视频:https://www.bilibili.com/video/BV1Wv411h7kN?p=70 笔记:https://zhuanlan.zhihu.com/p/403007845
supervised和self-supervised
supervised learning是需要有标签的资料的。
self-supervised learning不需要外界提供有标签的资料,他的带标签的资料源于自身。x分两部分,一部分用作模型的输入,另一部分作为y要学习的label资料。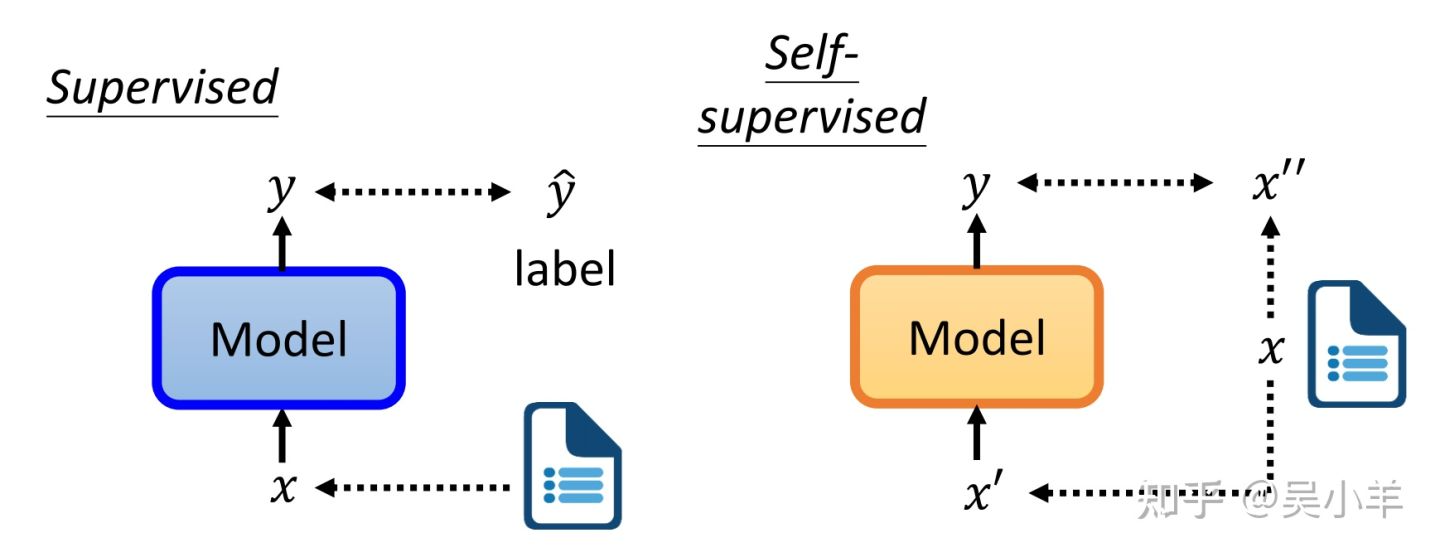
BERT self-supervised
- 方法1: masking input(随机遮盖一些输入单位)
- 使用特殊单位来代替原单位;
- 随机使用其他的单位来代替原单位。台大学就是x’(作为模型的输入),台湾大学等字体就是x’’(作为输出要学习的label资料)。
被遮盖的单位输出的向量经过linear(乘上一个矩阵),再经过softmax输出一个向量,去和所有的字体做对比,找出被遮盖的字最可能是什么字。对比的过程就是计算最小的cross entropy,就像做分类问题一样,经过softmax的输出向量和所有字体代表的单向量做计算。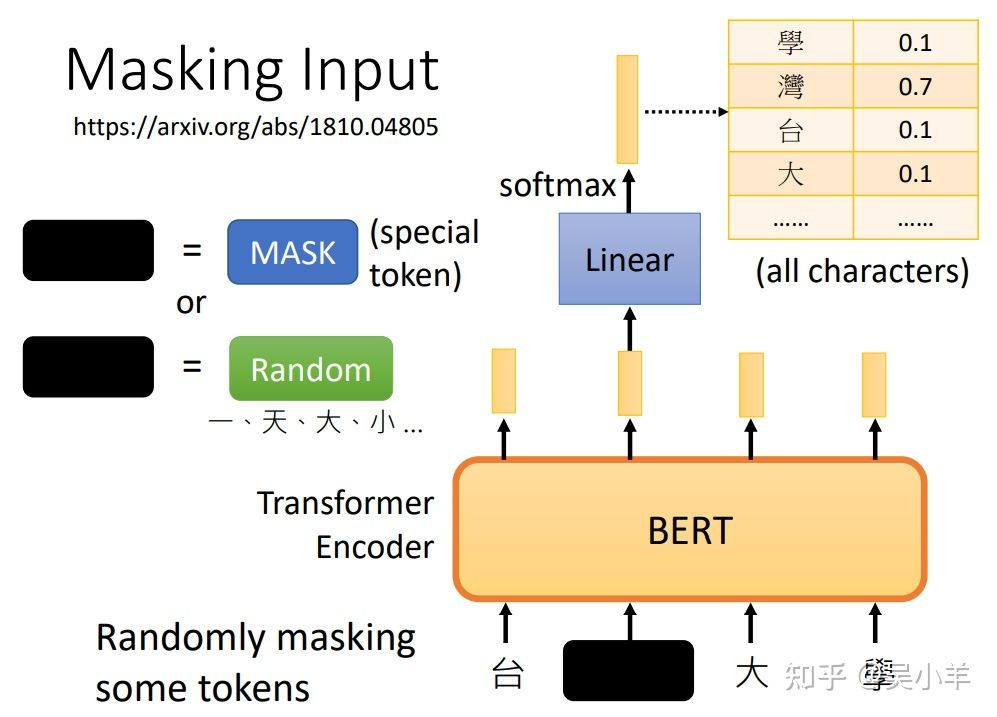
- 方法二:next sentence prediction(预测前后两个句子是否相接)
SEP用来分隔句子,这个方法只看CLS的输出,不看其他向量的输出。
