Classification as Regression?
分类是怎麼做的呢?我们已经讲了,Regression就是输入一个向量,然后输出一个数值,我们希望输出的数值跟某一个label,也就是我们要学习的目标,越接近越好,这门课里面,如果是正确的答案就有加Hat,Model的输出没有加Hat。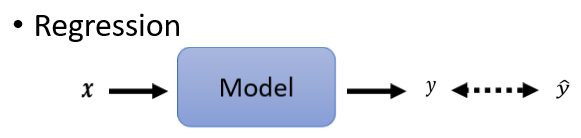
有一个可能,假设你会用Regression的话,我们其实可以把Classification,当作是Regression来看。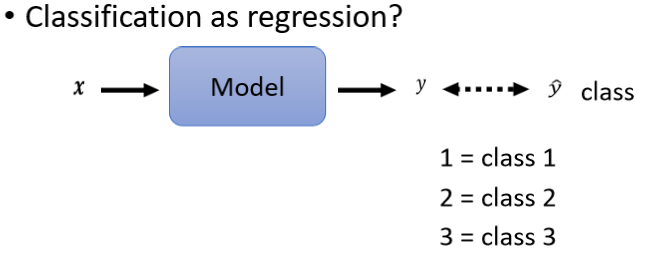
这个方法不一定是个好方法,这是一个比较奇妙的方法,输入一个东西以后,我们的输出仍然是一个scaler,它叫做y 然后这一个y,我们要让它跟正确答案,那个Class越接近越好,但是y是一个数字,我们怎麼让它跟Class越接近越好呢,我们必须把Class也变成数字。
Class as one-hot vector
当你在做分类的问题的时候,比较常见的做法是把你的Class,用 One-hot vector来表示。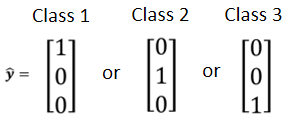

如果我们今天的目标y hat是一个向量 比如说,ŷ是有三个element的向量,那我们的network,也应该要Output的维度也是三个数字才行。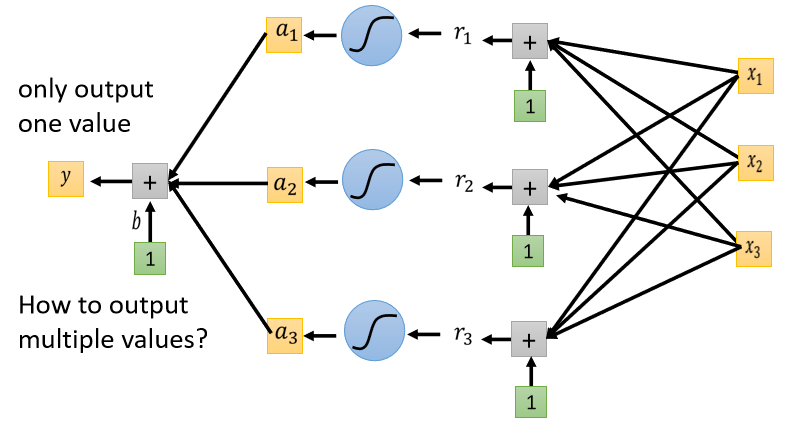
到目前為止我们讲的network,其实都只Output一个数值,因為我们过去做的都是Regression的问题,所以只Output一个数字。其实从一个数值改到三个数值,它是没有什麼不同的。你可以Output一个数值,你就可以Output三个数值,所以把本来Output一个数值的方法,重复三次。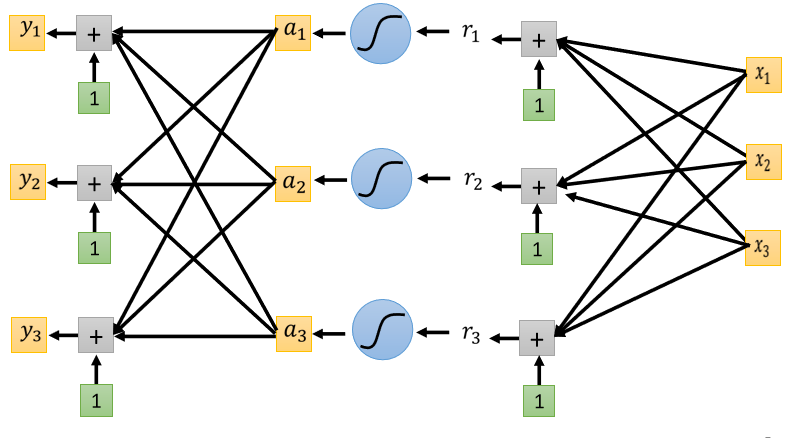
- 把a₁ a₂ a₃,乘上三个不同的Weight 加上bias,得到y₁
- 再把a₁ a₂ a₃乘上另外三个Weight,再加上另外一个bias得到y₂
- 再把a₁ a₂ a₃再乘上另外一组Weight,再加上另外一个bias得到y₃
你就可以產生三组数字,所以你就可以Input一个feature的Vector,然后產生y₁ y₂ y₃,然后希望y₁ y₂ y₃,跟我们的目标越接近越好。
Classification with softmax
那所以我们现在,知道了Regression是怎麼做的,Input x Output y 要跟 label ŷ,越接近越好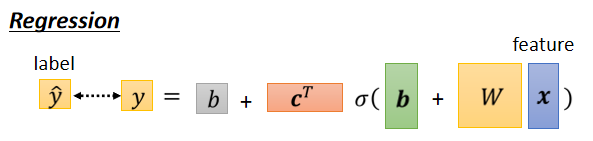
如果是Classification,input x可能乘上一个W,再加上b。再通过activation function,再乘上W’再加上b’ 得到y,我们现在的y它不是一个数值,它是一个向量。
