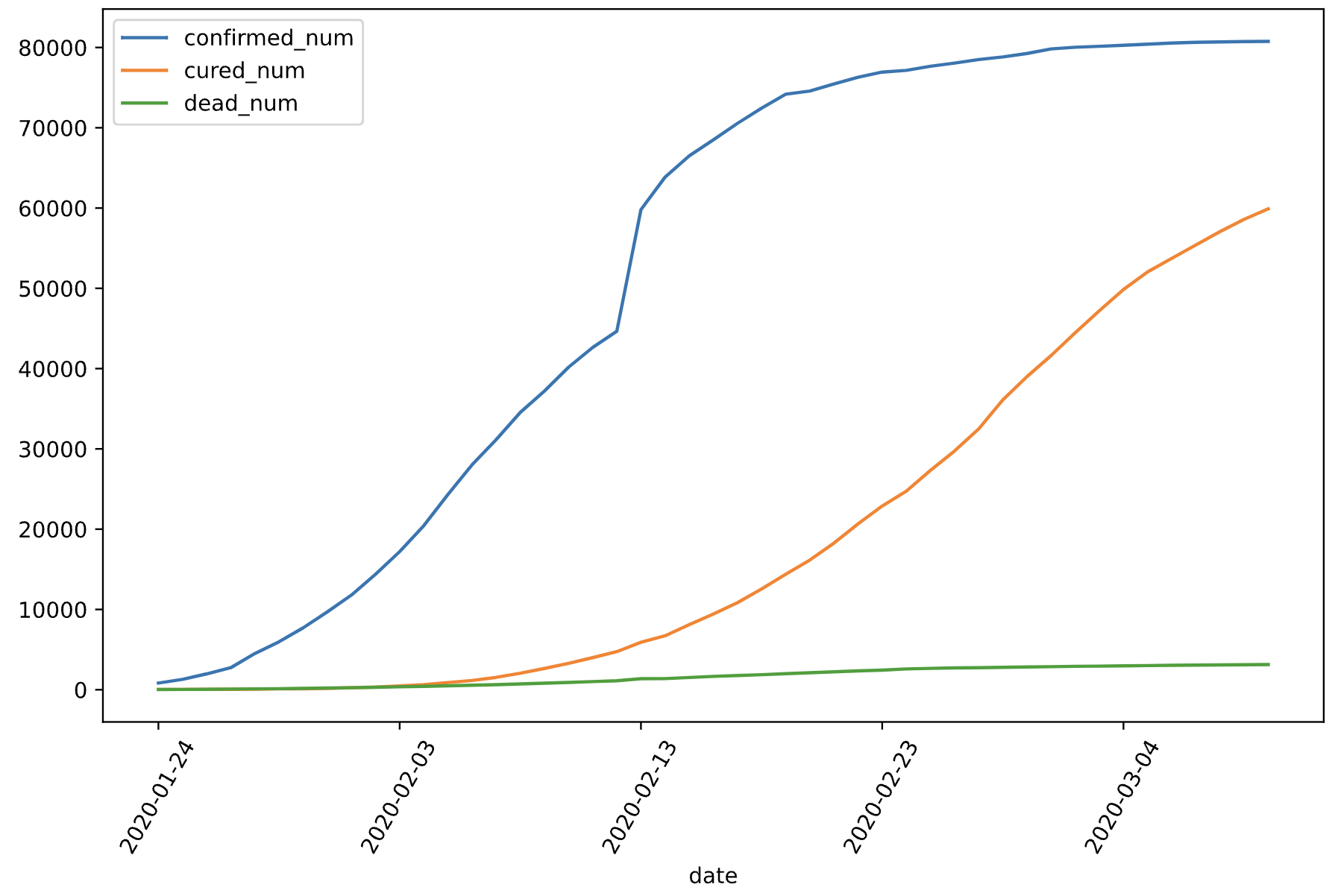
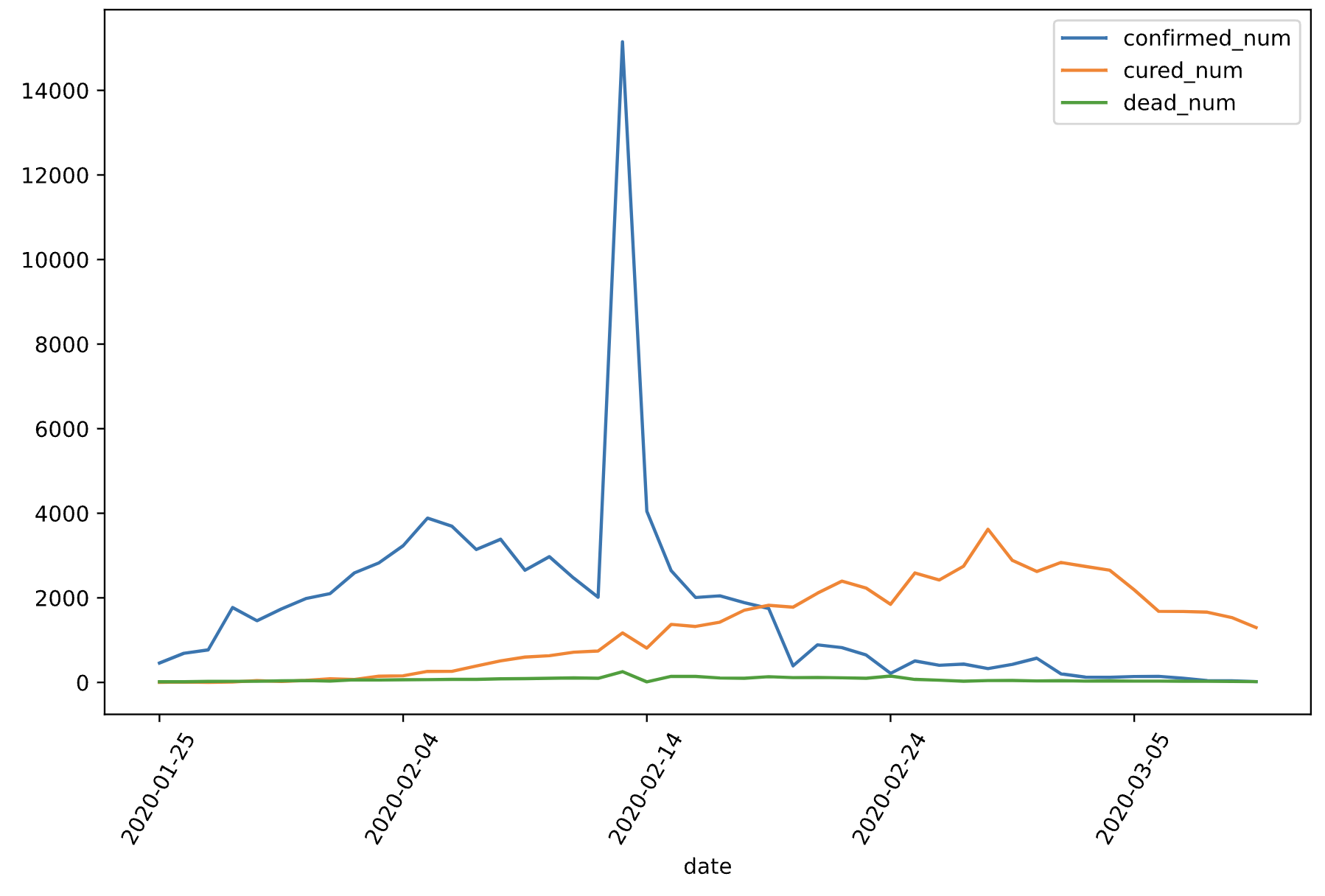
dfdata = df.set_index("date")dfdiff = dfdata.diff(periods=1).dropna()dfdiff = dfdiff.reset_index("date")dfdiff.plot(x = "date",y = ["confirmed_num","cured_num","dead_num"],figsize=(10,6))plt.xticks(rotation=60)dfdiff = dfdiff.drop("date",axis = 1).astype("float32")
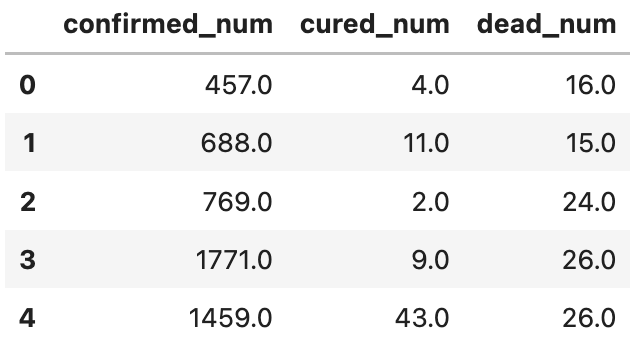
dfdiff.head()
下面我们通过继承torch.utils.data.Dataset实现自定义时间序列数据集。
torch.utils.data.Dataset是一个抽象类,用户想要加载自定义的数据只需要继承这个类,并且覆写其中的两个方法即可:
__len__:实现len(dataset)返回整个数据集的大小。__getitem__:用来获取一些索引的数据,使dataset[i]返回数据集中第i个样本。
不覆写这两个方法会直接返回错误。
