一、HTTP的实体数据
1.数据类型与编码
Encoding type 常用三种格式:
- gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式;
- deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip;
- br:一种专门为 HTTP 优化的新压缩算法(Brotli)。
2.数据类型使用的头字段
HTTP 协议为此定义了两个 Accept 请求头字段和两个 Content 实体头字段,用于客户端和服务器进行“内容协商”。
Accept字段标记的是客户端可理解的 MIME type,让服务器有更多的选择余地。
服务器会在响应报文里用头字段Content-Type告诉实体数据的真实类型。
Accept-Encoding字段标记的是客户端支持的压缩格式,服务器可以选择其中一种来压缩数据,实际使用的压缩格式放在响应头字段Content-Encoding里。
3.语言类型使用的头字段
Accept-Language字段标记了客户端可理解的自然语言,也允许用“,”做分隔符列出多个类型,例如:
相应的,服务器应该在响应报文里用头字段Content-Language告诉客户端实体数据使用的实际语言类型:
字符集在 HTTP 里使用的请求头字段是Accept-Charset,但响应头里却没有对应的 Content-Charset,而是在Content-Type字段的数据类型后面用“charset=xxx”来表示,这点需要特别注意。

4.内容协商的质量值
在 HTTP 协议里用 Accept、Accept-Encoding、Accept-Language 等请求头字段进行内容协商的时候,还可以用一种特殊的“q”参数表示权重来设定优先级,这里的“q”是“quality factor”的意思。
5.内容协商的结果
服务器会在响应头里多加一个Vary字段,记录服务器在内容协商时参考的请求头字段,给出一点信息。
小结
- 数据类型表示实体数据的内容是什么,使用的是 MIME type,相关的头字段是 Accept 和 Content-Type;
- 数据编码表示实体数据的压缩方式,相关的头字段是 Accept-Encoding 和 Content-Encoding;
- 语言类型表示实体数据的自然语言,相关的头字段是 Accept-Language 和 Content-Language;
- 字符集表示实体数据的编码方式,相关的头字段是 Accept-Charset 和 Content-Type;
- 客户端需要在请求头里使用 Accept 等头字段与服务器进行“内容协商”,要求服务器返回最合适的数据;
- Accept 等头字段可以用“,”顺序列出多个可能的选项,还可以用“;q=”参数来精确指定权重。
二、HTTP传输大文件的方法
1.数据压缩
如果压缩率能有 50%,也就是说 100K 的数据能够压缩成 50K 的大小,那么就相当于在带宽不变的情况下网速提升了一倍,加速的效果是非常明显的。
不过这个解决方法也有个缺点,gzip 等压缩算法通常只对文本文件有较好的压缩率,而图片、音频视频等多媒体数据本身就已经是高度压缩的,再用 gzip 处理也不会变小(甚至还有可能会增大一点),所以它就失效了。
2.分块传输
在响应报文里用头字段“Transfer-Encoding: chunked”来表示。
“Transfer-Encoding: chunked”和“Content-Length”这两个字段是互斥的,也就是说响应报文里这两个字段不能同时出现,一个响应报文的传输要么是长度已知,要么是长度未知(chunked),这一点你一定要记住。
3.范围请求