但是在做Classification的时候,我们往往会把y再通过一个叫做Soft-max的function得到y’,然后我们才去计算,y’跟y hat之间的距离。
这个ŷ 它裡面的值,都是0跟1,它是One-hot vector,所以裡面的值只有0跟1,但是y裡面有任何值。
既然我们的目标只有0跟1,但是y有任何值,我们就先把它Normalize到0到1之间,这样才好跟 label 的计算相似度,这是一个比较简单的讲法。
Softmax
这个是Soft-max的block,输入y₁ y₂ y₃,它会產生y₁’ y₂’ y₃’。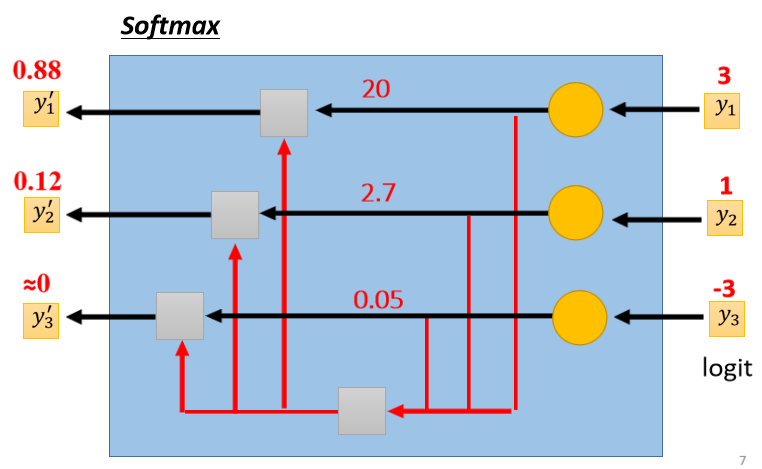
有了Softmax这个式子以后,你就会发现。
- y₁’ y₂’ y₃’,它们都是介於0到1之间
- y₁’ y₂’ y₃’,它们的和是1
所以这个Soft-max它要做的事情,除了Normalized,让 y₁’ y₂’ y₃’,变成0到1之间,还有和為1以外,它还有一个附带的效果是,它会让大的值跟小的值的差距更大。
当两个class用sigmoid,跟soft-max两个class,会发现说这两件事情是等价的。
Loss of Classification

我们把x,丢到一个Network裡面產生y以后,我们会通过soft-max得到y’,再去计算y’跟ŷ之间的距离,这个写作е。
计算y’跟ŷ之间的距离不只一种做法,举例来说,如果我喜欢的话,我要让这个距离是Mean Square Error。
但是有另外一个更常用的做法,叫做Cross-entropy。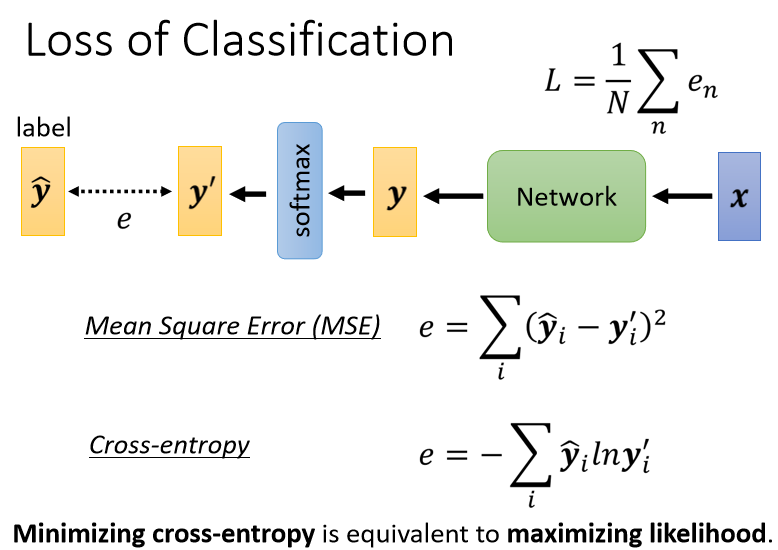
所以如果有一天有人问你说,如果我们今天在做分类问题的时候,maximize likelihood跟Minimize Cross-entropy,有什麼关係的时候,不要回答说它们其实很像,它们两个就是一模一样的东西,只是同一件事不同的讲法而已。
在pytorch裡面,Cross-entropy跟Soft-max,他们是被绑在一起的,他们是一个Set,你只要Copy Cross-entropy,裡面就自动内建了Soft-max。
那我们就是举一个例子来告诉你说,為什麼是Cross-entropy比较好。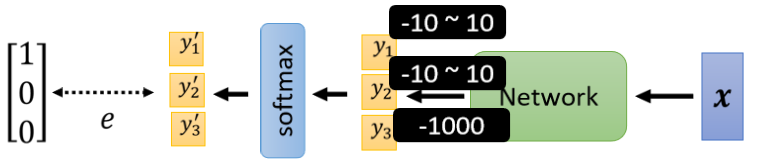
那现在我们要做一个3个Class的分类。Network先输出y₁ y₂ y₃,在通过soft-max以后,產生y₁’ y₂’跟y₃’。那接下来假设我们的正确答案就是100,我们要去计算100这个向量,跟y₁’ y₂’跟y₃’他们之间的距离,那这个距离我们用е来表示,е可以是Mean square error,也可以是Cross-entropy。我们现在假设y₁的变化是从-10到10,y₂的变化也是从-10到10,y₃我们就固定设成-1000。因為y₃设很小,所以过soft-max以后y₃’就非常趋近於0,它跟正确答案非常接近,且它对我们的结果影响很少。总之我们y₃设一个定值,我们只看跟有变化的时候,对我们的e对我们的Loss对我们loss有什麼样的影响。
