slot filling任务
让机器读一个句子:I would like to arrive Hainan on March 2nd.
机器要找出destination是Hainan,time of arrival是November 2nd。这里的destination和time of arrival就是slots。
RNN基本结构
如果用Feedforward network解决slot filling,会是什么样呢?首先要把Hainan表示成一个vector,可以用one-of-N encoding,也可用word hashing来表示,假设现在用one-of-N encoding,那么这个network的输出就是Hainan属于每一个slot的概率。
但是这样会存在一个问题,testing时遇到另一个句子:I would like to leave Hainan on March 2nd. Hainan在这个句子中是place of departure,可在RNN中输入Hainan它的输出依旧是destination的几率最高。这说明神经网络需要有memory,这就引出了RNN。
在RNN中,hidden layer的output会存在memory中,下一次在input vector进去之后会把之前存在memory的信息拿出来看,memory可以看作是另一个输入。
下图中红线代表存储信息,蓝色代表读取memory。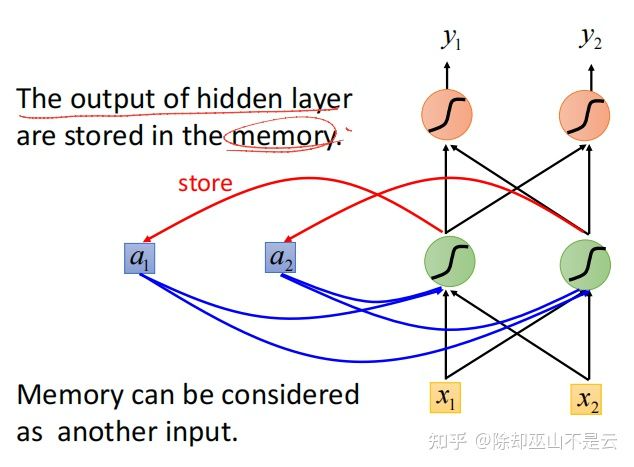
通过重复使用同一个网络,RNN依次读取一个句子,每都一个单词就产生一次输出。如果改变输入单词的顺序,输出也会随之改变。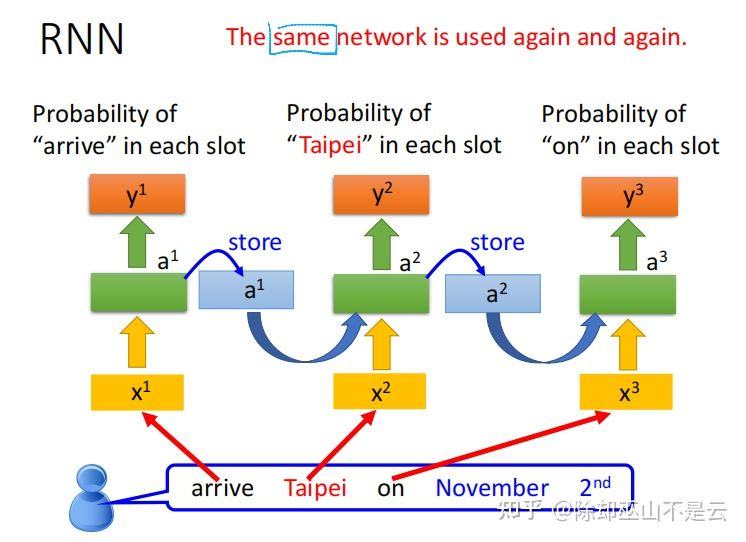
