seq2seq含义
输入一个序列,机器输出另一个序列,长度由机器决定。
文本翻译:文本至文本; 语音识别:语音至文本; 语音合成:文本至语音; 聊天机器人:语音至语音。
采用该模型训练时,不考虑背景音乐、杂讯、音标等其他干扰因素,俗称硬train一发。
seq2seq应用
- 大多数自然语言处理(NLP问题)可以通过seq2seq解决,但不见得是最佳的方法。
- 应用于文法剖析,下图中的小括号用来表示树状结构!(NP名词,ADJV形容词,VP动词)
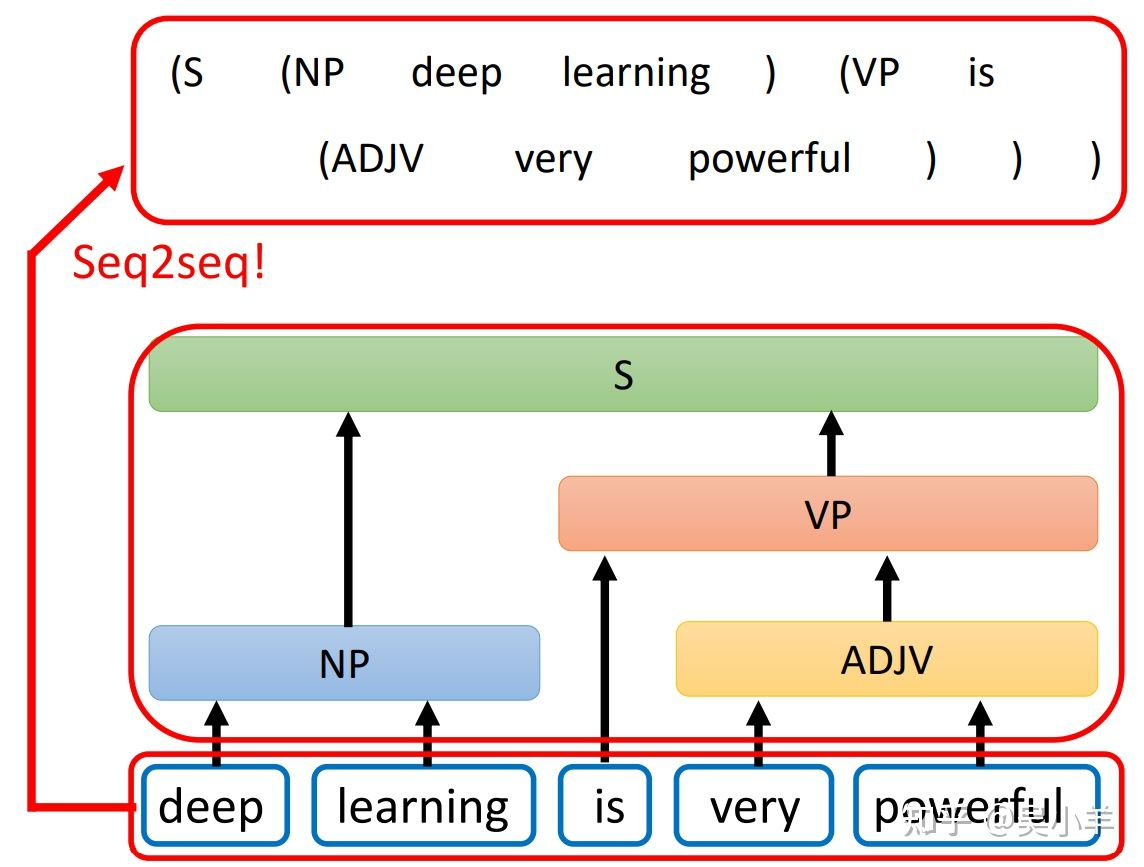
- 应用于multi-label classification(多标签分类问题:同一个对象可以属于多个class)。