CLS的输出经过和masking input一样的操作,来判断句子是否相接。但是有很多文献说这个方法对于预训练的效果并不是很大。有另外一招叫做SOP(预测两个句子谁在前谁在后),这招看起来更难,但是在文献上有用。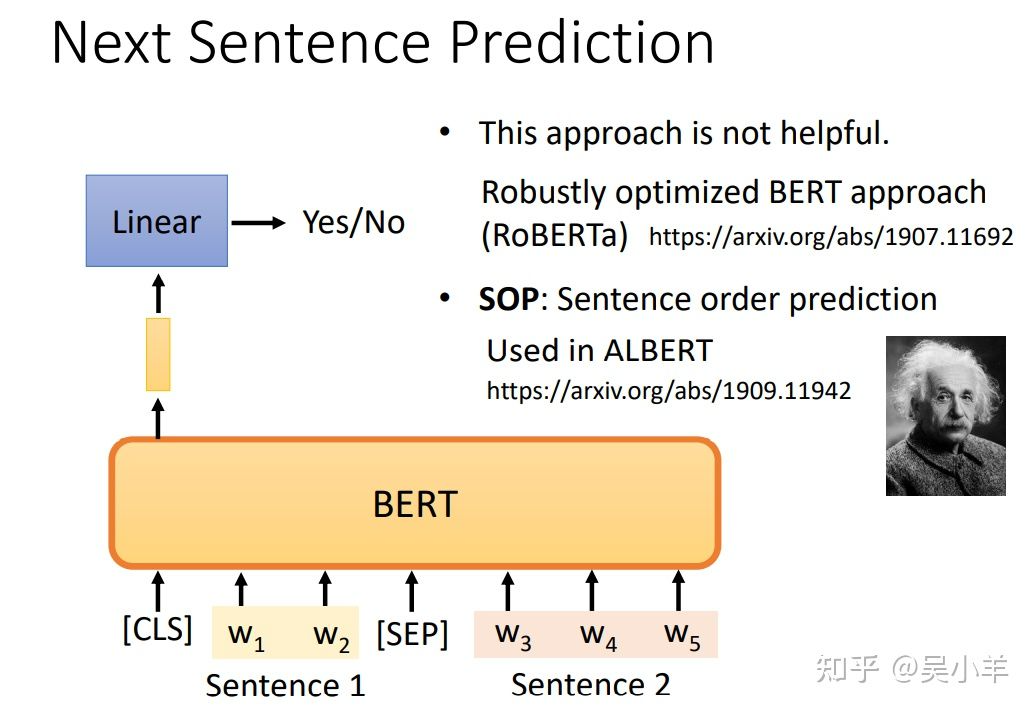
BERT框架概念
- 产生BERT的过程叫做Pre-train,该过程一般需要进行masking input 和next sentence prediction这两个操作。产生出来的BERT只会做填空题,BERT做过fine-tune(微调)之后才能做下游的各式各样的任务。
- pre-train过程是Self-supervised learning(资料来源于自身),fine-tune过程是supervised learning(有标注的资料),所以整个过程是semi-supervised(半监督)。
- 目前要pre-train一个能做填空题的BERT难度很大,一方面是数据量庞大,处理起来很艰难;另一方面是训练的过程需要很长的时间。

GLUE(测试BERT的能力)
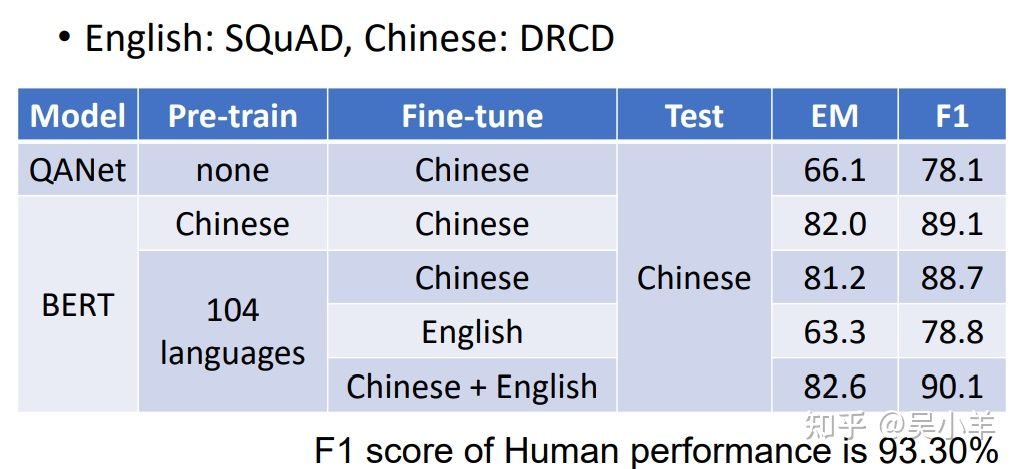
GLUE是自然语言处理任务,总共有九个任务。BERT分别微调之后做这9个任务,将9个测试分数做平均后代表BERT的能力高低。
BERT的应用
这四个案例的BERT都是经过pre-train的BERT,会做填空题了。也就是这个BERT的初始化参数来自学会填空题的BERT。主要关注四个案例的框图的区别!!!
