单个神经元
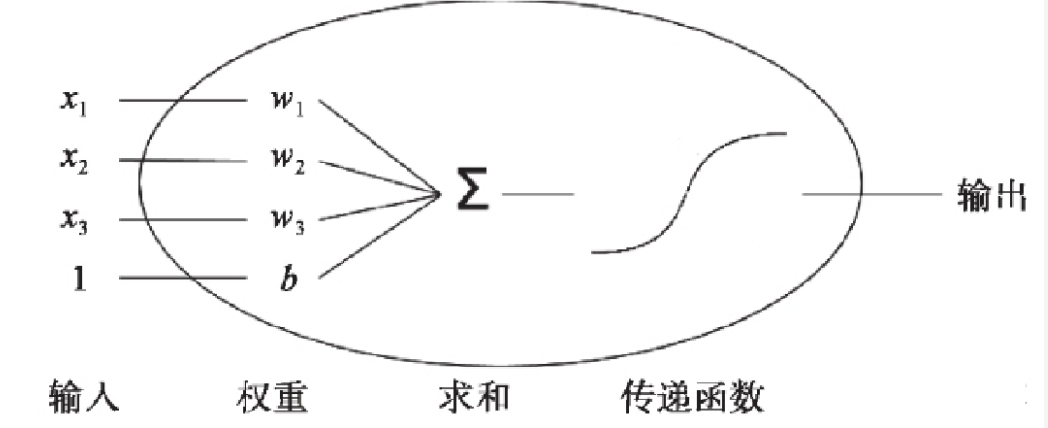
- 缺陷:无法拟合“异或”运算。
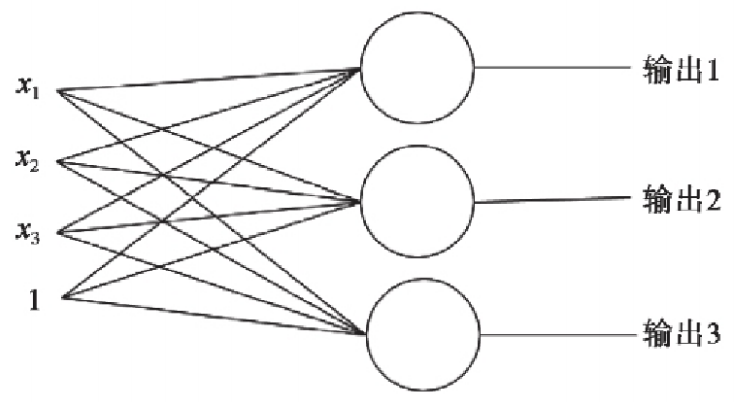
多个神经元(多分类)
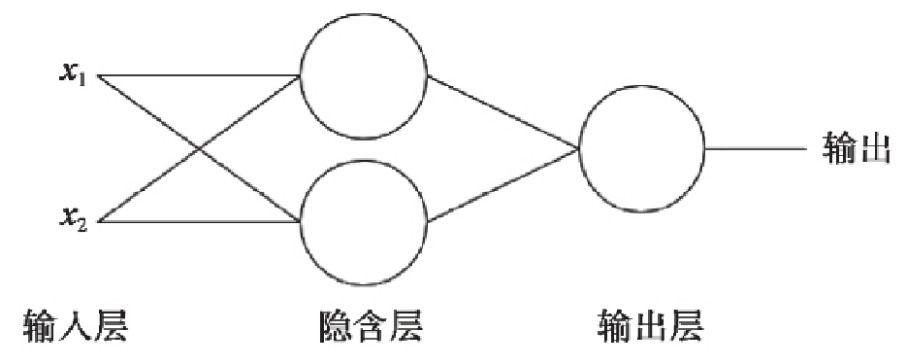
多层感知器
梯度下降算法
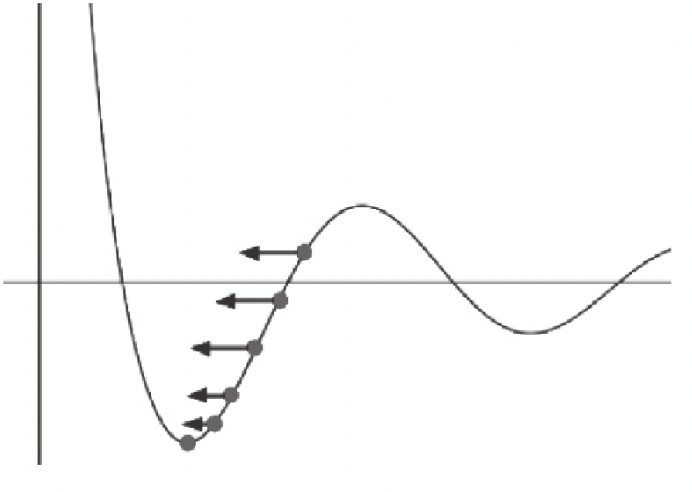
学习速率
对梯度进行缩放的参数被称为学习速率。需要为它指定正确的值。如果学习速率太小,则找到损失函 数极小值点时可能需要许多轮迭代;如果太大,则算法可能会“跳过”极小值点并且因周期性的“跳跃”而永远无法找到极小值点。
合适的学习速率,损失函数随时间下降,直到一个底部不合适的学习速率,损失函数可能会发生震荡。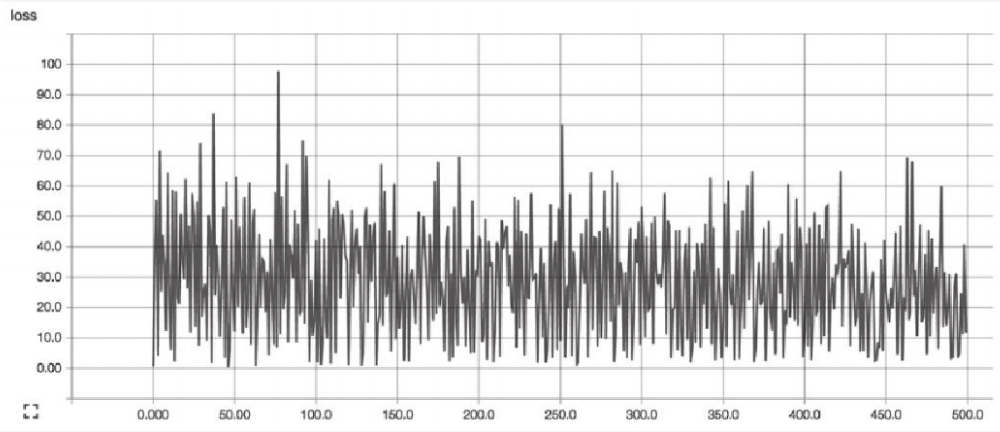
激活函数
relu(常用)
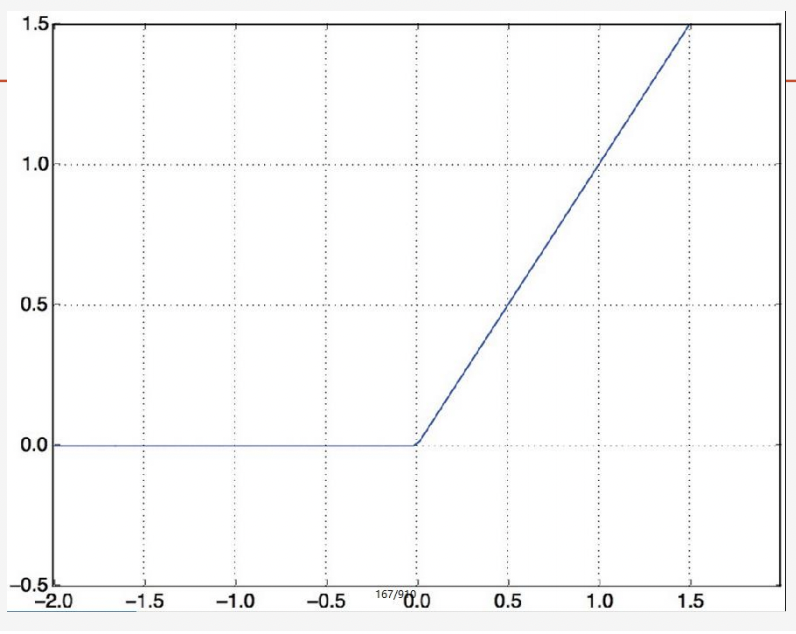
tanh(已淘汰)
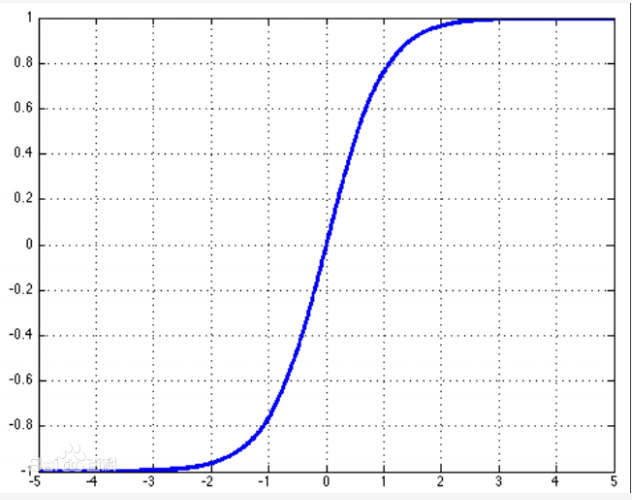
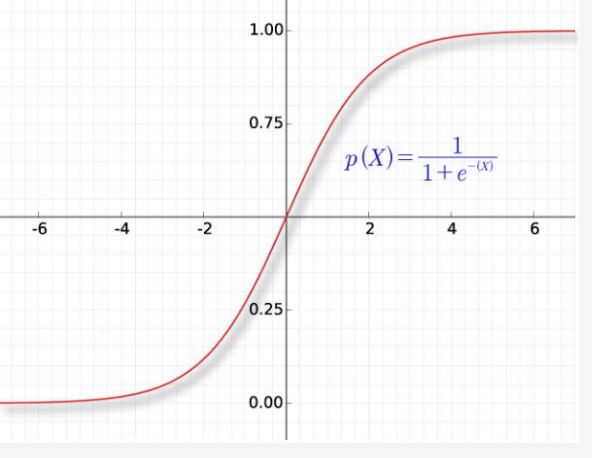
sigmoid(用于二分类)
优化函数
优化器 (optimizer) 是编译 Keras 模型的所需的两个参数之 一。
SGD:随机梯度下降优化器
随机梯度下降优化器SGD和min-batch是同一个意思,抽取 m个小批量(独立同分布)样本,通过计算他们平梯度均值。
RMSprop(循环神经网络RNN推荐使用)
RMSProp增加了一个衰减系数来控制历史信息的获取多少, RMSProp会对学习率进行衰减。
Adam(推荐使用)
Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
建模
model = keras.Sequential()from keras import layers# 创建多个层model.add(layers.Dense(32, input_dim=11, activation='relu'))model.add(layers.Dense(32, activation='relu'))model.add(layers.Dense(1, activation='sigmoid'))model.summary()

编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc'])
训练模型
model.fit(x, y, epochs=300)
测试模型
**

若有收获,就点个赞吧
0 人点赞