⚠️区分于multi-class classfication(多类别分类问题:从多个class中选出一个class)。
seq2seq实现
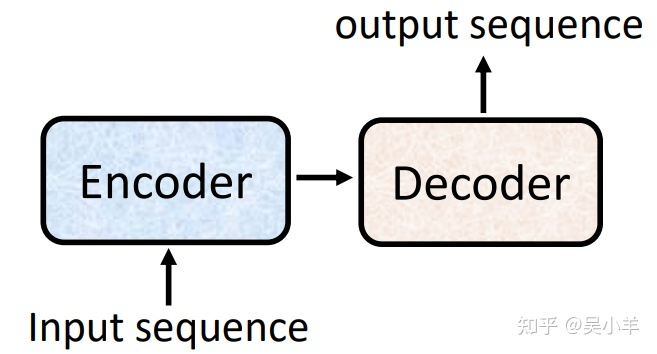
seq2seq由encoder(编码器)和decoder(解码器)组成,过程如图。这两部分可以使用RNN或transformer实现,seq2seq主要是为了解决输入和输出长度不确定的情况。
- encoder:将输入(文字、语音、视频等)编码为单个向量,这个向量可以看成是全部输入的抽象表示。
- decoder:接受encoder输出的向量,逐步解码,一次输出一个结果,每次输出会影响下一次的输出,开头加入
表示开始解码, 表示输出结束。
encoder
- encoder就是通过多层block(模块),将输入转换成向量。每一个block又包括self-attention和fully connect等网络结构。

- 下图是单个block中的内部细节构成。是考虑所有输入向量后的输出向量,b是原来的输入向量,经过残差网络和标准化后,送到完全连接神经网络,再经过残差网络和标准化后得到输出。⚠️注意:这里的标准化是layer norm而不是batch norm。
batch normalization:对不同的example不同feature的同一个dimention去计算平均值和标准差。
layer normalization:对同一个example中同一个feature的不同dimention去计算平均值和标准差。

- transformer的encoder,下图结合上图理解。
下图中的multi-head attention 就是self-attention的别称;BERT使用的网络结构和transformer encoder一样。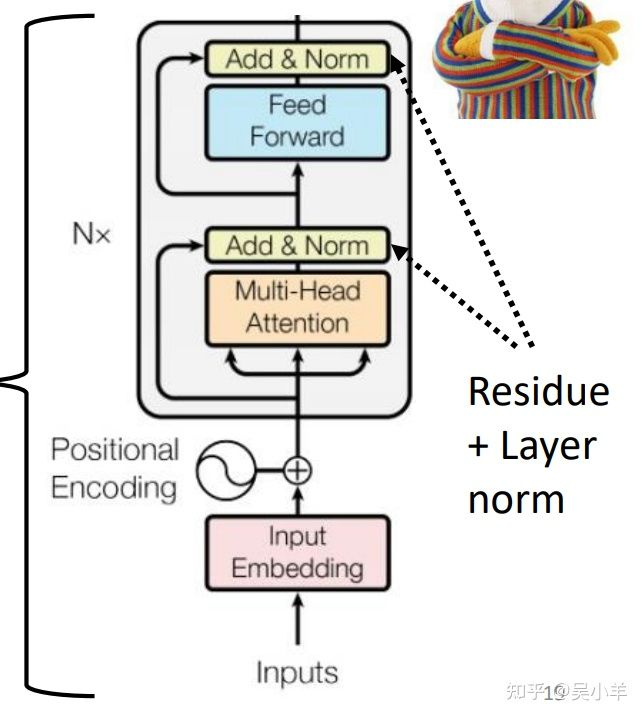
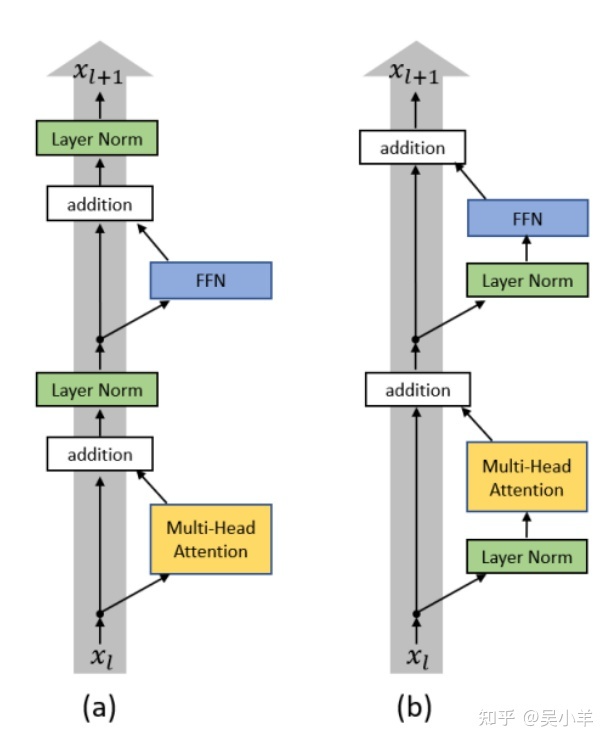
- transformer的encoder的改进措施:改变layer norm的使用位置。
decoder的实现
decoder主要有两种:AT(autoregressive)与NAT(non-autoregressive)。
AT(autoregressive)
以语音辨识为例,通过一个one-hot vector作为启动向量,接受encoder输出的向量,经过解码器和softmax之后得到一个向量。再对比已知字体库,相似度最高的就是最后输出的字体。再把自己的输出当做下一个的输入。


