MySQL/MongoDB/ES/Redis/HBase对比
0. 关系型和非关系型数据库
关系型数据库:安全(数据存储在磁盘中)、容易理解(建立在关系模型上)、但不节省空间(因为建立在关系模型上,就要遵循某些规则,好比数据中某字段值即使为空仍要分配空间)
非关系型数据库:效率高(因为存储在内存中)、但不安全(断电丢失数据,但其中redis可以同步数据到磁盘中),现在很多非关系型数据库都开始支持转存到磁盘中。
1. mysql
优点:
属于关系型数据库,适用于数据的逻辑结构非常复杂,经常需要进行复杂的多表查询或者事务操作
缺点:
MySQL写数据像是在做填空题,你写入的数据必须与最早定义的表结构一致,灵活性较差
2. mongoDB
优点:
表结构灵活可变,字段类型可以随时修改。
MongoDB很适合那些表结构经常改变,数据的逻辑结构没又没那么复杂不需要多表查询操作,数据量又比较大的应用场景。
缺点:
MongoDB不需要定义表结构这个特点给表结构的修改带来了极大的方便,但是也给多表查询、复杂事务等高级操作带来了阻碍。
3. Redis
优点:
key-value存储所带来的简单和高性能。没有诸如表、字段这些常规数据库中必需有的复杂概念,所有的查询都仅仅依赖于key值。
Redis会把所有数据加载到内存中的,Redis能得到远高于MongoDB这类常规数据库的读写性能。
特别适合那些对读写性能要求极高,且数据表结构简单(key-value、list、set之类)、查询条件也同样简单的应用场景。
缺点:
由于阉割掉了数据表、字段这样的重要特性,且所有的查询都依赖key,因此Redis无法提供常规数据库所具备的多列查询、区段查询等复杂查询功能。
由于Redis需要把数据存在内存中,这也大大限制了Redis可存储的数据量,这也决定了Redis难以用在数据规模很大的应用场景中。
4. ES(ElasticSearch)
优点:
严格的说,ES不是一个数据库,而是一个搜索引擎,ES的方方面面也都是围绕搜索设计的。ES通过建立倒排索引实现全文搜索。
具体来说,ES会建立一个覆盖表中所有文档、所有字段的庞大的倒排索引,以实现对存入ES中的所有数据进行快速检索。因此只要是存入ES的数据,无论再复杂的聚合查询也可以得到不错的性能,而且你再也不用为如何建立各种复杂索引而头痛了。
ES的全文搜索特性使它成为构建搜索引擎的利器。除此之外,ES很好的支持了复杂聚合查询这一特点还使得ES非常适合拿来作数据分析使用。
缺点:
最明显的就是字段类型无法修改、写入性能较低和高硬件资源消耗。ES的写入默认1S的写入延迟,也就是说你的数据在写入后要至少等1S才能被查询到。
ES需要在创建字段前要预先建立Mapping,Mapping中包含每个字段的类型信息,ES需要根据Mapping为字段建立合适的索引。由于这个Mapping的存在,ES中的字段一但建立就不能再修改类型了。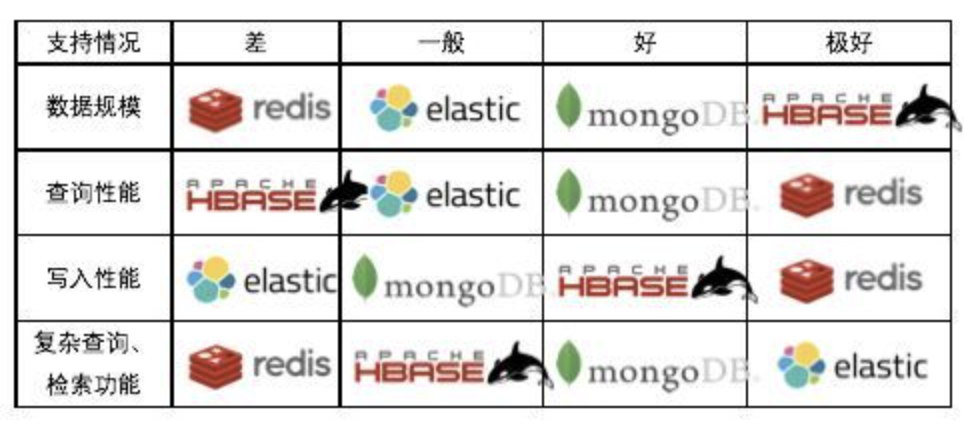
四大特性(ACID)
- 原子性(Atomicity):事务包含的所有操作要么全部成功,要么全部失败回滚。失败回滚的操作事务,将不能对事物有任何影响。
- 一致性(Consistency):事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
- 隔离性(Isolation):当多个用户并发访问数据库时,比如同时访问一张表,数据库每一个用户开启的事务,不能被其他事务所做的操作干扰,多个并发事务之间,应当相互隔离。
- 持久性(Durability):事务的操作,一旦提交,对于数据库中数据的改变是永久性的,即使数据库发生故障也不能丢失已提交事务所完成的改变。
常用命令
```pythonhive 建表操作
HQL=”CREATE EXTERNAL TABLE violent_sta_wujingqiao( date STRING COMMENT ‘日期’, submit_num STRING COMMENT ‘提交量’ ) PARTITIONED BY (dt STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ STORED AS TEXTFILE LOCATION ‘cosn://zyb-offline/user/wujingqiao/violent_sta’;” hive -e “${HQL}”
删除表
DROP TABLE table_name ;
修改表名字
rename table 原表名 to 新表名;
增加字段,并移动顺序
alter table table_name add columns (c_time string comment ‘当前时间’); — 正确,添加在最后 alter table table_name change c_time c_time string after address ; — 正确,移动到指定位置,address字段的后面
修改字段名字
alter table table_name rename column oldname to newname;
转换百分数
CONCAT(ROUND(短信有意愿用户占比 * 100, 2), “%”) AS 短信有意愿用户占比,
\G 的作用是将查到的结构旋转90度变成纵向<a name="EfGAf"></a>### 利用中间表取出整条groupby 后的数据```shellselect * from table where num in(select max(num) from table group by phone)
ES
# 完全匹配、精确查询
# 注意对于iii-jjj-kk,直接用term可能会查询失败,这和索引数据的方式有关
# 可将索引设置为not_analyzed 无需分析的解决,或者通过match_phrase短语匹配来解决
term
# match查询会先对搜索词进行分词,分词完毕后再逐个对分词结果进行匹配
# 只要文中出现过分词后中的任意一个,则匹配成功,不关注顺序和紧邻,而match_phrase关注顺序和紧邻
# 因此相比于term的精确搜索,match是分词匹配搜索
# match搜索还有两个相似功能的变种,一个是match_phrase,一个是multi_match
match
match_phrase
常用sql
多行转多列
select 姓名,
sum(case when 课程='语文' then 分数 else 0 end) 语文,
sum(case when 课程='数学' then 分数 else 0 end) 数学,
sum(case when 课程='物理' then 分数 else 0 end) 物理,
sum(case when 课程='英语' then 分数 else 0 end) 英语,
sum(case when 课程='德语' then 分数 else 0 end) 德语
from tb
group by 姓名

若有收获,就点个赞吧
0 人点赞
