为后面的网络提供不同的数据形式。
https://pytorch.org/docs/stable/data.html?highlight=dataloader#torch.utils.data.DataLoader
- dataset (Dataset) – dataset from which to load the data.
- batch_size (int, optional) – how many samples per batch to load (default:
1). - shuffle (bool, optional) – set to
Trueto have the data reshuffled at every epoch (default:False). - num_workers (int, optional) – how many subprocesses to use for data loading.
0means that the data will be loaded in the main process. (default:0) - drop_last (bool, optional) – set to
Trueto drop the last incomplete batch, if the dataset size is not divisible by the batch size. IfFalseand the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default:False) ```python import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor() ])
数据集
test_dataset = torchvision.datasets.CIFAR10(root=”./dataset”, train=False, transform=dataset_transform, download=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
测试数据集中第一张图片及target
img, target = test_dataset[0] print(img.shape) print(target)
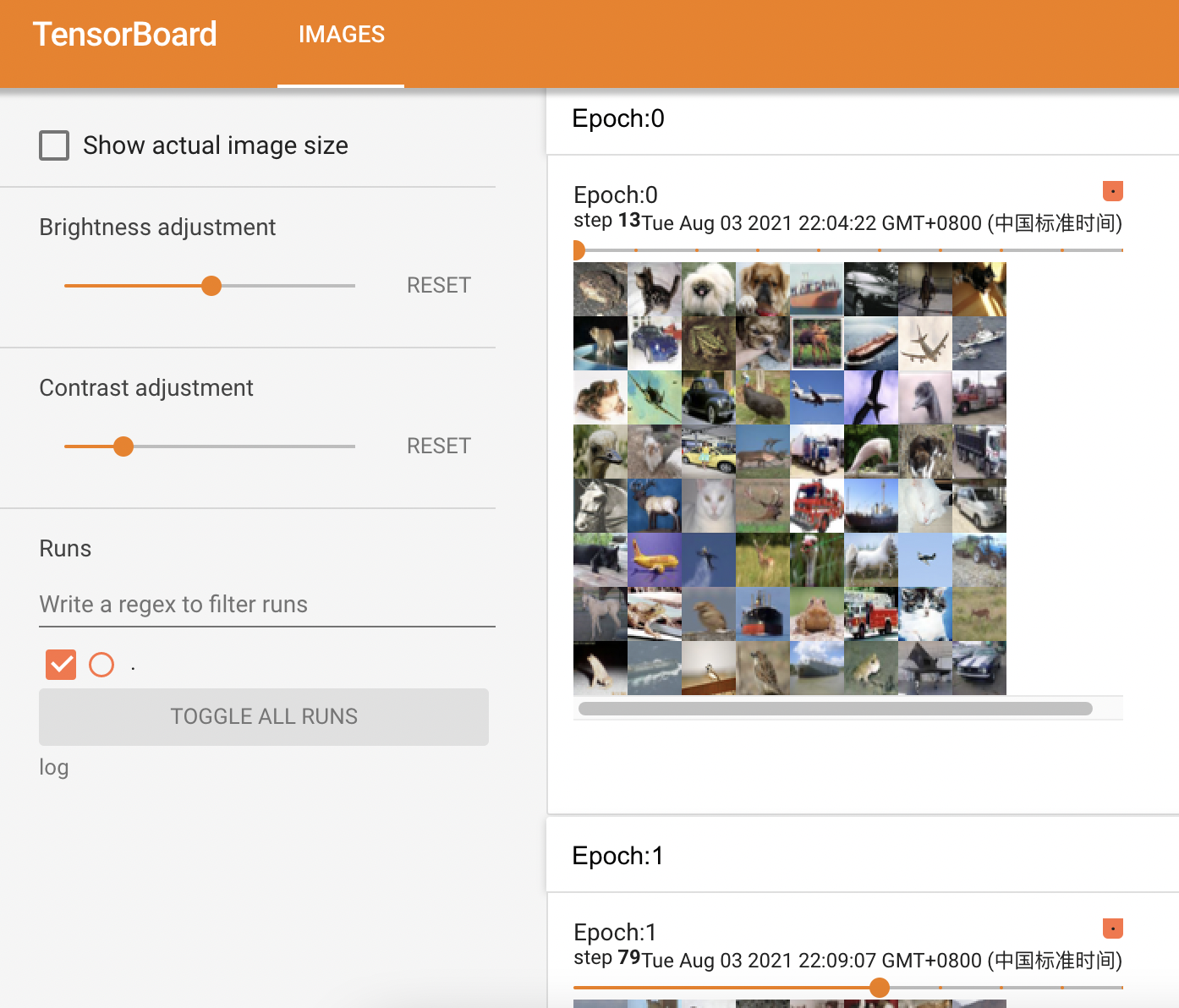
writer = SummaryWriter(“log”) for epoch in range(2): step = 0 for data in test_loader: imgs, targets = data
# print(imgs.shape)# print(targets)writer.add_images("Epoch:{}".format(epoch), imgs, step)step = step + 1
writer.close()

若有收获,就点个赞吧
0 人点赞