import torchfrom torch import nnfrom torch.utils.data import Dataset,DataLoader,TensorDataset#用某日前8天窗口数据作为输入预测该日数据WINDOW_SIZE = 8class Covid19Dataset(Dataset):def __len__(self):return len(dfdiff) - WINDOW_SIZEdef __getitem__(self,i):x = dfdiff.loc[i:i+WINDOW_SIZE-1,:]feature = torch.tensor(x.values)y = dfdiff.loc[i+WINDOW_SIZE,:]label = torch.tensor(y.values)return (feature,label)ds_train = Covid19Dataset()#数据较小,可以将全部训练数据放入到一个batch中,提升性能dl_train = DataLoader(ds_train,batch_size = 38)
定义模型
使用Pytorch通常有三种方式构建模型:
- 使用nn.Sequential按层顺序构建模型;
- 继承nn.Module基类构建自定义模型;
- 继承nn.Module基类构建模型并辅助应用模型容器进行封装。
此处选择第二种方式构建模型。由于接下来使用类形式的训练循环,我们进一步将模型封装成torchkeras中的Model类来获得类似Keras中高阶模型接口的功能。Model类实际上继承自nn.Module类。
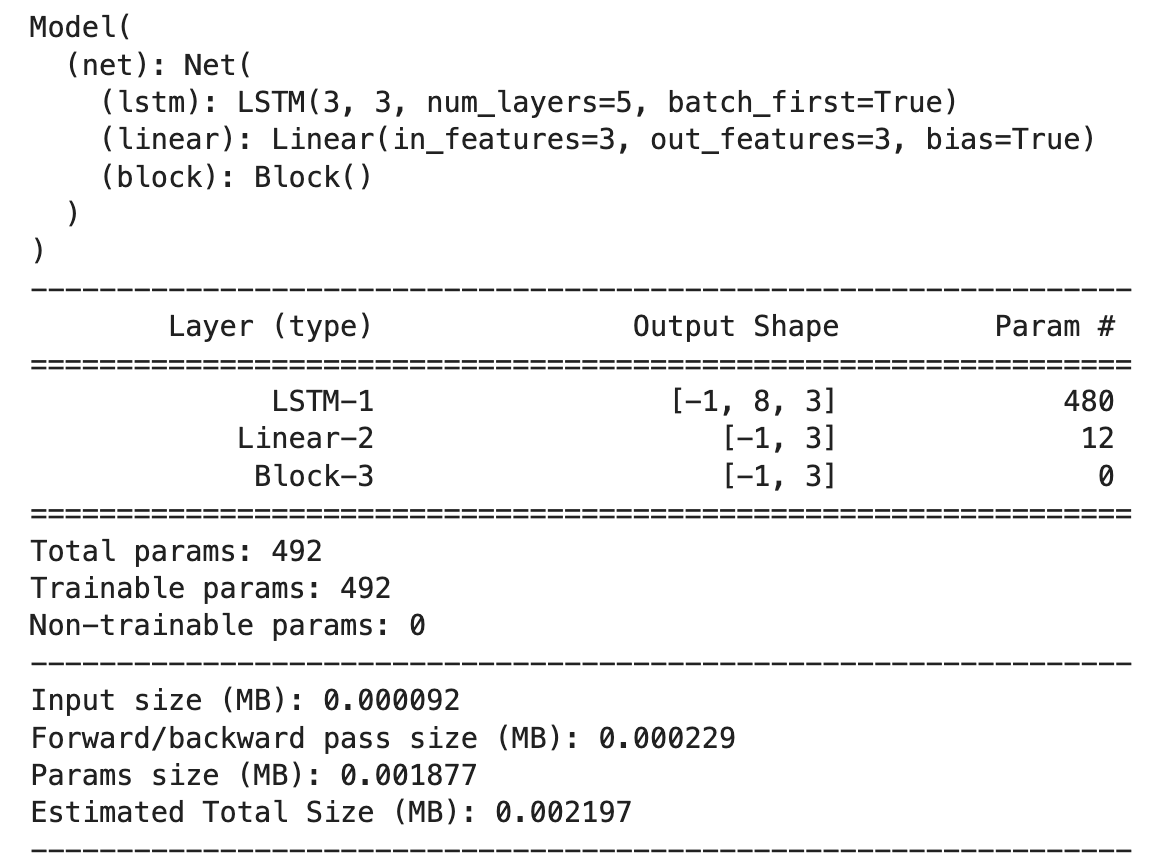
