
https://pytorch.org/docs/stable/nn.html
基本骨架
[Module](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module) |
Base class for all neural network modules. |
|---|---|
import torchfrom torch import nn# 简单的实现y=x+1模型class Module(nn.Module):def __init__(self):super().__init__()def forward(self, input):output = input + 1return outputmodule = Module()x = torch.tensor(1.0)output = module(x)print(output)
卷积层
卷积操作

import torchimport torch.nn.functional as Finput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]])kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]])input = torch.reshape(input, (1, 1, 5, 5))kernel = torch.reshape(kernel, (1, 1, 3, 3))print(input.shape)print(kernel.shape)output1 = F.conv2d(input, kernel, stride=1)print(output1)output2 = F.conv2d(input, kernel, stride=1)print(output2)
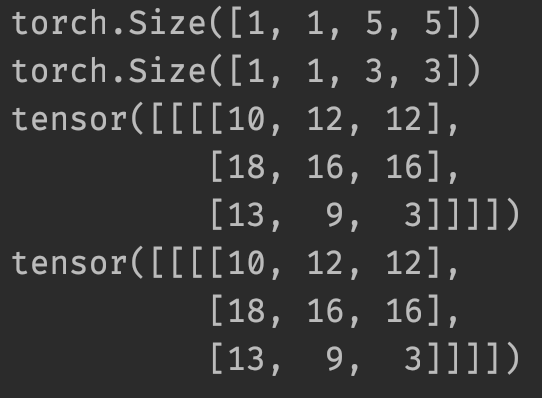
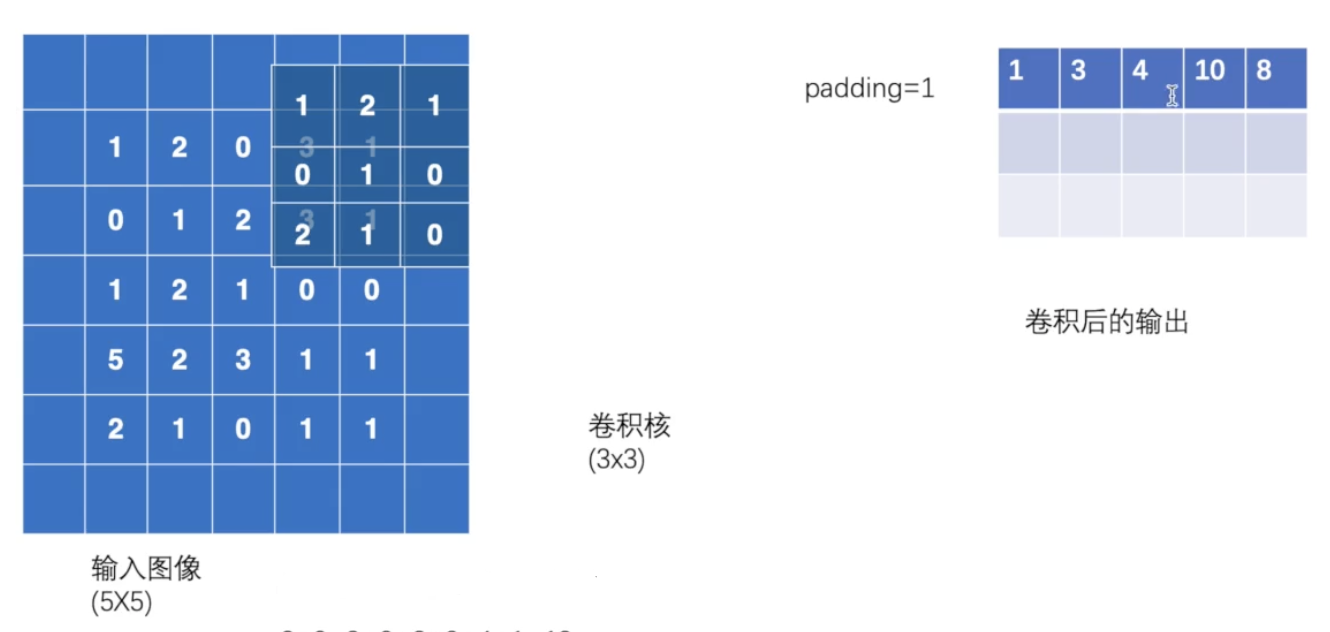
output3 = F.conv2d(input, kernel, stride=1, padding=1)print(output3)

