一、调和过程与 Diff 算法
1. 什么是调和
通过如 ReactDOM 等类库使虚拟 DOM 与“真实的” DOM 同步,这一过程叫作协调(调和)。通俗的讲调和指的是将虚拟 DOM映射到真实 DOM 的过程。因此严格来说,调和过程并不能和 Diff 画等号。调和是“使一致”的过程,而 Diff 是“找不同”的过程,它只是“使一致”过程中的一个环节。
2. Diff 策略的设计思想
找出两个树结构之间的不同, 传统的计算方法是通过循环递归进行树节点的一一对比,这个过程的算法复杂度是 O (n³) 。
O (n³) 复杂度转换成 O (n) 复杂度:
- 若两个组件属于同一个类型,那么它们将拥有相同的 DOM 树形结构;
- 处于同一层级的一组子节点,可用通过设置 key 作为唯一标识,从而维持各个节点在不同渲染过程中的稳定性。
3. 把握 Diff 逻辑
- Diff 算法性能突破的关键点在于“分层对比”;
- 类型一致的节点才有继续 Diff 的必要性;
- key 属性的设置,可以帮我们尽可能重用同一层级内的节点。
3.1 改变时间复杂度量级的决定性思路:分层对比
它只针对相同层级的节点作对比,如下图所示。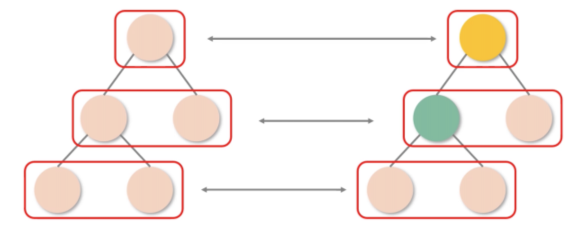
需要注意的是:虽然栈调和将传统的树对比算法优化为了分层对比,但整个算法仍然是以递归的形式运转的,分层递归也是递归。
销毁 + 重建的代价是昂贵的,尽量保持 DOM 结构的稳定性。所以React发生了跨层级的节点操作,它只能机械地认为移出子树那一层的组件消失了,对应子树需要被销毁;而移入子树的那一层新增了一个组件,需要重新为其创建一棵子树。
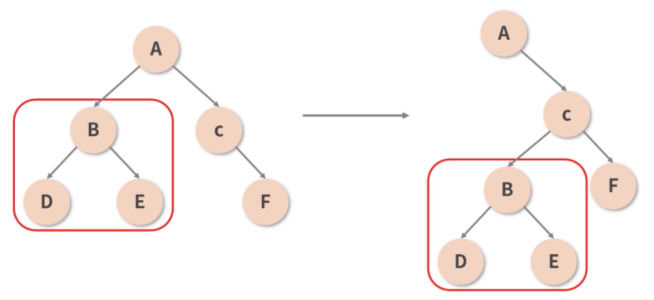
3.2 减少递归的“一刀切”策略:类型的一致性决定递归的必要性
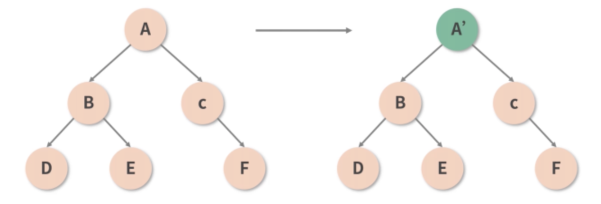
React 认为,只有同类型的组件,才有进一步对比的必要性;若参与 Diff 的两个组件类型不同,那么直接放弃比较,原地替换掉旧的节点,如下图所示。只有确认组件类型相同后,React 才会在保留组件对应 DOM 树(或子树)的基础上,尝试向更深层次去 Diff。这样一来,便能够从很大程度上减少 Diff 过程中冗余的递归操作。
3.3 重用节点的好帮手:key 属性帮 React “记住”节点
key属性的设置,可以帮我们尽可能重用同一层级内的节点。

key 是用来帮助 React 识别哪些内容被更改、添加或者删除。key 需要写在用数组渲染出来的元素内部,并且需要赋予其一个稳定的值。稳定在这里很重要,因为如果 key 值发生了变更,React 则会触发 UI 的重渲染。这是一个非常有用的特性。
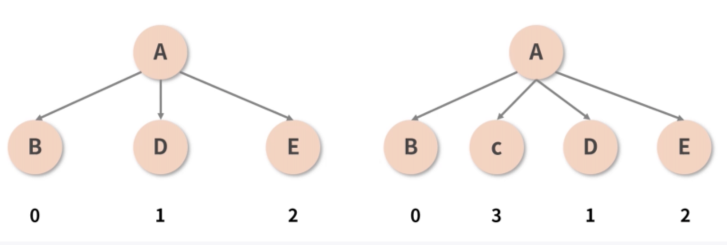
这个 key 就充当了每个节点的 ID(唯一标识),有了这个标识之后,当 C 被插入到 B 和 D 之间时,React 并不会再认为 C、D、E 这三个坑位都需要被重建——它会通过识别 ID,意识到 D 和 E 并没有发生变化(D 的 ID 仍然是 1,E 的 ID 仍然是 2),而只是被调整了顺序而已。接着,React 便能够轻松地重用它“追踪”到旧的节点,将 D 和 E 转移到新的位置,并完成对 C 的插入。这样一来,同层级下元素的操作成本便大大降低。

若有收获,就点个赞吧
0 人点赞