如果输入的单词不一样,存在memory的信息也就不一样,那么下一次输出也不一样,可以参考下图的例子。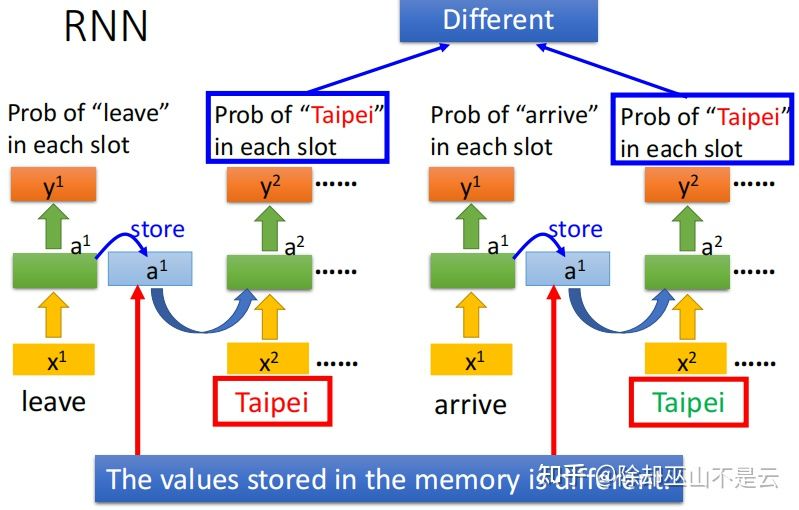
当然RNN可以是deep的,可以有很多个hidden layer,上述例子中假设只有一层hidden layer。
不同种类的RNN
RNN网络可以设计成许多种形态。
- Elman Network
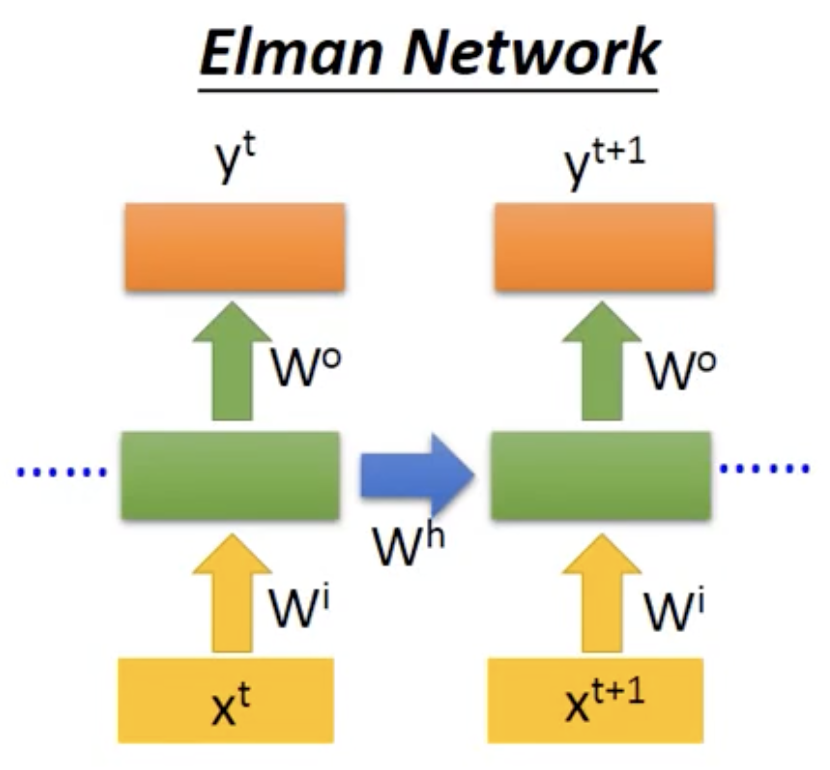
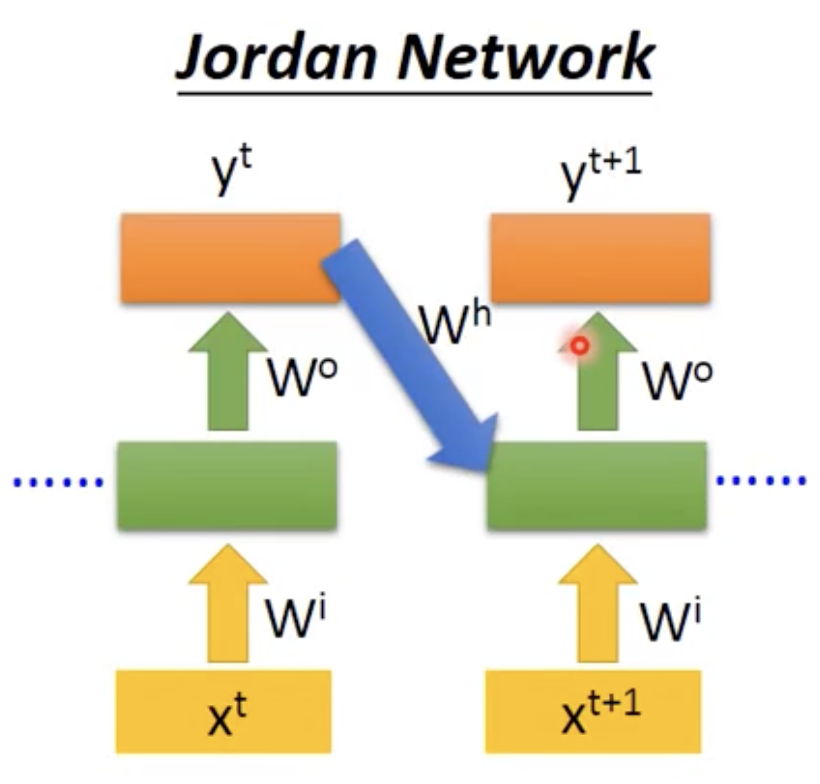
- Jordan Network
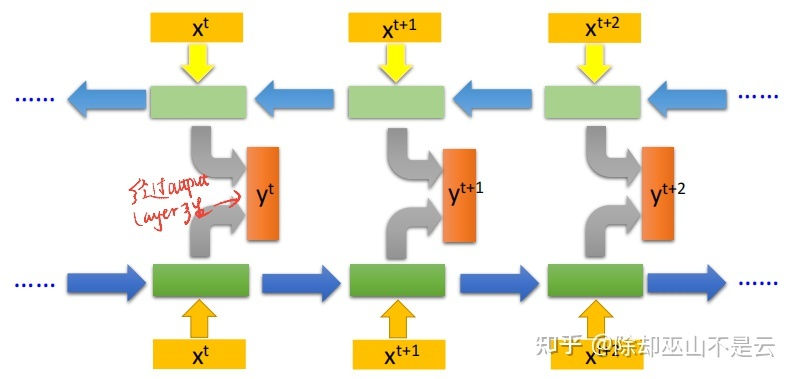
- Bidirectional RNN
LSTM (Long short-term memory)
目前为止讲的RNN是最简单的版本,实际上的memory是长成LSTM这样的,一般来说LSTM和RNN这两个名词可以互相代替。
LSTM可以看成一个有4个inputs,1个output的特殊neuron。4个inputs分别是:
- 某个neuron的input;
- input gate的输入;
- output gate的输入;
- forget gate的输入。
三个gate打开和关闭的时机,network自己会学。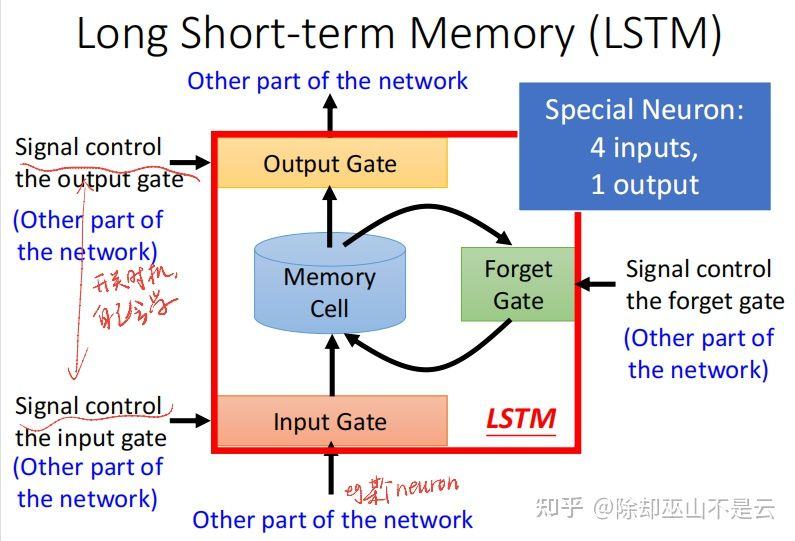

手工计算LSTM举例:

把hidden layer普通的neuron换成LSTM,就是升级版的RNN了。更具体的运作流程如下:
- input vector
 经过linear transform变成vector
经过linear transform变成vector  ,作为input;
,作为input; - input vector