decoder与encoder的区别:
- encoder是采用self-attention,而decoder是采用masked self-attention。
- decoder多一层self-attention,而且多出来的这层有两个输入来自encoder,一个输入来自decoder前面网络的输出。

self-attention和masked self-attention的区别:
- self-attention中的b1、b2、b3、b4分别都接受a1,a2,a3,a4所有的资讯;
- masked self-attention中的b1只接受a1的资讯,b2只接受a1、a2的资讯,b3只接受a1、a2、a3的资讯,b4接受a1,a2,a3,a4的资讯。所以在decoder里面使用masked self-attention的原因是一个接一个输入,输入了a1才会产生b1即a2,所以在计算b1的时候还没有a2、a3、a4。


在已知的字体库中加入一个结束的标志,这样才能使得解码过程结束。所以在decoder中包括启动向量和结束向量。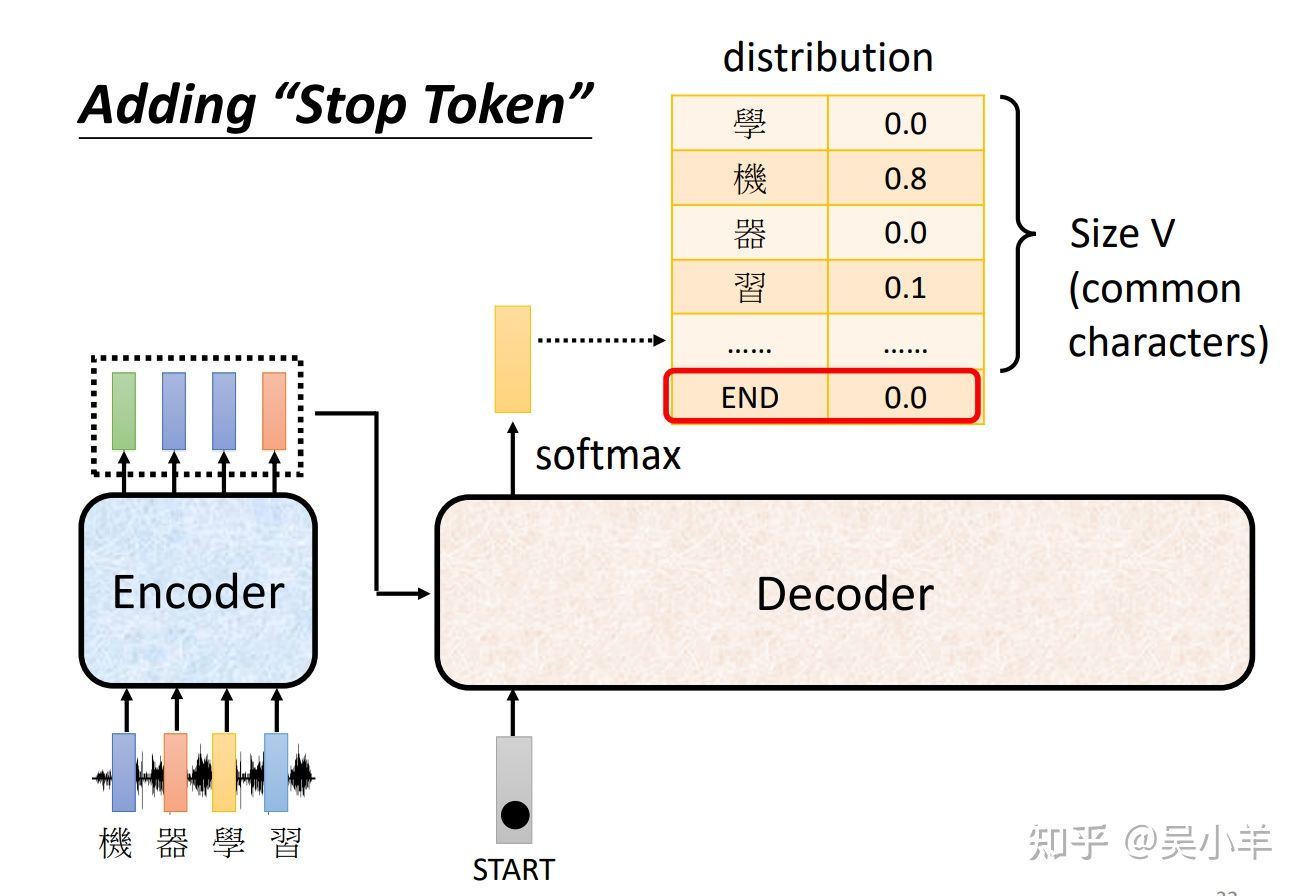