那我们看一下如果我们这个e,设定為Mean Square Error,跟Cross-entropy的时候,算出来的Error surface会有什麼样,不一样的地方。底下这两个图,就分别在我们e是Mean square error,跟Cross-entropy的时候,y₁ y₂的变化对loss的影响,对Error surface的影响。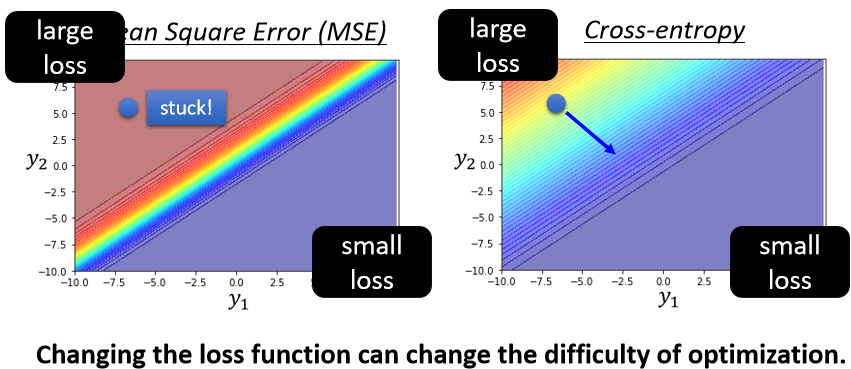
我们这边是用红色代表Loss大,蓝色代表Loss小
- 那如果今天y₁很大 y₂很小,就代表y₁’会很接近1,y₂’会很接近0,所以不管是对Mean Square Error,或是Cross-entropy而言,y₁大 y₂小的时候 Loss都是小的。
- 如果y₁小 y₂大的话,这边y₁’就是0 y₂’就是1,所以这个时候Loss会比较大。
所以这两个图都是左上角Loss大,右下角Loss小,所以我们就期待说,我们最后在Training的时候,我们的参数可以走到右下角的地方
那假设我们开始的地方,都是左上角
- 如果我们选择Cross-Entropy,左上角这个地方,它是有斜率的,所以你有办法透过gradient,一路往右下的地方走,
- 如果你选Mean square error的话,你就卡住了,Mean square error在这种Loss很大的地方,它是非常平坦的,它的gradient是非常小趋近於0的,如果你初始的时候在这个地方,离你的目标非常远,那它gradient又很小,你就会没有办法用gradient descent,顺利的走到右下角的地方去,
所以你如果你今天自己在做classification,你选Mean square error的时候,你有非常大的可能性会train不起来,当然这个是在你没有好的optimizer的情况下,今天如果你用Adam,这个地方gradient很小,那gradient很小之后,它learning rate之后会自动帮你调大,也许你还是有机会走到右下角,不过这会让你的training,比较困难一点,让你training的起步呢,比较慢一点
所以这边有一个很好的例子,是告诉我们说,就算是Loss function的定义,都可能影响Training是不是容易这件事情,刚才说要用神罗天征,直接把error surface炸平,这边就是一个好的例子告诉我们说,你可以改Loss function,居然可以改变optimization的难度,

若有收获,就点个赞吧
0 人点赞