 经过linear transform变成vector
经过linear transform变成vector  ,作为input gate的输入;
,作为input gate的输入; - input vector
 经过linear transform变成vector
经过linear transform变成vector  ,作为forget gate的输入;
,作为forget gate的输入; - input vector
 经过linear transform变成vector
经过linear transform变成vector  ,作为output gate的输入;
,作为output gate的输入;
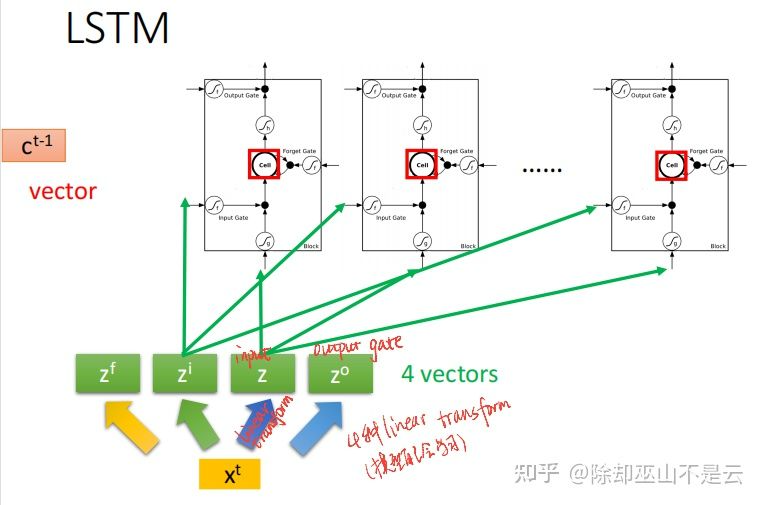
四种linear transform由network自己学习得到。相较于一般的neuron,LSTM的parameter数量是其4倍。下图最左边的vector  是处理上一个word
是处理上一个word  存在memory cell中的值。Memory cell的初始值是
存在memory cell中的值。Memory cell的初始值是  。
。
输入以及三个gate之间的运算如下,一般三个gate的act_fun会选择sigmoid function:



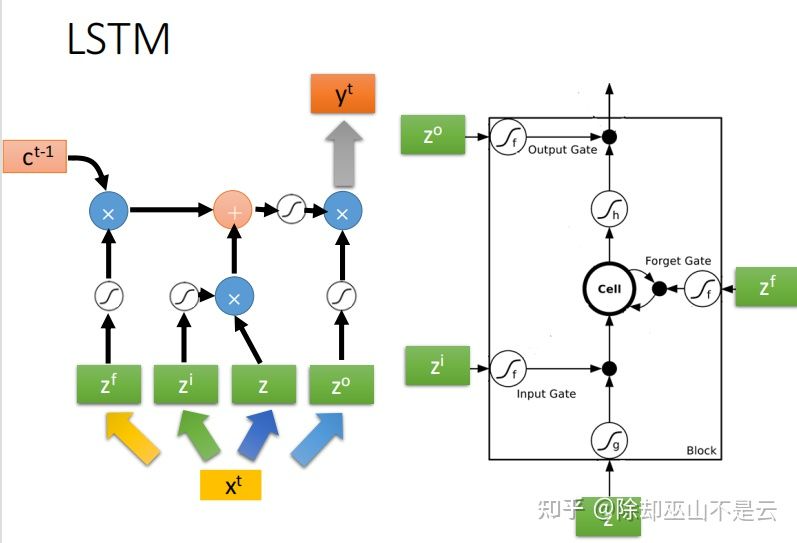
真正的LSTM还是更复杂的!LSTM会把上一个输出  作为下一个输入的一部分,也会把memory cell的值
作为下一个输入的一部分,也会把memory cell的值  作为下一个输入的一部分。
作为下一个输入的一部分。  也被叫做peephole。
也被叫做peephole。
RNN 训练补充