NAT(non-autoregressive)
AT只有一个启动向量,需要多个步骤才能完成解码;NAT有多个启动向量,只需要一个步骤就能完成解码。
我们不知道输出长度,那怎么确定NAT的输出长度,放多少个BOS呢?答:方法一是用其他的预测模型预测输出长度,方法二是放很多个BOS,输出很长的序列,在end之后的字体就忽略掉。
NAT是平行化的,输出长度可控,比AT更加稳定。
NAT的效果比AT差,因为multi-modality(多通道)。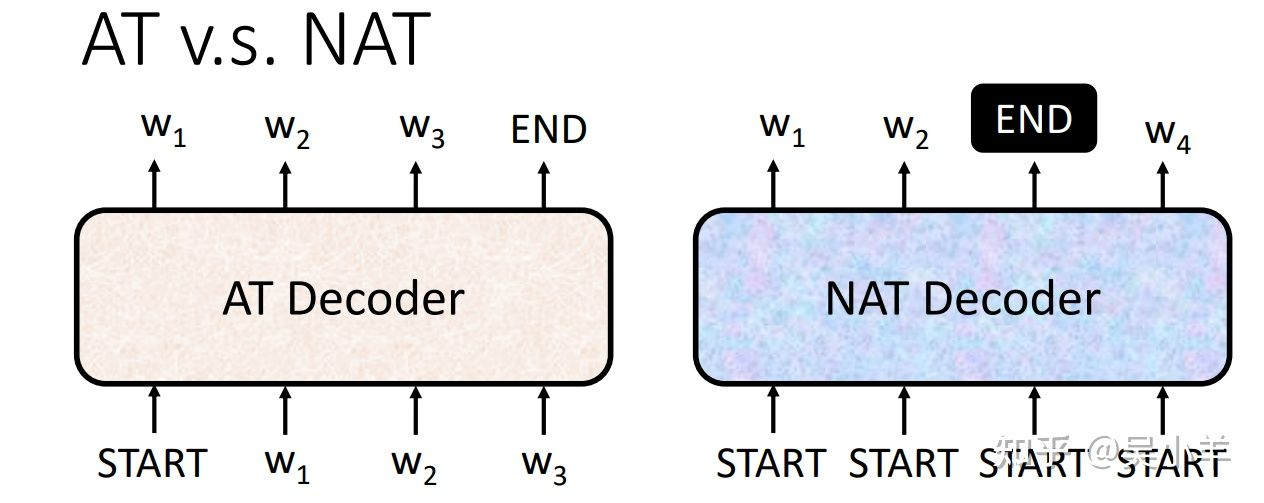

若有收获,就点个赞吧
0 人点赞