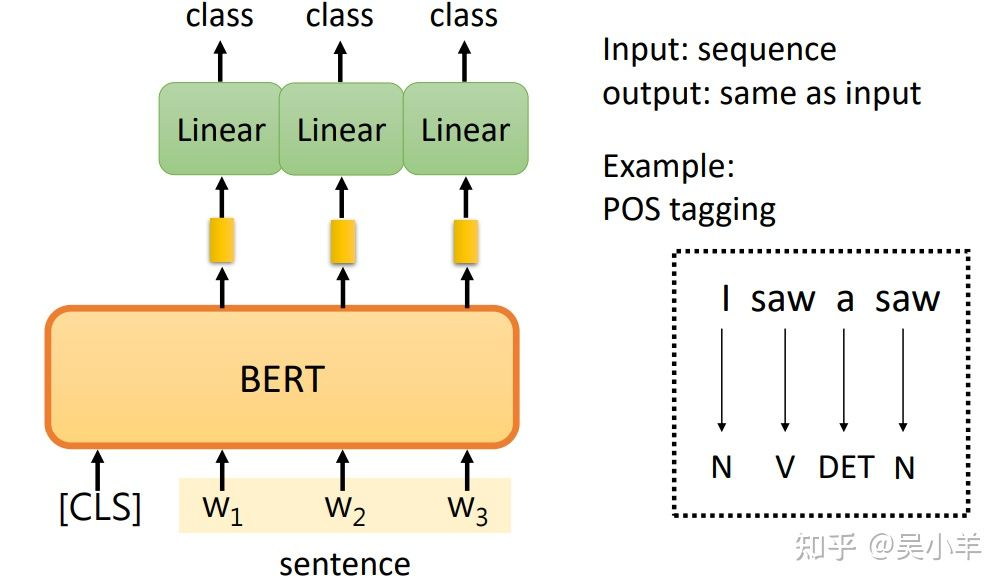
情感分析
输入句子,输出类别。CLS是一个特殊的token(单位),Linear的参数是随机初始化的,BERT是pre-train的。训练就是更新BERT和Linear这两个模型里的参数。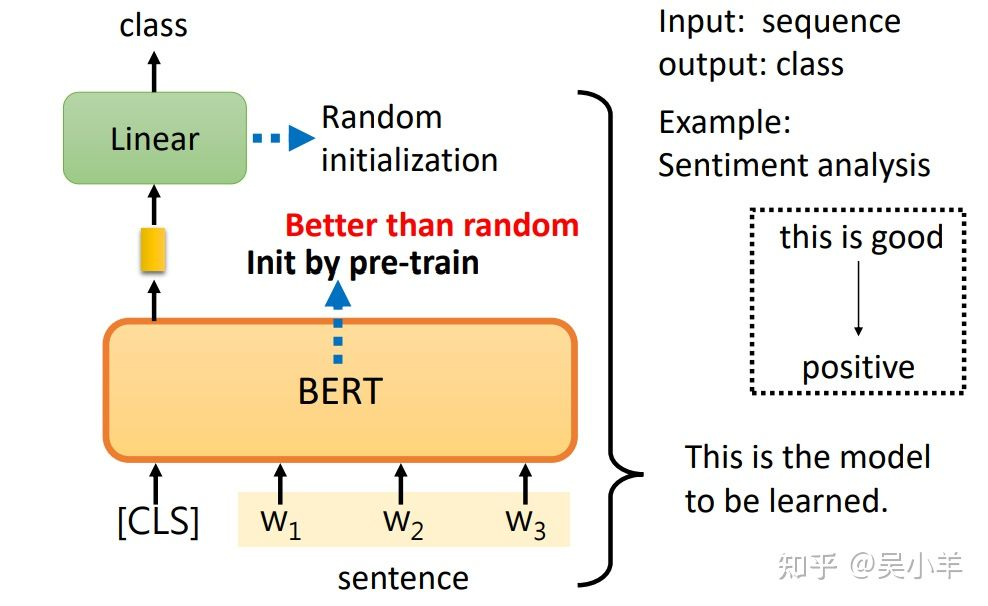
词性标注
句意立场分析
输入两个句子,输出类别。输出的类别是三个中的一个:contradiction(对立的)、entailment(同边)、neutral(中立的)。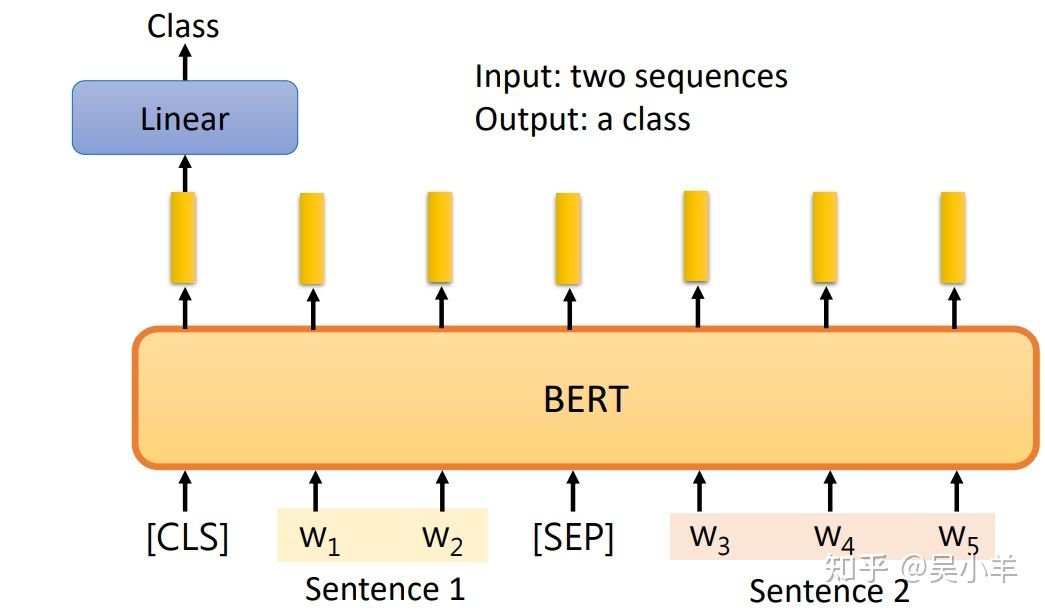
问答系统
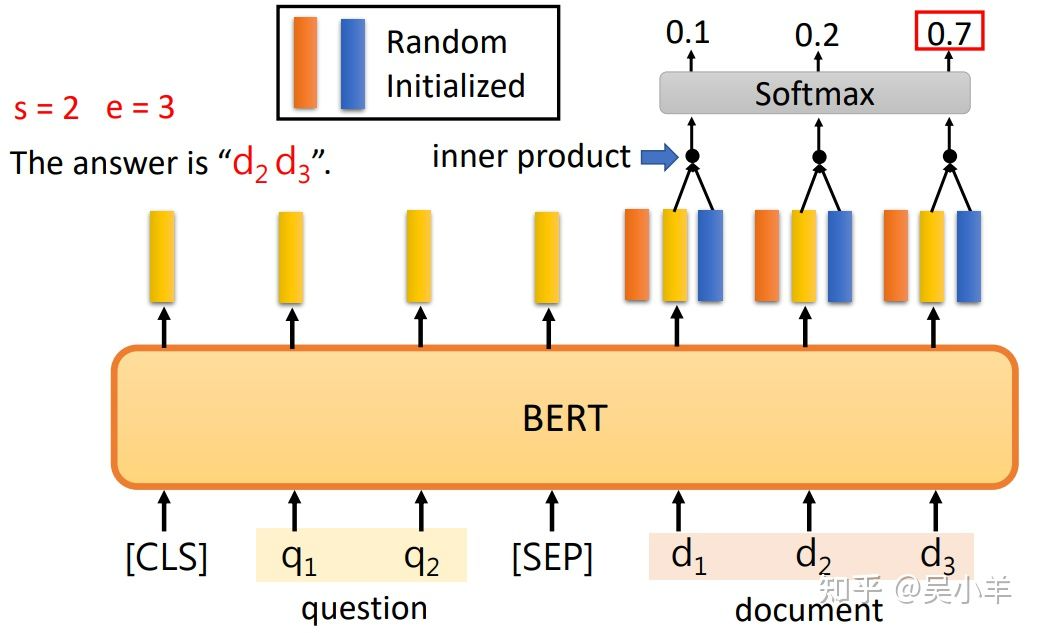
