1、生成数据集
本例子是人工生成的数据集,里面有数据x_data。
import tensorflow as tfimport matplotlib.pyplot as plt# 定义正确的权重和偏置TRUE_W = 3.0 #这权值里我们是要通过模型预测出权重TRUE_b = 2.0 #这权值里我们是要通过模型预测出偏置# 制作训练数据,添加一些噪声进去NUM_EXAMPLES = 100inputs = tf.random.normal(shape=[NUM_EXAMPLES]) #制作的数据集noise = tf.random.normal(shape = [NUM_EXAMPLES])outputs = inputs * TRUE_W + TRUE_b + noise #这是我的标签
plt.scatter(inputs, outputs, label='Original data')plt.show()
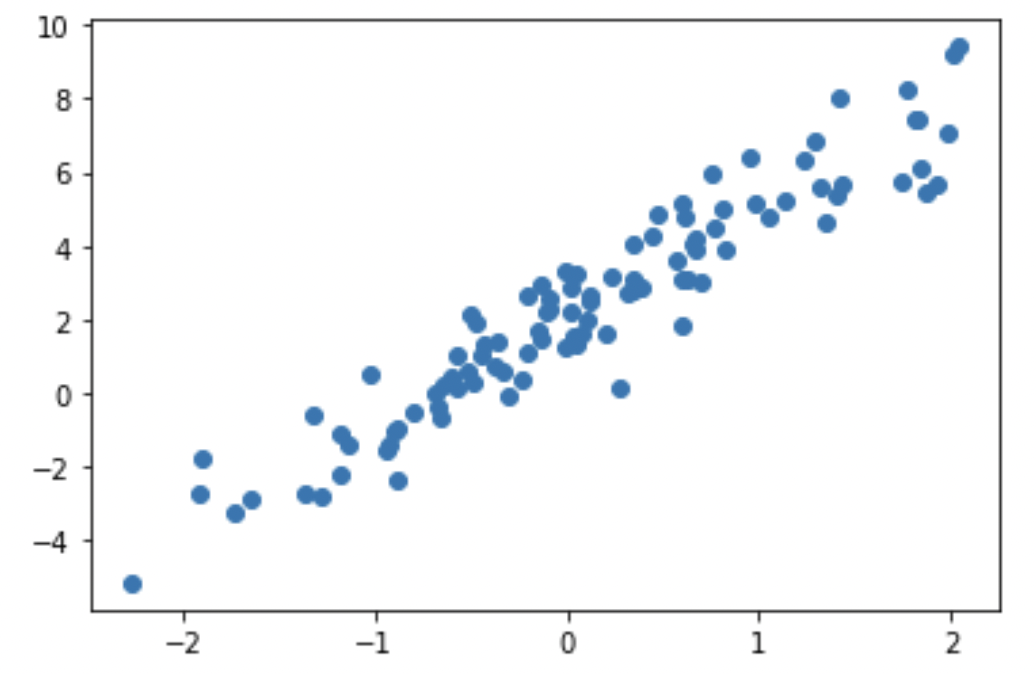
可以看到上图,数据集有inputs,outputs。现在我们要找到一种模型,这种模型可以总结出数据集的特点。
2、构建模型
下面就是定义的一个简单的模型,线性模型 self.W * inputs + self.b。
#定义模型和损失函数class Model(object):def __init__(self): #初始化参数self.W = tf.Variable(10.0)self.b = tf.Variable(-5.0)#基于函数定义的模型def __call__(self, inputs):return