Conv2d的使用

*out_channel=2:生成两个卷积核,分别对输入进行卷积操作,然后生成两个输出。
import torchimport torchvisionfrom torch import nnfrom torch.nn import Conv2dfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(dataset, batch_size=64)class Module(nn.Module):def __init__(self):super(Module, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return xmodule = Module()print(module)writer = SummaryWriter("log")step = 0for data in dataloader:imgs, targets = dataoutput = module(imgs)print(imgs.shape)print(output.shape)# torch.Size([64, 3, 32, 32])writer.add_images("input", imgs, step)# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]output = torch.reshape(output, (-1, 3, 30, 30))writer.add_images("output", output, step)step = step + 1writer.close()
池化层
https://pytorch.org/docs/stable/nn.html#pooling-layers
最大池化目的是保留数据的特征,但使数据量减小,减少运算量。
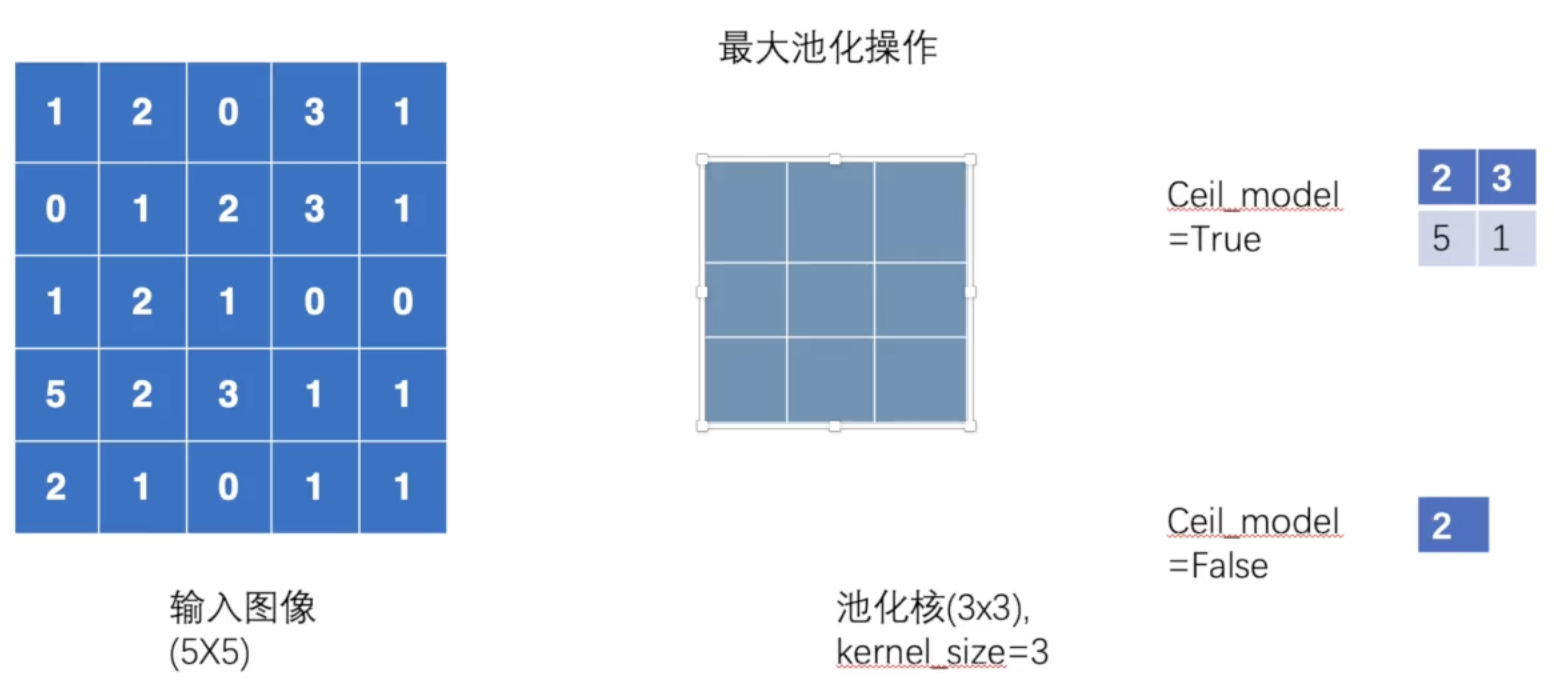
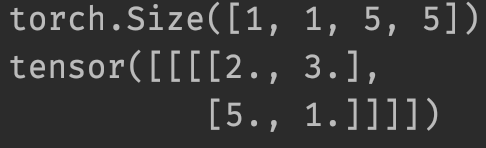
import torchfrom torch import nnfrom torch.nn import MaxPool2dinput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)input = torch.reshape(input, (-1, 1, 5, 5))print(input.shape)class Module(nn.Module):def __init__(self):super(Module, self).__init__()self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, input):output = self.maxpool1(input)return outputmodule = Module()output = module(input)print(output)
import torchimport torchvision.datasetsfrom torch import nnfrom torch.nn import MaxPool2dfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterclass Module(nn.Module):def __init__(self):super(Module, self).__init__()self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, input):output = self.maxpool1(input)return outputmodule = Module()dataset = torchvision.datasets.CIFAR10("dataset", train=False, download=True,transform=torchvision.transforms.ToTensor())dataloader = DataLoader(dataset, batch_size=64)writer = SummaryWriter("log")step = 0for data in dataloader:imgs, targets = datawriter.add_images("maxpool_input", imgs, step)output = module(imgs)writer.add_images("maxpool_output", output, step)step = step + 1writer.close()