这个问答系统是针对回答能在文中找到的问答。输入问题和文章,输出两个正整数s和e,表示第s个字到第e个字之间的字就是答案。
橙色和蓝色向量的长度和BERT的输出向量的长度一致,因为要做内积。内积之后的向量经过softmax后得到分数,分数最高的位置就是起或止位置。 橙色向量代表答案的起始位置,蓝色向量代表答案的结束位置。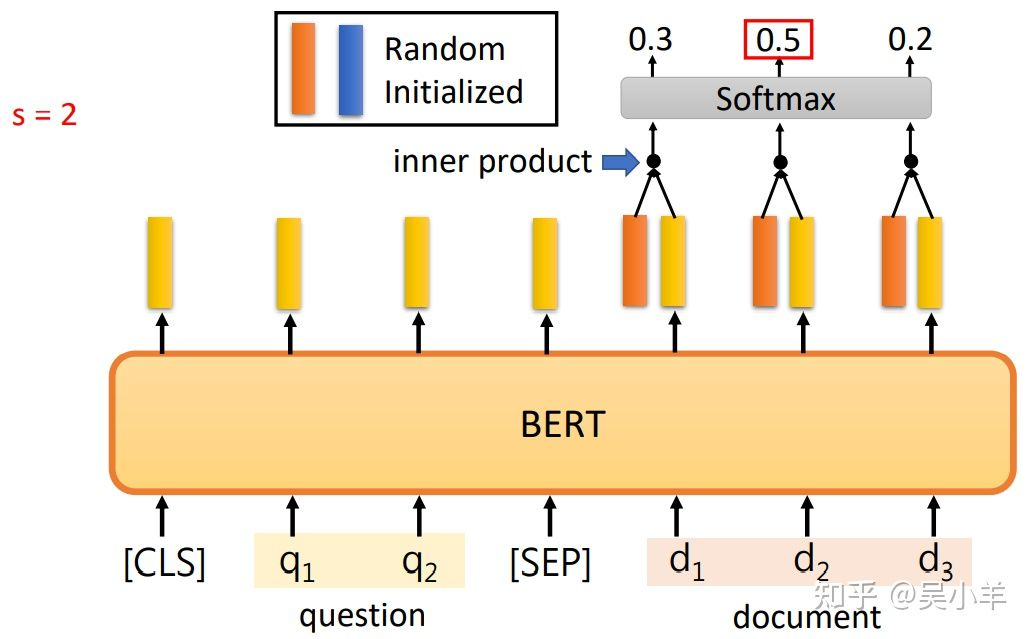
Pre-train a seq2seq model
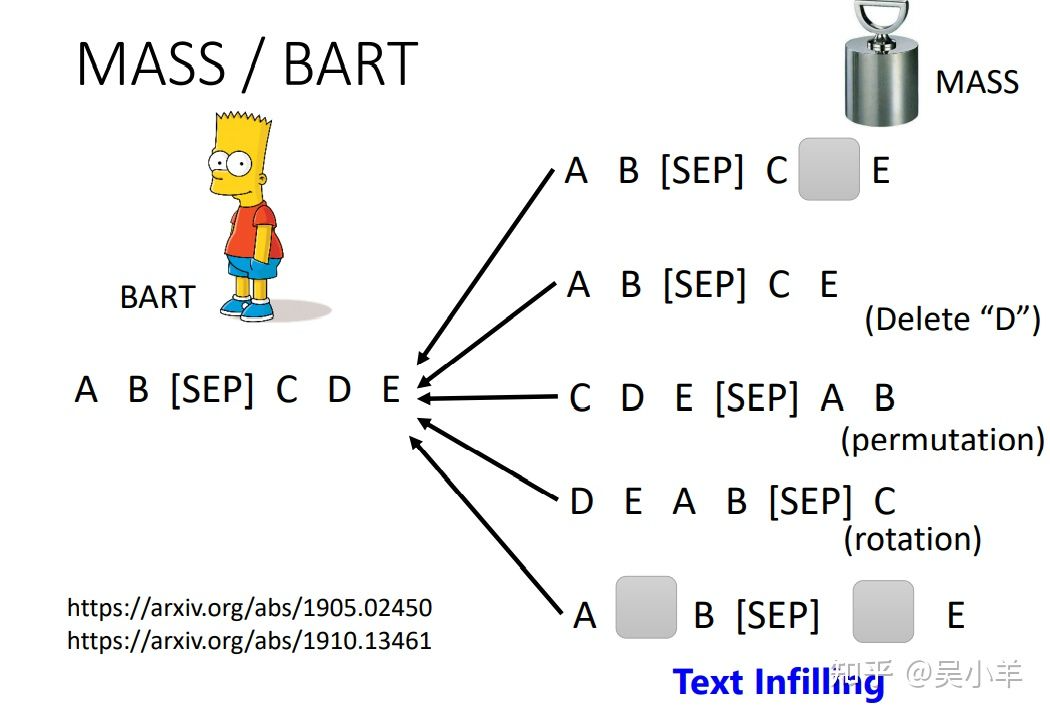
在一个transformer的模型中,将输入的序列损坏,然后该模型的输出是还原损坏的输入。如何损坏输入数据呢?可以采用mass或BART手段,mass是盖住某些数据(类似于masking),BART是综合了右边所有的方法(盖住数据、删除数据、打乱数据顺序、旋转数据等等),BART的效果要比mass好!!