允许客户端在请求头里使用专用字段来表示只获取文件的一部分,相当于是客户端的“化整为零”。
服务器必须在响应头里使用字段“Accept-Ranges: bytes”明确告知客户端:“我是支持范围请求的”。
4.多段数据
“multipart/byteranges”,表示报文的 body 是由多段字节序列组成的,并且还要用一个参数“boundary=xxx”给出段之间的分隔标记。
小结
- 压缩 HTML 等文本文件是传输大文件最基本的方法;
- 分块传输可以流式收发数据,节约内存和带宽,使用响应头字段“Transfer-Encoding: chunked”来表示,分块的格式是 16 进制长度头 + 数据块;
- 范围请求可以只获取部分数据,即“分块请求”,实现视频拖拽或者断点续传,使用请求头字段“Range”和响应头字段“Content-Range”,响应状态码必须是 206;
- 也可以一次请求多个范围,这时候响应报文的数据类型是“multipart/byteranges”,body 里的多个部分会用 boundary 字符串分隔。
三、HTTP的连接管理
1.短连接
因为客户端与服务器的整个连接过程很短暂,不会与服务器保持长时间的连接状态,所以就被称为“短连接”。
短连接的缺点相当严重,因为在 TCP 协议里,建立连接和关闭连接都是非常“昂贵”的操作。TCP 建立连接要有“三次握手”,发送 3 个数据包,需要 1 个 RTT;关闭连接是“四次挥手”,4 个数据包需要 2 个 RTT。
2.长连接
针对短连接暴露出的缺点,HTTP 协议就提出了“长连接”的通信方式,也叫“持久连接”(persistent connections)、“连接保活”(keep alive)、“连接复用”(connection reuse)。
3.连接相关的头字段
请求头里明确地要求使用长连接机制,使用的字段是Connection,值是“keep-alive”。
如果服务器支持长连接,它总会在响应报文里放一个“Connection: keep-alive”字段。
因为 TCP 连接长时间不关闭,服务器必须在内存里保存它的状态,这就占用了服务器的资源。如果有大量的空闲长连接只连不发,就会很快耗尽服务器的资源,导致服务器无法为真正有需要的用户提供服务。所以,长连接也需要在恰当的时间关闭,不能永远保持与服务器的连接,这在客户端或者服务器都可以做到。
在客户端,可以在请求头里加上“Connection: close”字段,告诉服务器:“这次通信后就关闭连接”。服务器看到这个字段,就知道客户端要主动关闭连接,于是在响应报文里也加上这个字段,发送之后就调用 Socket API 关闭 TCP 连接。
服务器端通常不会主动关闭连接,但也可以使用一些策略。拿 Nginx 来举例,它有两种方式:
- 使用“keepalive_timeout”指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。
- 使用“keepalive_requests”指令,设置长连接上可发送的最大请求次数。比如设置成 1000,那么当 Nginx 在这个连接上处理了 1000 个请求后,也会主动断开连接。
4.队头阻塞
“队头阻塞”与短连接和长连接无关,而是由 HTTP 基本的“请求 - 应答”模型所导致的。
因为 HTTP 规定报文必须是“一发一收”,这就形成了一个先进先出的“串行”队列。队列里的请求没有轻重缓急的优先级,只有入队的先后顺序,排在最前面的请求被最优先处理。如果队首的请求因为处理的太慢耽误了时间,那么队列里后面的所有请求也不得不跟着一起等待,结果就是其他的请求承担了不应有的时间成本。
5.性能优化
因为“请求 - 应答”模型不能变,所以“队头阻塞”问题在 HTTP/1.1 里无法解决,只能缓解,有什么办法呢?