RNN在训练时也是用梯度来更新模型权重的。在training时常会遇到RNN的total loss起伏很大的情况,[Razvan Pascanu,On the difficulty of training Recurrent Neural Networks,ICML’13] 这篇文章提出RNN的error的高低起伏很大,有的地方很陡峭,有的地方很平坦。以下的technique可以帮助解决RNN 的gradient vanishing问题。
- 使用LSTM,为什么呢?这是因为RNN和LSTM对待记忆单元的做法是不同的,RNN中每一个时间点的记忆单元中的内容(状态)都会更新,而LSTM则是将记忆单元中的值与输入值相加(按某种权值)再更新状态,记忆单元中的值会始终对输出产生影响(除非Forget Gate完全的关闭)。
- 使用GRU(Gated Recurrent Unit ),是LSTM更简单的版本,只需要三个inputs;
- Clockwise RNN[Jan Koutnik,A Clockwork RNN,JMLR’14]
- Structurally Constrained Recurrent Network(SCRN)[Tomas Mikolov,Learning Longer Memory in Recurrent Neural Networks,ICLR’15]
- Vanilla RNN Initialized with Identity matrix + ReLU activation function [Quoc V.Le,A Simple Way to Initialize Recurrent Networks of Rectified Linear Units,arXiv’15]用了特别的初始化技巧,硬训RNN,

若有收获,就点个赞吧
0 人点赞