import torchfrom torch import nnimport importlibimport torchkerastorch.random.seed()class Block(nn.Module):def __init__(self):super(Block,self).__init__()def forward(self,x,x_input):x_out = torch.max((1+x)*x_input[:,-1,:],torch.tensor(0.0))return x_outclass Net(nn.Module):def __init__(self):super(Net, self).__init__()# 3层lstmself.lstm = nn.LSTM(input_size = 3,hidden_size = 3,num_layers = 5,batch_first = True)self.linear = nn.Linear(3,3)self.block = Block()def forward(self,x_input):x = self.lstm(x_input)[0][:,-1,:]x = self.linear(x)y = self.block(x,x_input)return ynet = Net()model = torchkeras.Model(net)print(model)model.summary(input_shape=(8,3),input_dtype = torch.FloatTensor)
训练模型
训练Pytorch通常需要用户编写自定义训练循环,训练循环的代码风格因人而异。
有3类典型的训练循环代码风格:
- 脚本形式训练循环;
- 函数形式训练循环;
- 类形式训练循环。
此处介绍一种类形式的训练循环。我们仿照Keras定义了一个高阶的模型接口Model,实现 fit, validate,predict, summary 方法,相当于用户自定义高阶API。
注:循环神经网络调试较为困难,需要设置多个不同的学习率多次尝试,以取得较好的效果。
def mspe(y_pred,y_true):err_percent = (y_true - y_pred)**2/(torch.max(y_true**2,torch.tensor(1e-7)))return torch.mean(err_percent)model.compile(loss_func = mspe,optimizer = torch.optim.Adagrad(model.parameters(),lr = 0.1))
dfhistory = model.fit(100,dl_train,log_step_freq=10)
评估模型
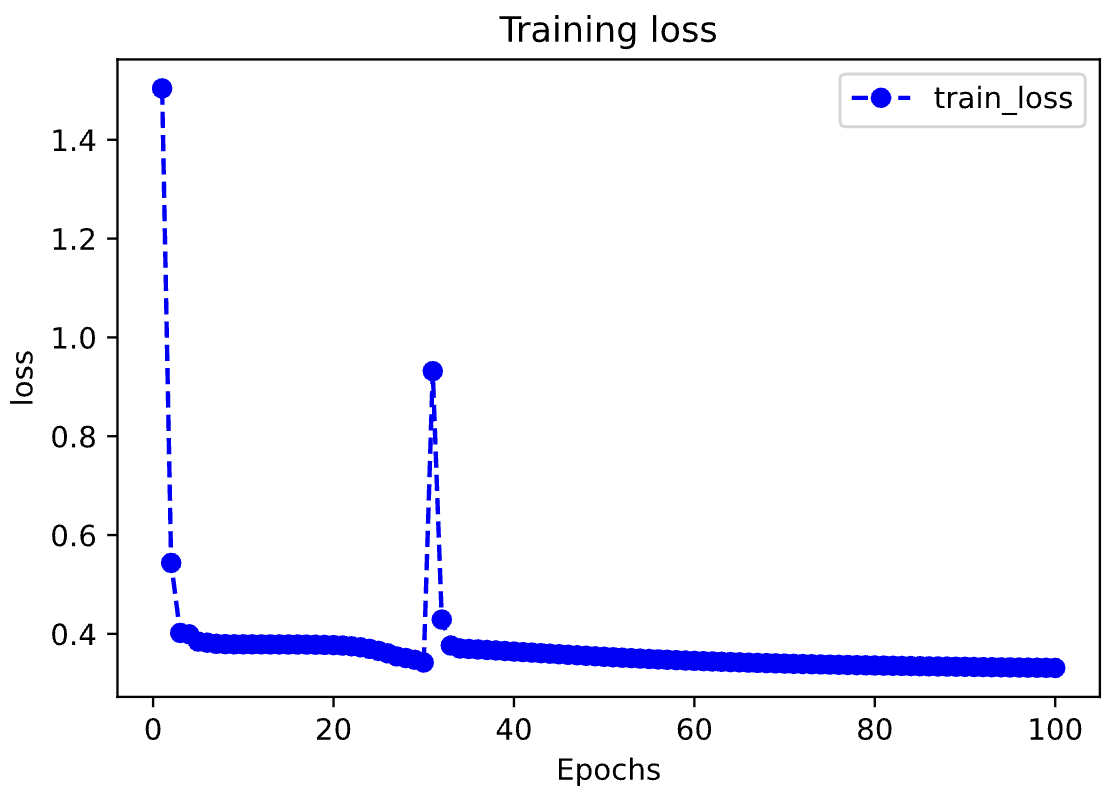
评估模型一般要设置验证集或者测试集,由于此例数据较少,我们仅仅可视化损失函数在训练集上的迭代情况。
%matplotlib inline%config InlineBackend.figure_format = 'svg'import matplotlib.pyplot as pltdef plot_metric(dfhistory, metric):train_metrics = dfhistory[metric]epochs = range(1, len(train_metrics) + 