非线性激活
https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
ReLU
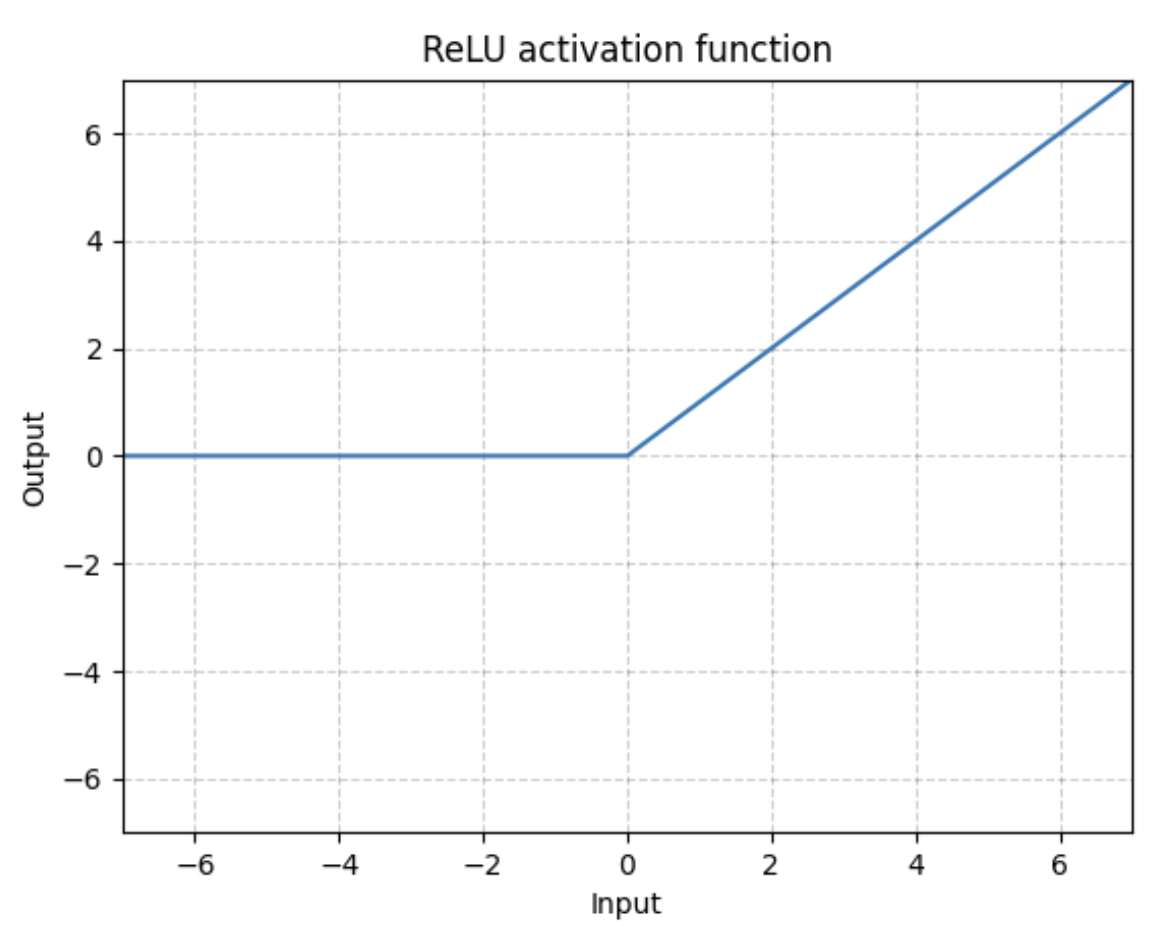