- 使用“并发连接”(concurrent connections),也就是同时对一个域名发起多个长连接,用数量来解决质量的问题。
- “域名分片”(domain sharding)技术,还是用数量来解决质量的思路。
小结
- 早期的 HTTP 协议使用短连接,收到响应后就立即关闭连接,效率很低;
- HTTP/1.1 默认启用长连接,在一个连接上收发多个请求响应,提高了传输效率;
- 服务器会发送“Connection: keep-alive”字段表示启用了长连接;
- 报文头里如果有“Connection: close”就意味着长连接即将关闭;
- 过多的长连接会占用服务器资源,所以服务器会用一些策略有选择地关闭长连接;
- “队头阻塞”问题会导致性能下降,可以用“并发连接”和“域名分片”技术缓解。
四、HTTP的重定向和跳转
1.重定向概念
由服务器来发起的,浏览器使用者无法控制,相对地就可以称为“被动跳转”,也被叫做“重定向”
“Location”字段属于响应字段,必须出现在响应报文里。但只有配合 301/302 状态码才有意义,它标记了服务器要求重定向的 URI,这里就是要求浏览器跳转到“index.html”。
301俗称“永久重定向”(Moved Permanently),意思是原 URI 已经“永久”性地不存在了,今后的所有请求都必须改用新的 URI。
302俗称“临时重定向”(“Moved Temporarily”),意思是原 URI 处于“临时维护”状态,新的 URI 是起“顶包”作用的“临时工”。
2.重定向的应用场景
例如域名变更、服务器变更、网站改版、系统维护,这些都会导致原 URI 指向的资源无法访问,为了避免出现 404,就需要用重定向跳转到新的 URI,继续为网民提供服务。
另一个原因就是“避免重复”,让多个网址都跳转到一个 URI,增加访问入口的同时还不会增加额外的工作量。
3.重定向的相关问题
第一个问题“性能损耗”。很明显,重定向的机制决定了一个跳转会有两次请求 - 应答,比正常的访问多了一次。
第二个问题是“循环跳转”。如果重定向的策略设置欠考虑,可能会出现“A=>B=>C=>A”的无限循环,不停地在这个链路里转圈圈,后果可想而知。
小结
- 重定向是服务器发起的跳转,要求客户端改用新的 URI 重新发送请求,通常会自动进行,用户是无感知的;
- 301/302 是最常用的重定向状态码,分别是“永久重定向”和“临时重定向”;
- 响应头字段 Location 指示了要跳转的 URI,可以用绝对或相对的形式;
- 重定向可以把一个 URI 指向另一个 URI,也可以把多个 URI 指向同一个 URI,用途很多;
- 使用重定向时需要当心性能损耗,还要避免出现循环跳转。
五、HTTP的Cookie机制
HTTP 是“无状态”的,这既是优点也是缺点。优点是服务器没有状态差异,可以很容易地组成集群,而缺点就是无法支持需要记录状态的事务操作。
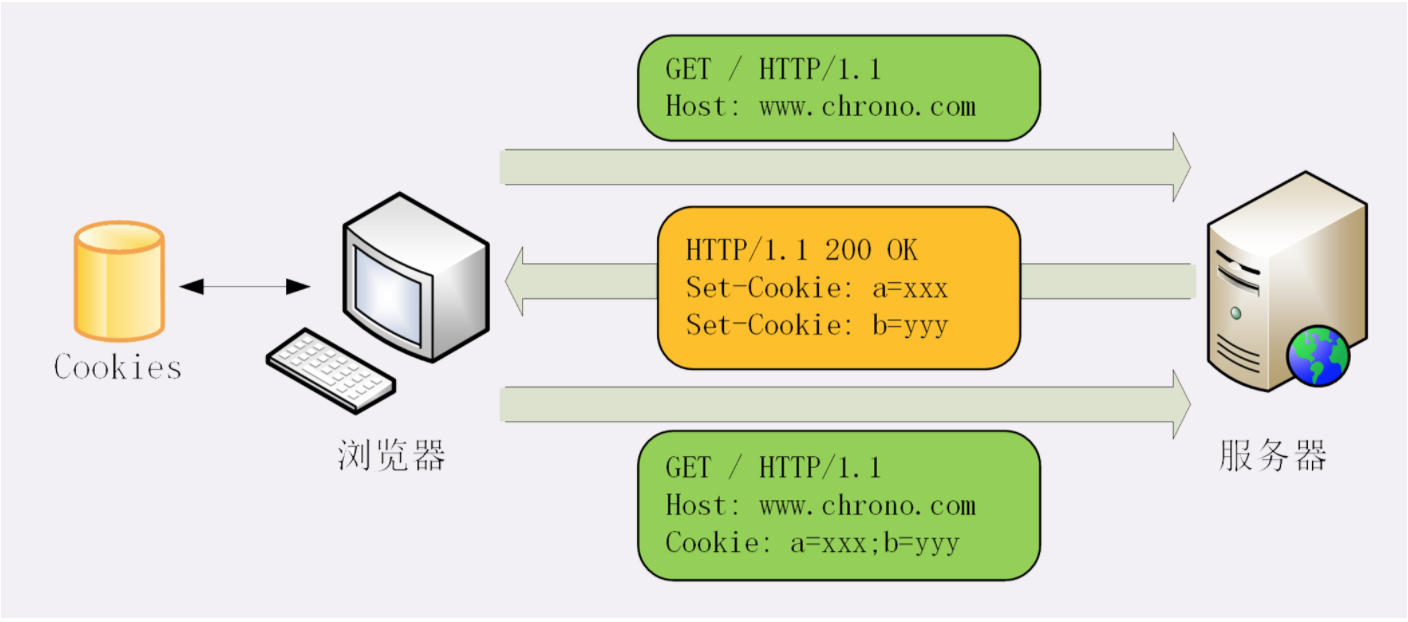
1.Cookie 的工作过程
响应头字段Set-Cookie和请求头字段Cookie。
- 当用户通过浏览器第一次访问服务器的时候,要创建一个独特的身份标识数据,格式是“key=value”,然后放进 Set-Cookie 字段里,随着响应报文一同发给浏览器。