1)plt.plot(epochs, train_metrics, 'bo--')plt.title('Training '+ metric)plt.xlabel("Epochs")plt.ylabel(metric)plt.legend(["train_"+metric])plt.show()plot_metric(dfhistory,"loss")
使用模型
此处我们使用模型预测疫情结束时间,即 新增确诊病例为0 的时间。
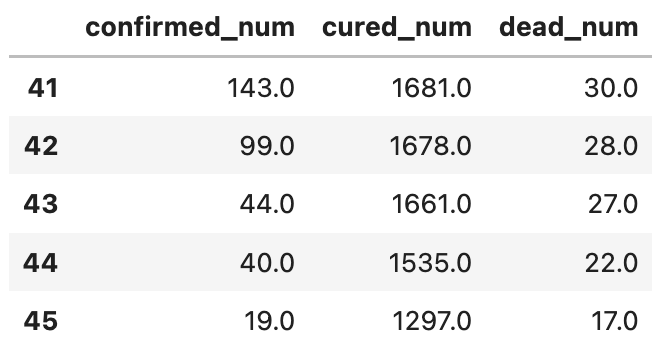
#使用dfresult记录现有数据以及此后预测的疫情数据dfresult = dfdiff[["confirmed_num","cured_num","dead_num"]].copy()dfresult.tail()
#预测此后500天的新增走势,将其结果添加到dfresult中for i in range(500):arr_input = torch.unsqueeze(torch.from_numpy(dfresult.values[-38:,:]),axis=0)arr_predict = model.forward(arr_input)dfpredict = pd.DataFrame(torch.floor(arr_predict).data.numpy(),columns = dfresult.columns)dfresult = dfresult.append(dfpredict,ignore_index=True)