import torchfrom torch import nnfrom torch.nn import ReLUinput = torch.tensor([[1, -0.5],[-1, 3]])input = torch.reshape(input, (-1, 1, 2, 2))print(input)class Module(nn.Module):def __init__(self):super(Module, self).__init__()self.relu1 = ReLU()def forward(self, input):output = self.relu1(input)return outputmodule = Module()output = module(input)print(output)
Sigmoid
import torchimport torchvisionfrom torch import nnfrom torch.nn import ReLU, Sigmoidfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterclass Module(nn.Module):def __init__(self):super(Module, self).__init__()self.relu1 = ReLU()self.sigmoid1 = Sigmoid()def forward(self, input):output = self.sigmoid1(input)return outputmodule = Module()dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor())dataloader = DataLoader(dataset, batch_size=64)writer = SummaryWriter("log")step = 0for data in dataloader:imgs, targets = datawriter.add_images("sigmoid_input", img_tensor=imgs, global_step=step)output = module(imgs)writer.add_images("sigmoid_output", img_tensor=output, global_step=step)step = step + 1writer.close()

线性层
- in_features – size of each input sample
- out_features – size of each output sample
- bias – If set to
False, the layer will not learn an additive bias. Default:True
import torchimport torchvisionfrom torch import nnfrom torch.nn import Linearfrom torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(dataset, batch_size=64, drop_last=True)class Module(nn.Module):def __init__(self):super(Module, self).__init__()self.linear1 = Linear(196608, 10)def forward(self, input):output = self.linear1(input)return outputmodule = Module()for data in dataloader:imgs, targets = dataprint(imgs.shape)# output = torch.reshape(imgs, (1, 1, 1, -1))output = torch.flatten(imgs)print(output.shape)output = module(output)print(output.shape)
Sequential使用例子