- 浏览器收到响应报文,看到里面有 Set-Cookie,知道这是服务器给的身份标识,于是就保存起来,下次再请求的时候就自动把这个值放进 Cookie 字段里发给服务器。
- 因为第二次请求里面有了 Cookie 字段,服务器就知道这个用户不是新人,之前来过,就可以拿出 Cookie 里的值,识别出用户的身份。
- 服务器有时会在响应头里添加多个 Set-Cookie,存储多个“key=value”。但浏览器这边发送时不需要用多个 Cookie 字段,只要在一行里用“;”隔开就行。
注意问题:
Cookie 是由浏览器负责存储的,而不是操作系统。所以,它是“浏览器绑定”的,只能在本浏览器内生效。
2.Cookie 的属性
- “Expires”俗称“过期时间”,用的是绝对时间点,可以理解为“截止日期”(deadline)。
- “Max-Age”用的是相对时间,单位是秒,浏览器用收到报文的时间点再加上 Max-Age,就可以得到失效的绝对时间。
- “Domain”和“Path”指定了 Cookie 所属的域名和路径,浏览器在发送 Cookie 前会从 URI 中提取出 host 和 path 部分,对比 Cookie 的属性。如果不满足条件,就不会在请求头里发送 Cookie。
- “HttpOnly”会告诉浏览器,此 Cookie 只能通过浏览器 HTTP 协议传输,禁止其他方式访问,浏览器的 JS 引擎就会禁用 document.cookie 等一切相关的 API,脚本攻击也就无从谈起了。
- “SameSite”可以防范“跨站请求伪造”(XSRF)攻击,设置成“SameSite=Strict”可以严格限定 Cookie 不能随着跳转链接跨站发送,而“SameSite=Lax”则略宽松一点,允许 GET/HEAD 等安全方法,但禁止 POST 跨站发送。
- “Secure”,表示这个 Cookie 仅能用 HTTPS 协议加密传输,明文的 HTTP 协议会禁止发送。但 Cookie 本身不是加密的,浏览器里还是以明文的形式存在。
3.Cookie 的应用
- Cookie 最基本的一个用途就是身份识别,保存用户的登录信息,实现会话事务。
- Cookie 的另一个常见用途是广告跟踪。
小结
- Cookie 是服务器委托浏览器存储的一些数据,让服务器有了“记忆能力”;
- 响应报文使用 Set-Cookie 字段发送“key=value”形式的 Cookie 值;
- 请求报文里用 Cookie 字段发送多个 Cookie 值;
- 为了保护 Cookie,还要给它设置有效期、作用域等属性,常用的有 Max-Age、Expires、Domain、HttpOnly 等;
- Cookie 最基本的用途是身份识别,实现有状态的会话事务。
六、HTTP的缓存控制
基于“请求 - 应答”模式的特点,可以大致分为客户端缓存和服务器端缓存
1.服务器的缓存控制
1.1 流程
- 浏览器发现缓存无数据,于是发送请求,向服务器获取资源;
- 服务器响应请求,返回资源,同时标记资源的有效期;
- 浏览器缓存资源,等待下次重用。
1.2 缓存其他属性
服务器标记资源有效期使用的头字段是“Cache-Control”,里面的值“max-age=30”就是资源的有效时间,相当于告诉浏览器,“这个页面只能缓存 30 秒,之后就算是过期,不能用。”
其他的属性:
- no_store:不允许缓存,用于某些变化非常频繁的数据,例如秒杀页面;