dfresult.query("confirmed_num==0").head()# 第50天开始新增确诊降为0,第45天对应3月10日,也就是5天后,即预计3月15日新增确诊降为0# 注:该预测偏乐观
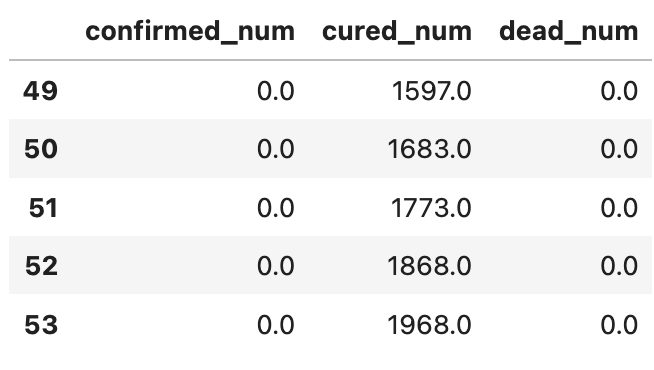
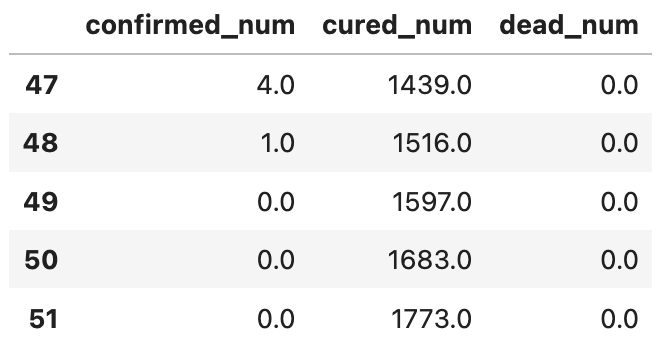
dfresult.query("cured_num==0").head()# 第365天开始新增治愈降为0,即大概1年后。# 注: 该预测偏悲观,并且存在问题,如果将每天新增治愈人数加起来,将超过累计确诊人数。
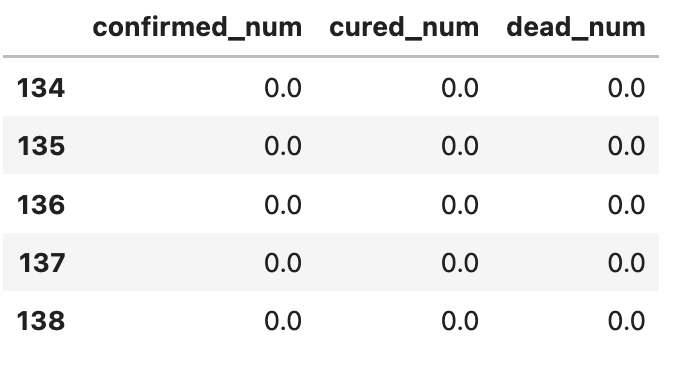
dfresult.query("dead_num==0").head()# 第54天开始新增确诊降为0# 注:该预测偏乐观
保存模型
推荐使用保存参数方式保存Pytorch模型。
print(model.net.state_dict().keys())

# 保存模型参数torch.save(model.net.state_dict(), "model/1_4_model_parameter.pkl")net_clone = Net()net_clone.load_state_dict(torch.load("model/1_4_model_parameter.pkl"))model_clone = torchkeras.Model(net_clone)model_clone.compile(loss_func = mspe)# 评估模型model_clone.evaluate(dl_train)


若有收获,就点个赞吧
0 人点赞