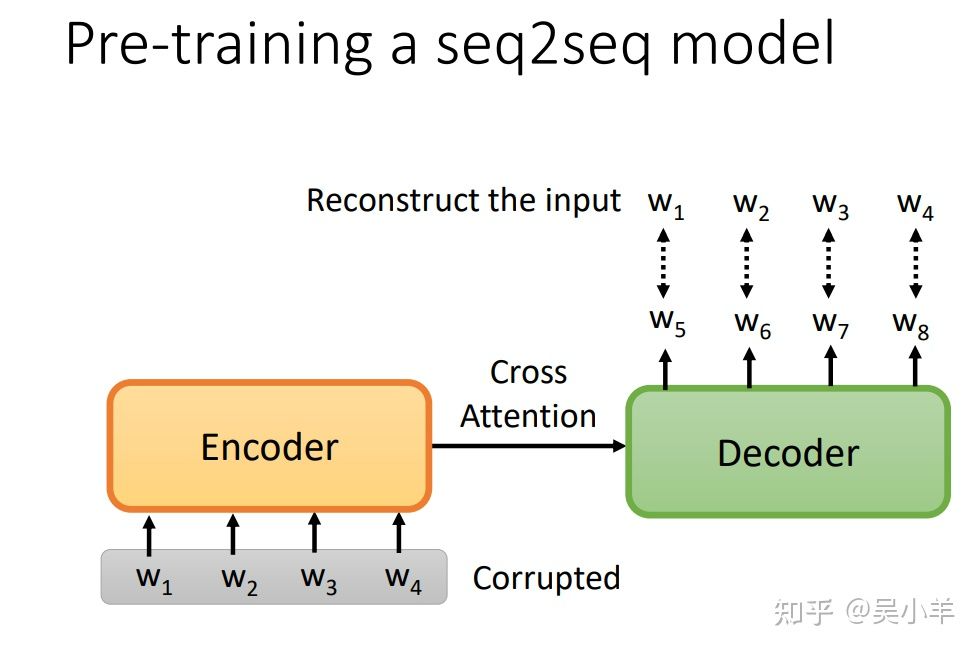
为什么BERT有效?
pre-train的BERT会做填空题,那为什么微调一下就能用作其他的应用呢?
意思越相近的字产生的向量越接近,如图右部分。同时,BERT会根据上下文,不同语义的同一个字产生不同的向量。(例如果字)
下图中,果对应的两个向量是不同的,为什么不同呢,因为训练填空题BERT时,就是从上下文抽取资讯来填空的,所以语义不同输出的向量当然不同了。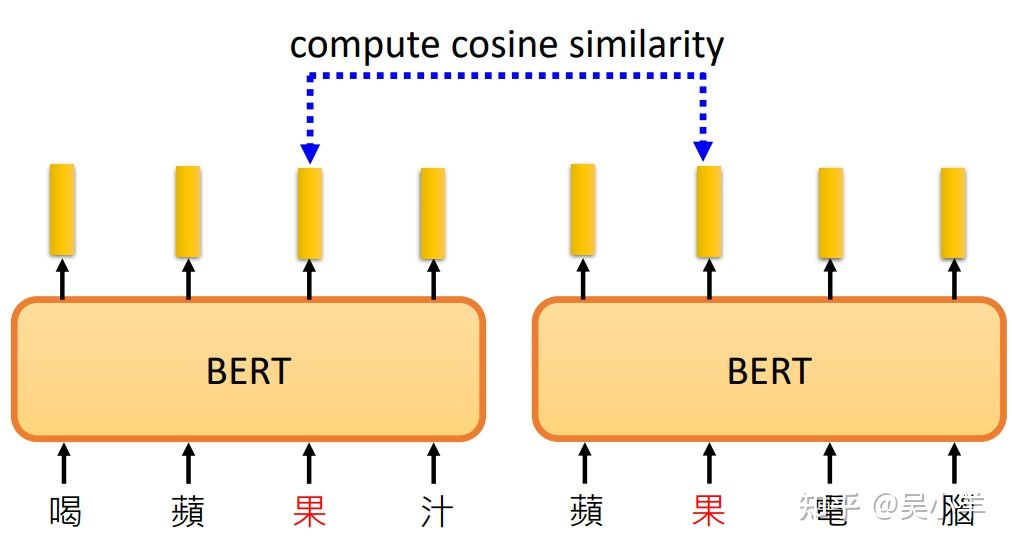
但是,应用BERT来研究蛋白质、DNA、音乐分类等问题中,在使用we,you等字代替氨基酸,最后训练出来的结果