倒排
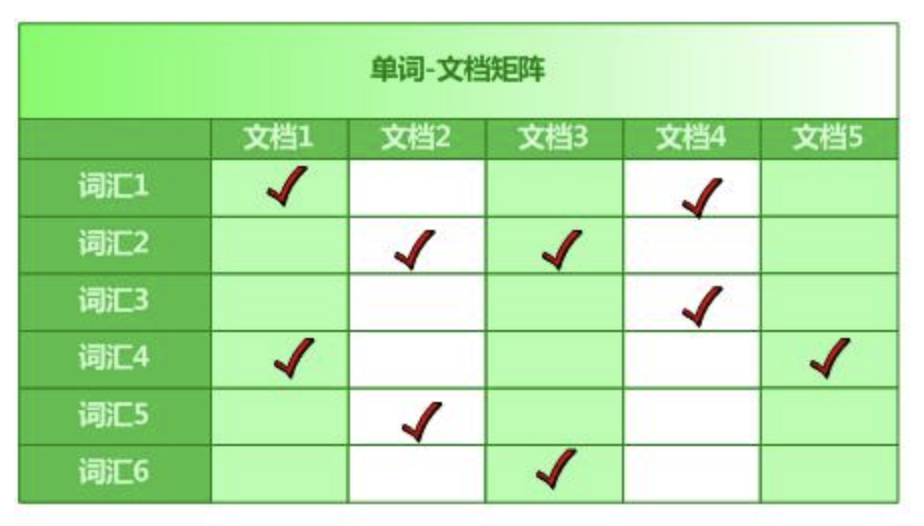
倒排索引,即利用关键词索引到相关文档,形成关键词文档矩阵,行对应词(按频率排序),列对应文档。
基本步骤:
- 按照词频将所有词排序
- 记录每个词对应出现过的文档
- 计算相似度(最简单的是按照词条匹配的数量)
相关trick优化:
- 大小写转化:全部转化为小写
- 词干提取归一
- 同义词归一
因为我们只能搜索在索引中出现的词条,索引文本和查询字符串必须标准归一化为相同的格式。
NDCG(检索评价指标)
NDCG,Normalized Discounted cumulative gain 直接翻译为归一化折损累计增益。这个指标通常是用来衡量和评价搜索结果算法。DCG的两个评价原则:
- 总体越相关的结果,最终得分越高
- 高关联结果出现的位置越靠前,最终得分越高
首先看一下CG(累积增益),它没有考虑到位置的优先级,只是把所有的搜索结果的相关性求和: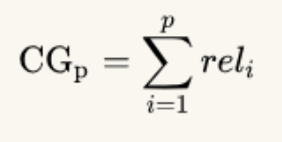 ,reli 代表i这个位置上的相关度,p代表搜索得到p个结果。
,reli 代表i这个位置上的相关度,p代表搜索得到p个结果。
再来看一下DCG,在CG的基础上加了折损,即将位置信息考虑进来,越靠前,其相关性所占权重越大: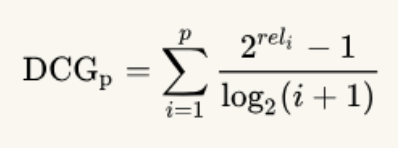 。
。
最后看一下NDCG,在DCG的基础上加了归一化。因为不同搜索结果,召回的数量不同,需要进行归一化统一量纲,才能进行比较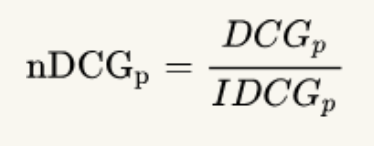 。其中IDCG是检索召回的p个结果的理想最优DCG,即最大的DCG值。
。其中IDCG是检索召回的p个结果的理想最优DCG,即最大的DCG值。
举个例子:如果实际检索召回了6个结果,其相关性系数分别是3、2、3、0、1、2,那么CG=3+2+3+0+1+2,DCG会计算其位置对应的权重再求和,NDCG会先计算IDCG,即先计算理想顺序为3、3、2、2、1、0对应的IDCG,再根据DCG/IDCG得到归一化后的NDCG。
海量数据的相似度比较(MinHashing、LSH)
MinHashing通过将向量A、B映射到低维空间中的两个签名向量,并且近似保持A、B之间的相似度,降低了用户相似度在物品维度很高的情况下的计算复杂度。
LSH方法基于这样的思想:在原空间中很近(相似)的两个点,经过LSH哈希函数的映射后,有很大概率它们的哈希是一样的;而两个离的很远(不相似)的两个点,映射后,它们的哈希值相等的概率很小。
LSH的具体做法是在Min Hashing所得的signature向量的基础上,将每一个向量分为几段,称之为band,
参考文献

若有收获,就点个赞吧
0 人点赞