- no_cache:它的字面含义容易与 no_store 搞混,实际的意思并不是不允许缓存,而是可以缓存,但在使用之前必须要去服务器验证是否过期,是否有最新的版本;
- must-revalidate:又是一个和 no_cache 相似的词,它的意思是如果缓存不过期就可以继续使用,但过期了如果还想用就必须去服务器验证。
https://github.com/amandakelake/blog/issues/41
2.客户端的缓存控制
当你点“刷新”按钮的时候,浏览器会在请求头里加一个“Cache-Control: max-age=0”。因为 max-age 是“生存时间”。
3.条件请求
最常用的是“if-Modified-Since”和“If-None-Match”这两个。需要第一次的响应报文预先提供“Last-modified”和“ETag”,然后第二次请求时就可以带上缓存里的原值,验证资源是否是最新的。如果资源没有变,服务器就回应一个“304 Not Modified”,表示缓存依然有效,浏览器就可以更新一下有效期,然后放心大胆地使用缓存了。
小结
- 缓存是优化系统性能的重要手段,HTTP 传输的每一个环节中都可以有缓存;
- 服务器使用“Cache-Control”设置缓存策略,常用的是“max-age”,表示资源的有效期;
- 浏览器收到数据就会存入缓存,如果没过期就可以直接使用,过期就要去服务器验证是否仍然可用;
- 验证资源是否失效需要使用“条件请求”,常用的是“if-Modified-Since”和“If-None-Match”,收到 304 就可以复用缓存里的资源;
- 验证资源是否被修改的条件有两个:“Last-modified”和“ETag”,需要服务器预先在响应报文里设置,搭配条件请求使用;
- 浏览器也可以发送“Cache-Control”字段,使用“max-age=0”或“no_cache”刷新数据。
七、HTTP的代理服务
所谓的“代理服务”就是指服务本身不生产内容,而是处于中间位置转发上下游的请求和响应,具有双重身份:面向下游的用户时,表现为服务器,代表源服务器响应客户端的请求;而面向上游的源服务器时,又表现为客户端,代表客户端发送请求。
- HTTP 代理就是客户端和服务器通信链路中的一个中间环节,为两端提供“代理服务”;
- 代理处于中间层,为 HTTP 处理增加了更多的灵活性,可以实现负载均衡、安全防护、数据过滤等功能;
- 代理服务器需要使用字段“Via”标记自己的身份,多个代理会形成一个列表;
- 如果想要知道客户端的真实 IP 地址,可以使用字段“X-Forwarded-For”和“X-Real-IP”;
- 专门的“代理协议”可以在不改动原始报文的情况下传递客户端的真实 IP。
八、HTTP的缓存代理
- 计算机领域里最常用的性能优化手段是“时空转换”,也就是“时间换空间”或者“空间换时间”,HTTP 缓存属于后者;
- 缓存代理是增加了缓存功能的代理服务,缓存源服务器的数据,分发给下游的客户端;
- “Cache-Control”字段也可以控制缓存代理,常用的有“private”“s-maxage”“no-transform”等,同样必须配合“Last-modified”“ETag”等字段才能使用;
- 缓存代理有时候也会带来负面影响,缓存不良数据,需要及时刷新或删除。

若有收获,就点个赞吧
0 人点赞
