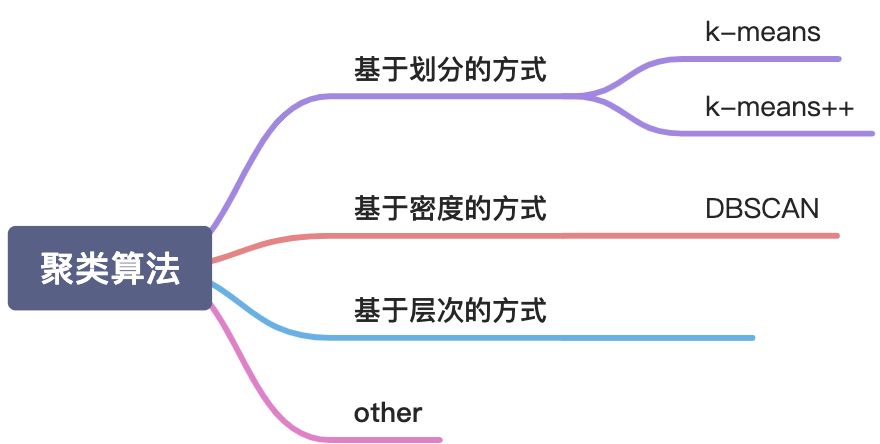
整体聚类算法分类
各算法优缺点
| 算法 | 优点 | 缺点 |
|---|---|---|
| k-means | 1. 该算法时间复杂度为O(tkmn),(其中,t为迭代次数,k为簇的数目,m为记录数,n为维数)与样本数量线性相关,所以,对于处理大数据集合,该算法非常高效,且伸缩性较好; |
1. 聚类中心的个数K需要事先给定 1. Kmeans需要人为地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果。(kmeans++针对该点进行了优化,即初始的聚类中心之间的相互距离要尽可能的远) 1. 结果不一定是全局最优,只能保证局部最优(因为采取的是启发式的迭代方法) 1. 对于非凸(球形)不规则的数据集比较难收敛 1. 对噪音和异常点比较的敏感。 |
| DBSCAN | 1. 可以处理任何形状的聚类簇、能够检测异常点 |
1. 需要给定数据点的半径r和最少数量m、对输入参数较敏感。 |
DBSCAN
参考文献

若有收获,就点个赞吧
0 人点赞