self.W * inputs + self.b#设计它的损失函数def compute_loss(y_true, y_pred):return tf.reduce_mean(tf.square(y_true-y_pred))model = Model()
def plot(epoch): #传入epoch参数,plt.scatter(inputs, outputs, c='b') # 画散点图,传入inputs,outputs数据集,c是颜色为blueplt.scatter(inputs, model(inputs), c='r') #传入inputs, 预测的model(inputs),c是红色plt.title("epoch %2d, loss = %s" %(epoch, str(compute_loss(outputs, model(inputs)).numpy())))plt.legend() #plt.legend()函数主要的作用就是给图加上图例,plt.draw() #将重新绘制该数字.这允许您以交互模式工作,如果您更改了数据或格式,则允许图表本身更改.plt.ion() # # 打开交互模式plt.pause(1)#plt.pause()会把它之前的所有绘图都绘制在对应坐标系中,而不仅仅是在当前坐标系中绘图;#plt.pause(time)函数也能实现窗口绘图(不需要plt.show),但窗口只停留time时间便会自动关闭,然后再继续执行后面代码;plt.close()
3、训练模型
最主要的是训练模型,训练的主要内容是:先前向传播,计算损失,在反向传播,更新参数。
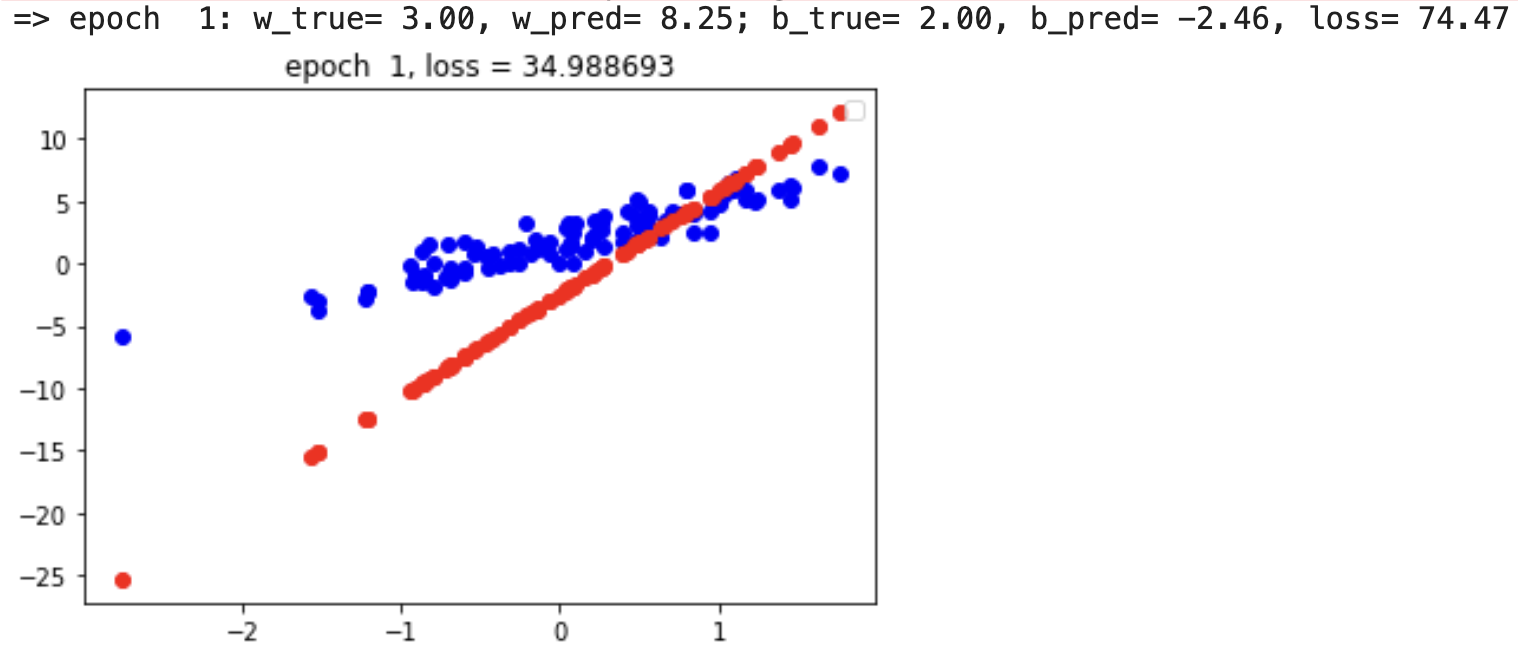
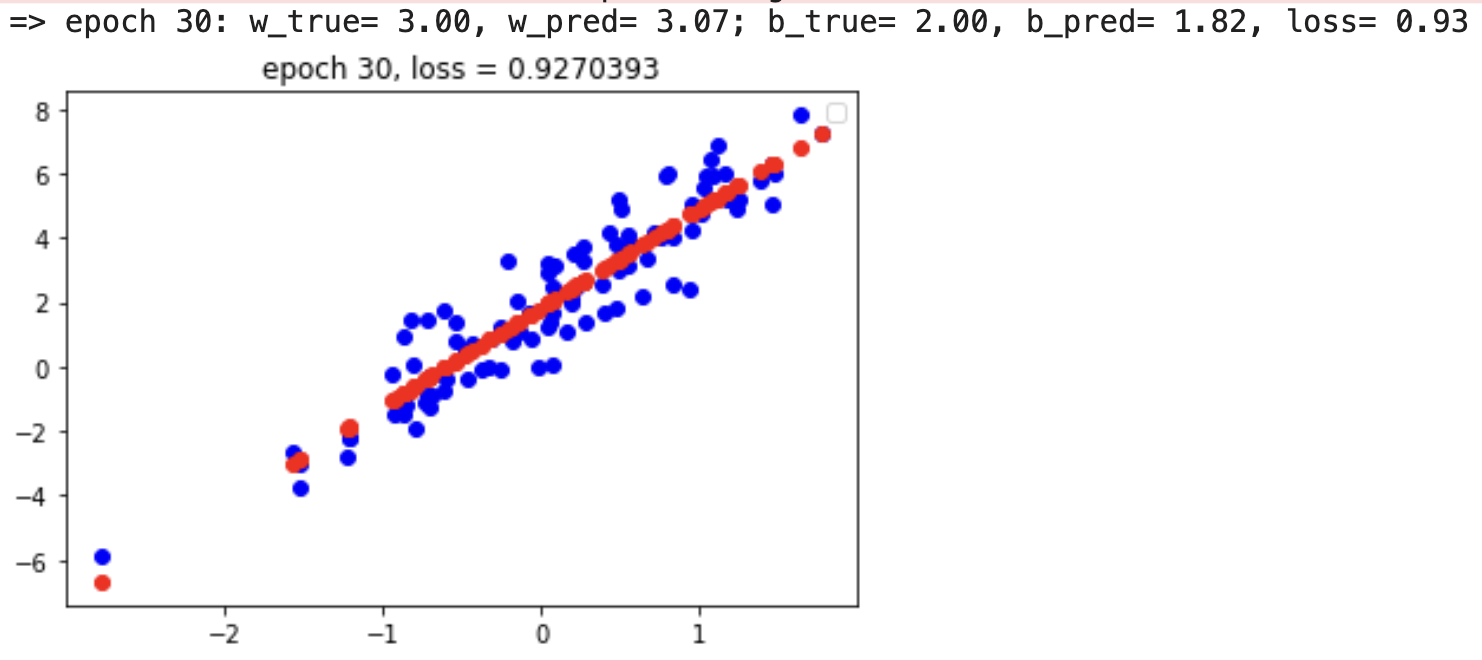
learning_rate=0.2 #设置损失函数的学习率epoch=30 #设置epoch的数量 ,1个epoch是一整个数据集,bachsize是一次性送入网络中的样本数量,用总的数据集/bachsize=迭代数for i in range(epoch): #进行for循环with tf.GradientTape() as tape:loss = compute_loss(outputs, model(inputs)) # 计算损失dW, db = tape.gradient(loss, [model.W, model.b]) # 计算梯度model.W.assign_sub(learning_rate * dW) # 更新权重model.b.assign_sub(learning_rate * db) # 更新权重print("=> epoch %2d: w_true= %.2f, w_pred= %.2f; b_true= %.2f, b_pred= %.2f, loss= %.2f" %(i+1, TRUE_W, model.W.numpy(), TRUE_b, model.b.numpy(), loss.numpy()))plot(i+1)i += 1
4、测试数据
模型里面的参数已经训练好了,可以拿着参数,验证一下测试集是否准确。
5、评估模型
拿着测试出来的数据,选择好评估函数看正确率怎么样。

若有收获,就点个赞吧
0 人点赞
