当你的loss不再下降的时候,gradient不一定真的很小。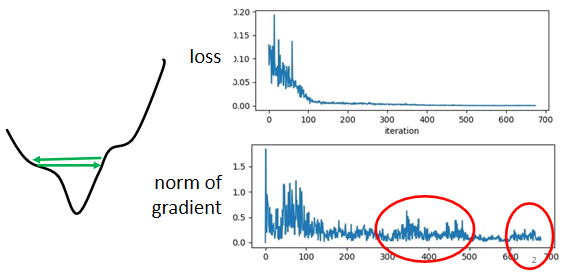
这个是我们的error surface,然后你现在的gradient,在error surface山谷的两个谷壁间,不断的来回的震荡。它的gradient仍然很大,只是loss不见得再减小了。
其实我们可以看到一个大原则,如果在某一个方向上,我们的gradient的值很小,非常的平坦,那我们会希望learning rate调大一点;如果在某一个方向上非常的陡峭,坡度很大,那我们其实期待learning rate可以设得小一点。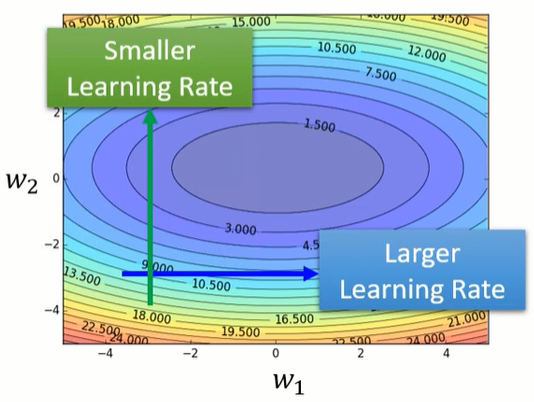
RMS Prop
全称是root mean square prop算法,可以使learning rate动态调整的。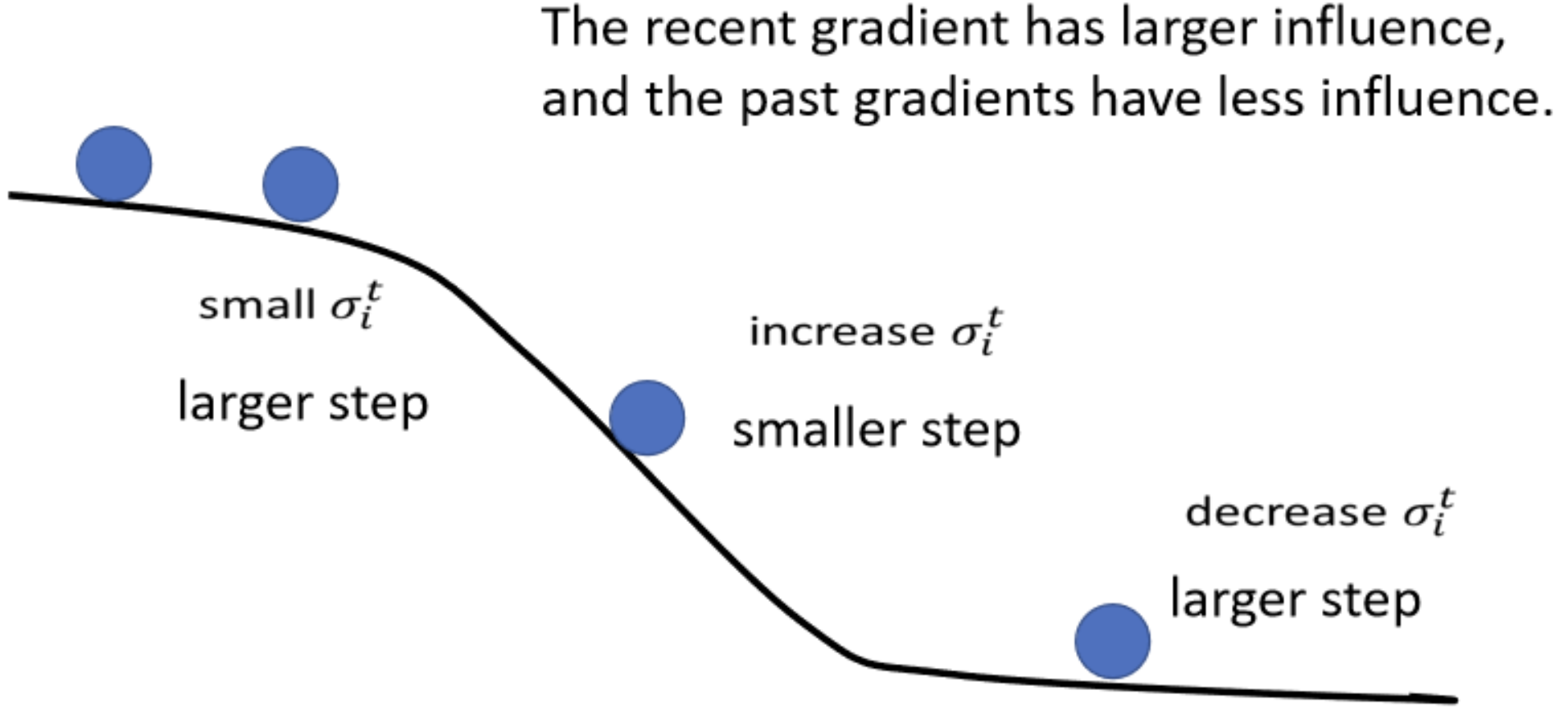
Adam
那今天你最常用的optimization的策略(有人又叫做optimizer),就是Adam。
Adam就是RMS Prop加上Momentum。

若有收获,就点个赞吧
0 人点赞