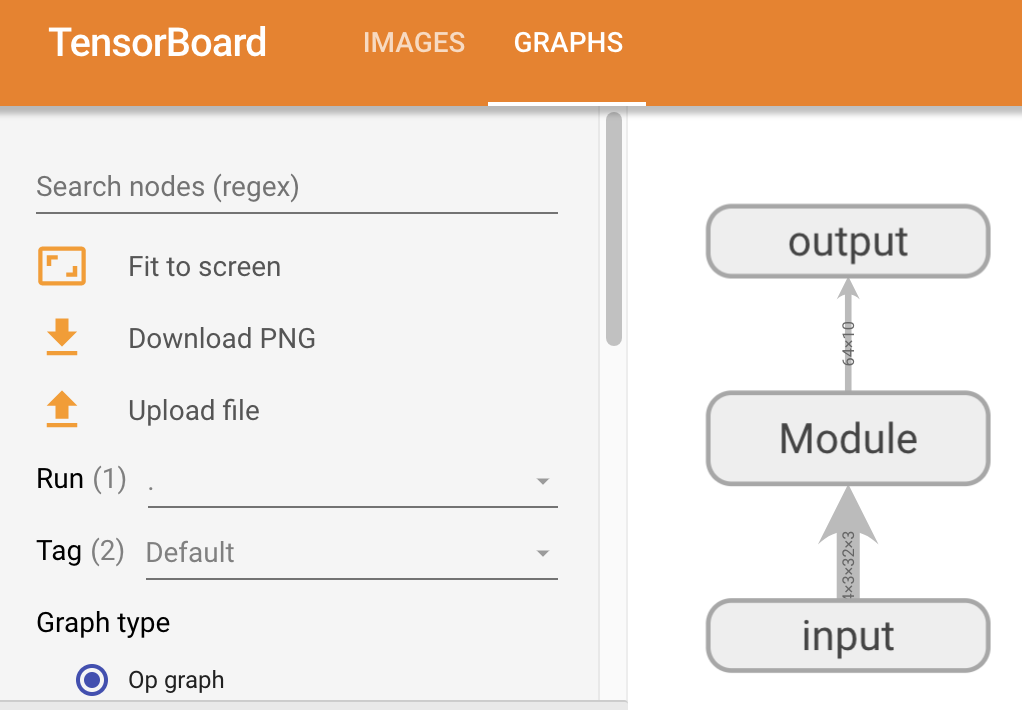
import torchfrom torch import nnfrom torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequentialfrom torch.utils.tensorboard import SummaryWriterclass Module(nn.Module):def __init__(self):super(Module, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)self.maxpool1 = MaxPool2d(kernel_size=2)self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)self.maxpool2 = MaxPool2d(kernel_size=2)self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)self.maxpool3 = MaxPool2d(kernel_size=2)self.flatten = Flatten()self.linear1 = Linear(in_features=1024, out_features=64)self.linear2 = Linear(in_features=64, out_features=10)self.module1 = Sequential(Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Flatten(),Linear(in_features=1024, out_features=64),Linear(in_features=64, out_features=10))def forward(self, x):# x = self.conv1(x)# x = self.maxpool1(x)# x = self.conv2(x)# x = self.maxpool2(x)# x = self.conv3(x)# x = self.maxpool3(x)# x = self.flatten(x)# x = self.linear1(x)# x = self.linear2(x)x = self.module1(x) # 替代上述代码return xmodule = Module()print(module)input = torch.ones((64, 3, 32, 32))output = module(input)print(output.shape) # 验证网络参数的正确性

