1. 透视表(Pivot table)
数据透视表简单来说就是把明细表进行分类汇总的过程,你可以按照不同的组合方式进行数据计算。
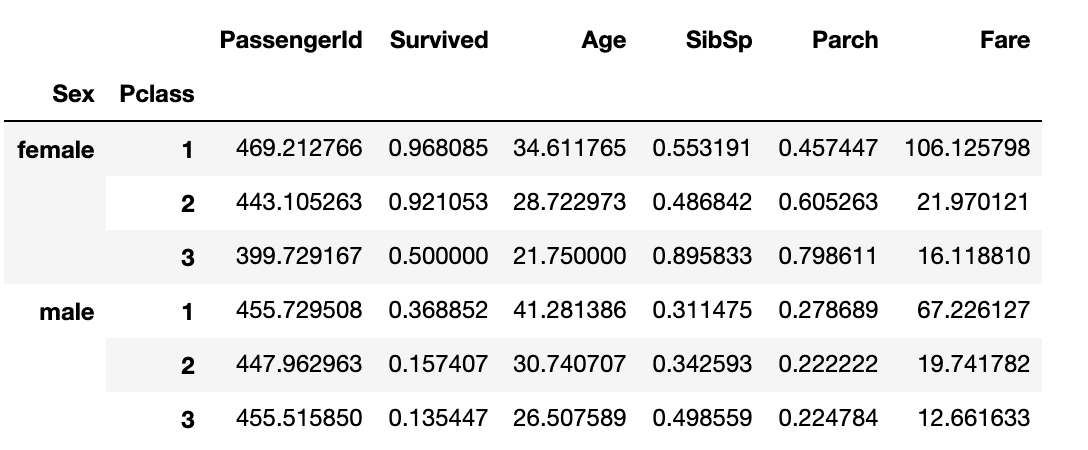
# 方法一:使用groupbytrain_df.groupby(['Sex', 'Pclass']).mean()# 方法二:使用pivot_tablepd.pivot_table(train_df, index=['Sex', 'Pclass'], margins=True)
2. 交叉表(cross table)
交叉表是一种用于计算分组频率的特殊透视表。
# 方法一:用pivot_tablepd.pivot_table(train_df[['Sex', 'Pclass', 'Survived']], index=['Sex', 'Pclass'], columns=['Survived'], aggfunc=len, margins=True)# 方法二:用crosstabpd.crosstab([train_df.Sex, train_df.Pclass], train_df.Survived)#这里需要注意pandas中交叉表的前两个参数为array或series类型,与透视表的有所不同。
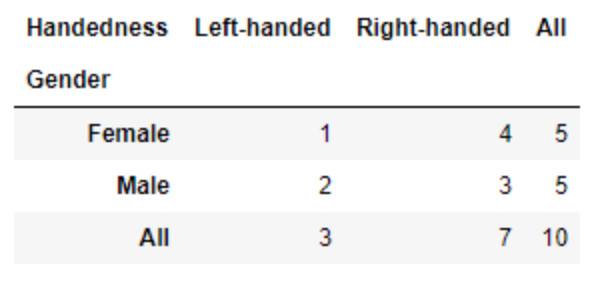
透视表pivot_table()是一种进行分组统计的函数,参数aggfunc决定统计类型;
交叉表crosstab()是一种特殊的pivot_table(),专用于计算分组频率。

若有收获,就点个赞吧
0 人点赞