竟然会比较好,所以可能BERT的初始化参数就比较好,而与语义没有关系(一种推测,BERT内部结构还有很多问题尚待研究)。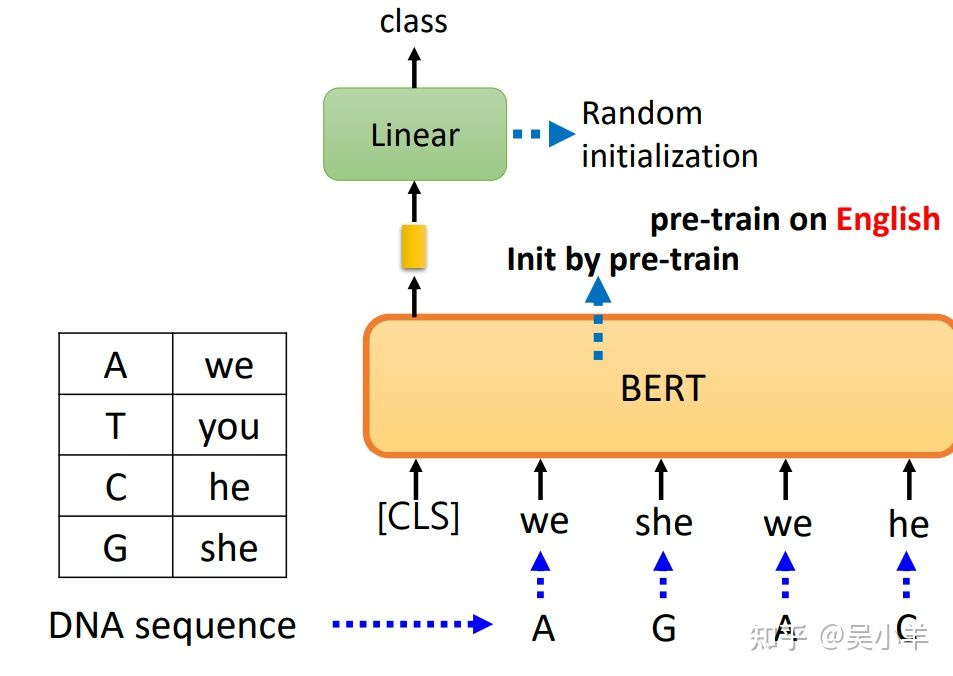
Multi-lingual BERT(多语言BERT)
用许多不同的语言预训练BERT,最后训练回答英语题目的模型竟然能在中文测试题上有较好的表现!
fine-tune是训练时输入的语言,test四号测试时输入问题和文章的语言。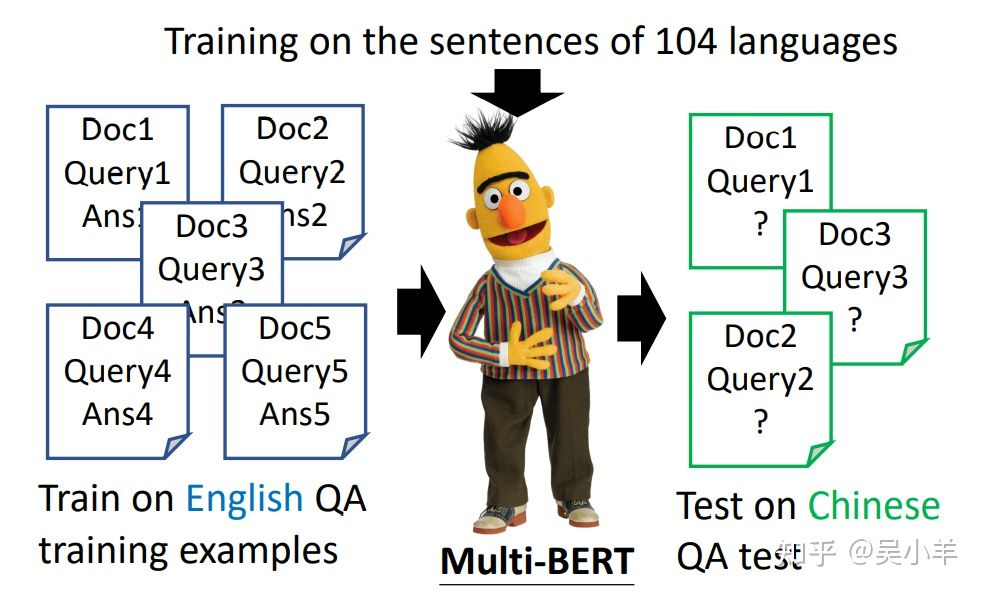
可能解释:不同语言之间存在对齐情况,即同义的不同语言的向量会比较接近,所以语言和语言之间输出的向量是存在一定关系的。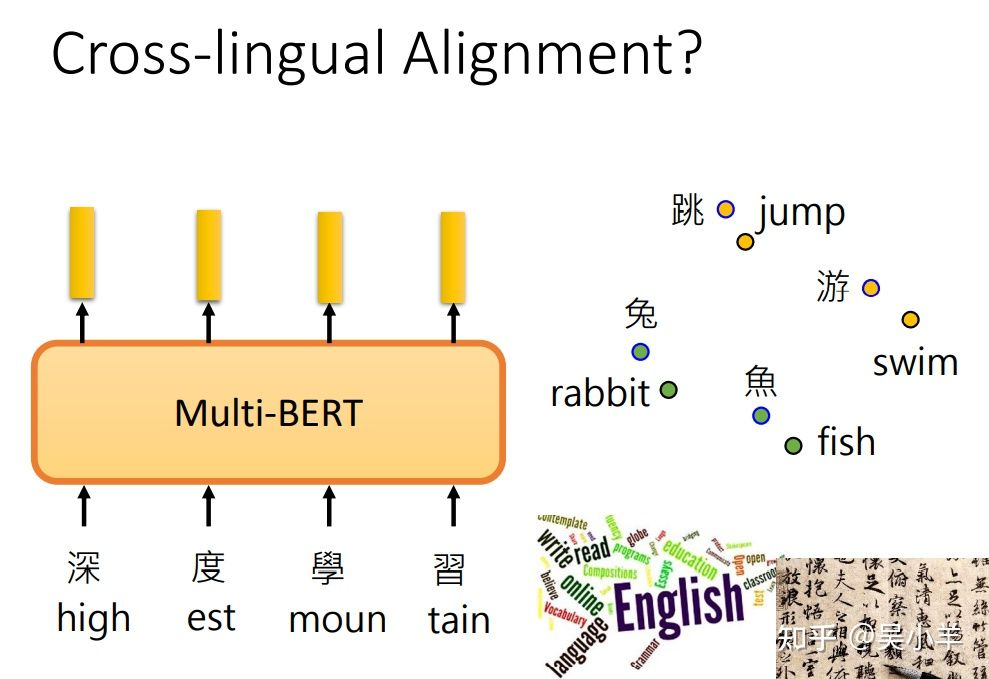