# 可视化模型writer = SummaryWriter("log")writer.add_graph(module, input)writer.close()
损失函数

L1loss

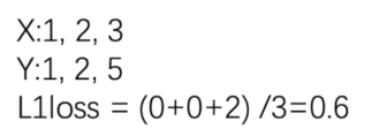
import torchfrom torch.nn import L1Lossinputs = torch.tensor([1, 2, 3], dtype=torch.float32)targets = torch.tensor([1, 2, 5], dtype=torch.float32)inputs = torch.reshape(inputs, (1, 1, 1, 3))targets = torch.reshape(targets, (1, 1, 1, 3))loss = L1Loss() # 默认mean# loss = L1Loss(reduction='sum')result = loss(inputs, targets)print(result)
MSELoss
均方差
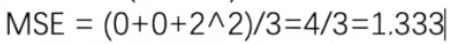
loss_mse = MSELoss()result_mse = loss_mse(inputs, targets)print(result_mse)
CrossEntropyLoss
交叉墒(适合分类问题)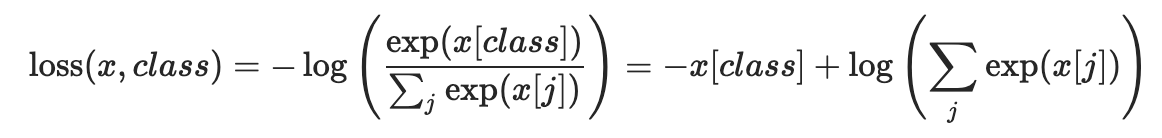
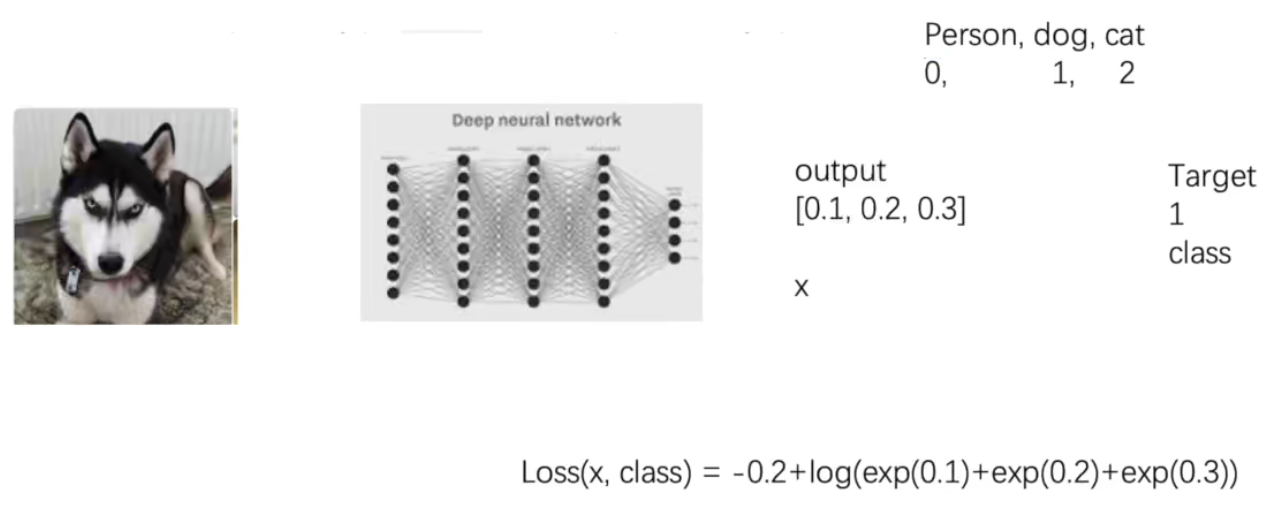
x = torch.tensor([0.1, 0.2, 0.3])y = torch.tensor(([1]))x = torch.reshape(x, (1, 3))loss_cross = nn.CrossEntropyLoss()result_cross = loss_cross(x, y)print(result_cross)
优化Sequential使用例子,加入损失函数
import torchvision.datasetsfrom torch import nnfrom torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequentialfrom torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(dataset, batch_size=1)class Module(nn.Module):def __init__(self):super(Module, self).__init__()self.module1 = Sequential(Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Flatten(),Linear(in_features=1024, out_features=64),Linear(in_features=64, out_features=10))def forward(self, x):x = self.module1(x)return xmodule = Module()loss = nn.CrossEntropyLoss()for data in dataloader:imgs, targets = dataoutputs = module(imgs)# print(outputs)# print(targets)result_loss = loss(outputs, targets)result_loss.backward()print(result_loss)
优化器
https://pytorch.org/docs/stable/optim.html
import torch.optimimport torchvisionfrom torch import nnfrom torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequentialfrom torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(dataset, batch_size=1)class Module(nn.Module):def __init__(self):super(Module, self).__init__()self.module1 = Sequential(Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),MaxPool2d(kernel_size=2),Flatten(),Linear(in_features=1024, out_features=64),Linear(in_features=64, out_features=10))def forward(self, x):x = self.module1(x)return xmodule = Module()loss = nn.CrossEntropyLoss()optim = torch.optim.SGD(module.parameters(), lr=0.01)for epoch in range(20):running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = module(imgs)result_loss = loss(outputs, targets)optim.zero_grad()result_loss.backward()optim.step()running_loss = running_loss + result_lossprint(running_loss)


若有收获,就点个赞吧
0 人点赞