为了探寻不同语言之间的关系,做了下面这样一件事:
将所有中文的embbeding平均一下,英文的embbeding平均一下,发现两者之间存在着差距,这个差距用一个蓝色向量来表示。对一个multi-BERT输入英文问题和文章,他会输出一堆embedding,这堆embedding加上这个差距后,最终竟然能输出中文的答案。(所以同义的不同字代表的向量之间可能存在一个小小的偏差,改变偏差就能保证同义下改变字。)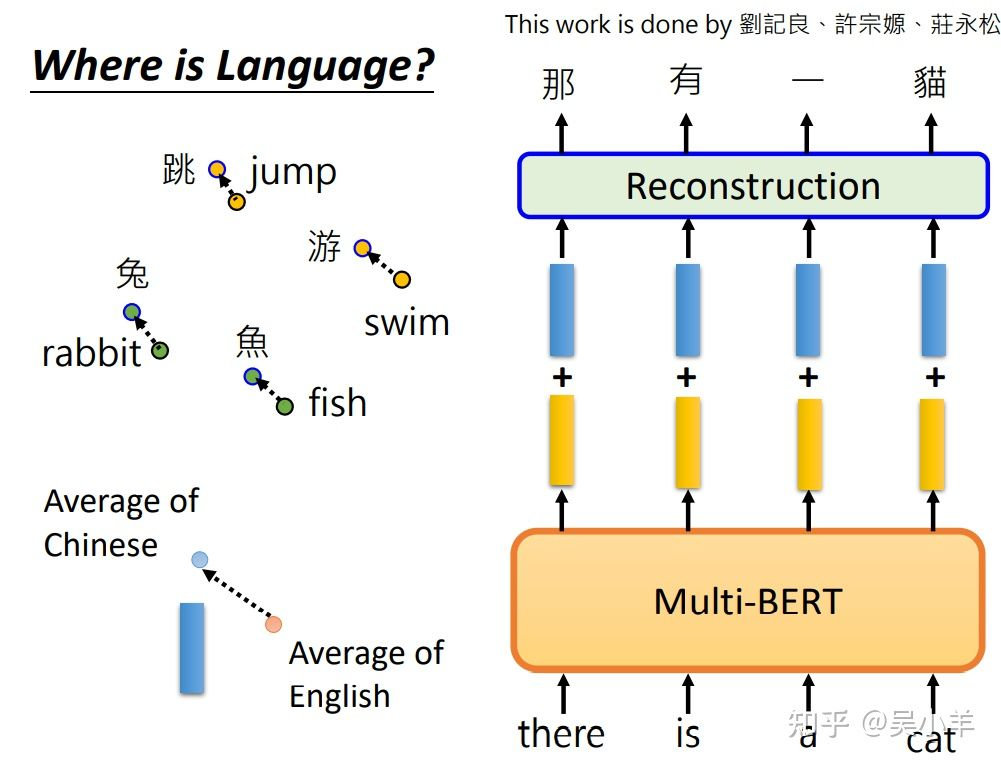
GPT框架概念
BERT模型能够做填空题,GPT模型则能预测下一个token(单位),不断预测下一个token甚至可以写一篇文章。
例如有笔训练资料是“台湾大学”,那么输入BOS后训练输出是台,再将台作为输入训练输出是湾,以此类推,在输出台之间是不会有“湾”、“大”等字的资讯。模型输出embedding h,h再经过linear transform(线性变换)和softmax后,计算输出分布与正确答案之间的cross entropy,希望它越小越好。(与一般的分类问题是一样的)

如何使用GPT
给模型问题描绘、解答例子,模型就能自己开始做题了。这个应用叫few-shot learning(少案例学习),但是它的准确率不是太高。和普通的学习不一样,它不需要用到gradient descent(梯度下降)。
题外话:self-supervised learning 有很多种模型,类型包括data centric(以数据为中心)、prediction(预测)、contrastive(对比),BERT和GPT都属于预测型。

若有收获,就点个赞吧
0 人点赞
