RNN
基础
传统的DNN的神经元输入只有x,输出只有y,无法解决有一定距离的信息的互相传输和影响。针对NLP这种不同位置均有相互依赖关系的场景效果不好。
RNN对此做了优化,输入不仅是上一个神经元的输出x,还包括上一时刻当前神经元的输出作为输入,即将之前时间片的信息也用于计算当前时间片的内容,而传统模型的隐节点的输出只取决于当前时间片的输入特征。
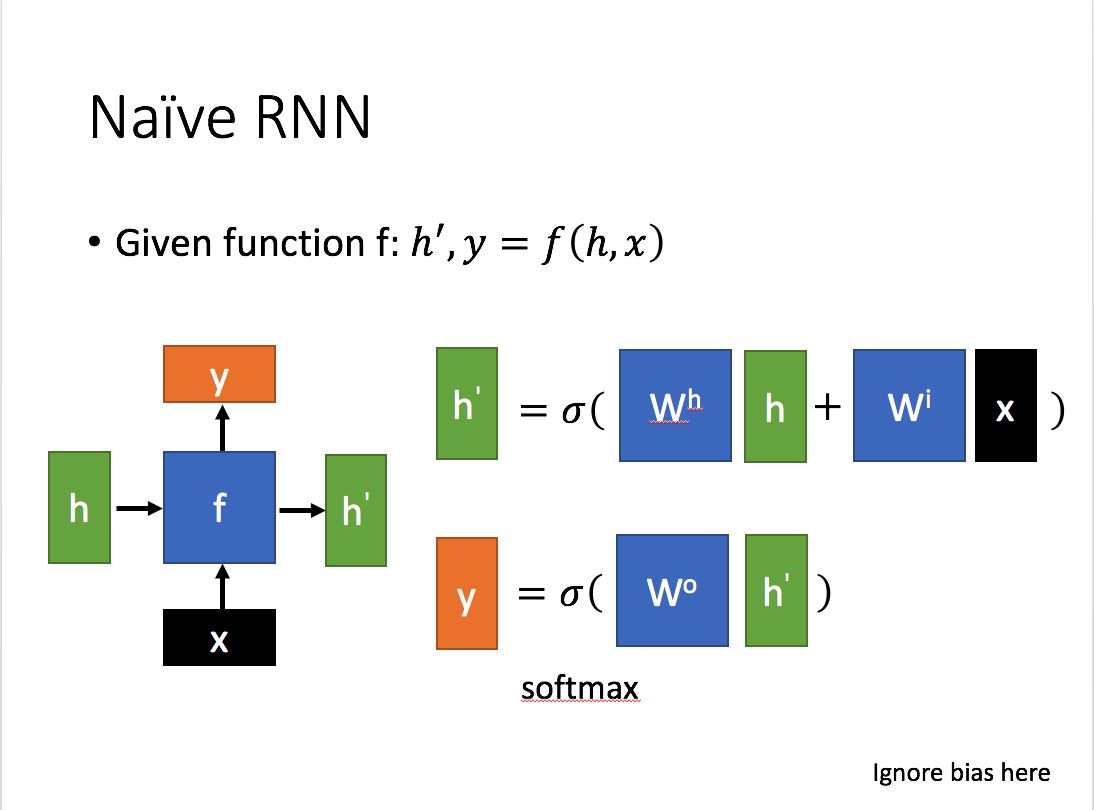

RNN的两种训练模型
- free-running mode
free-running mode就是大家常见的那种训练网络的方式: 上一个state的输出作为下一个state的输入
- teacher-forcing mode
它每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入
该模式优点:
- Teacher-Forcing 能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大。
- Teacher-Forcing 能够极大的加快模型的收敛速度,令模型训练过程更加快&平稳。
- Teacher-Forcing 技术是保证 Transformer 模型能够在训练过程中完全并行计算所有token的关键技术。
该模式缺点:
由于训练和预测的时候decode行为的不一致, 导致预测单词(predict words)在训练和预测的时候是从不同的分布中推断出来的。而这种不一致导致训练模型和预测模型直接的Gap,就叫做 Exposure Bias。
LSTM
LSTM(Long Short-Term Memory)出现主要解决了两个问题
- 解决长依赖问题。
长期依赖产生的原因是当神经网络的节点经过许多阶段的计算后,之前比较长的时间片的特征已经被覆盖。因为RNN的逻辑是当前状态神经元值取决于上个状态,而很久之前的状态几乎被覆盖,从而导致信息的流失。
- 缓解梯度消失问题。
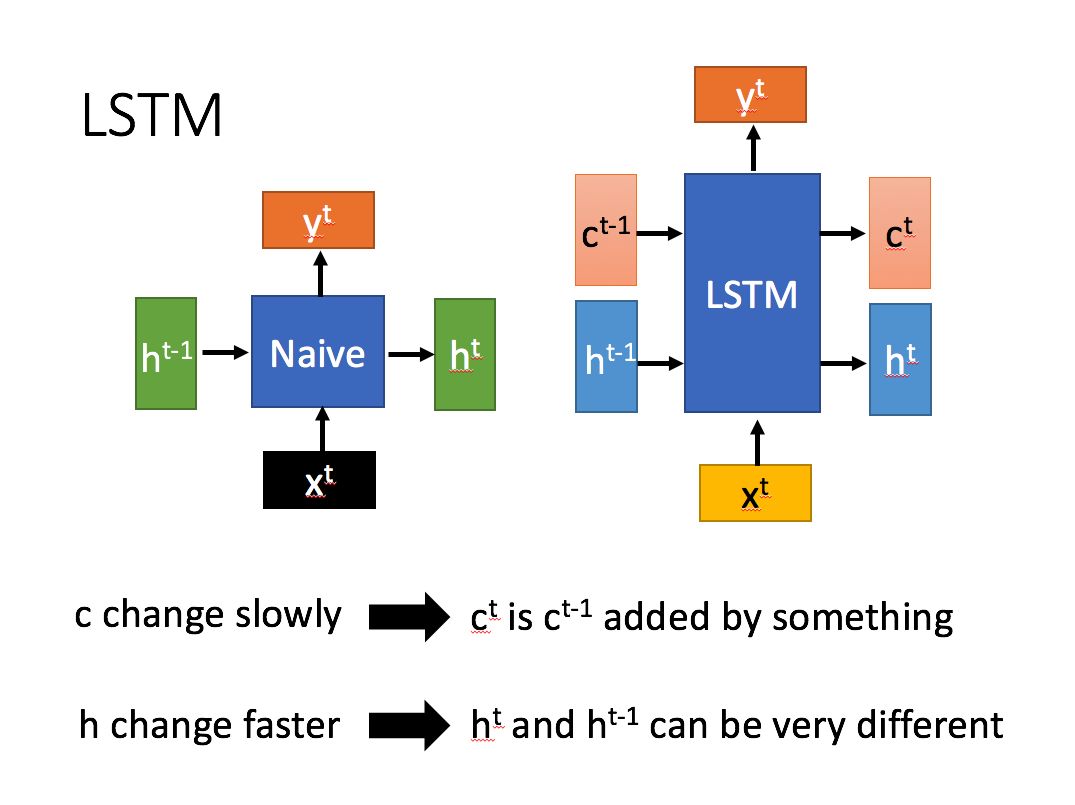
LSTM在RNN的基础上,每个神经元的输入和输出分别增加了细胞状态(cell state)。
神经元内部具体根据三个输入映射到三个输出的具体方式:
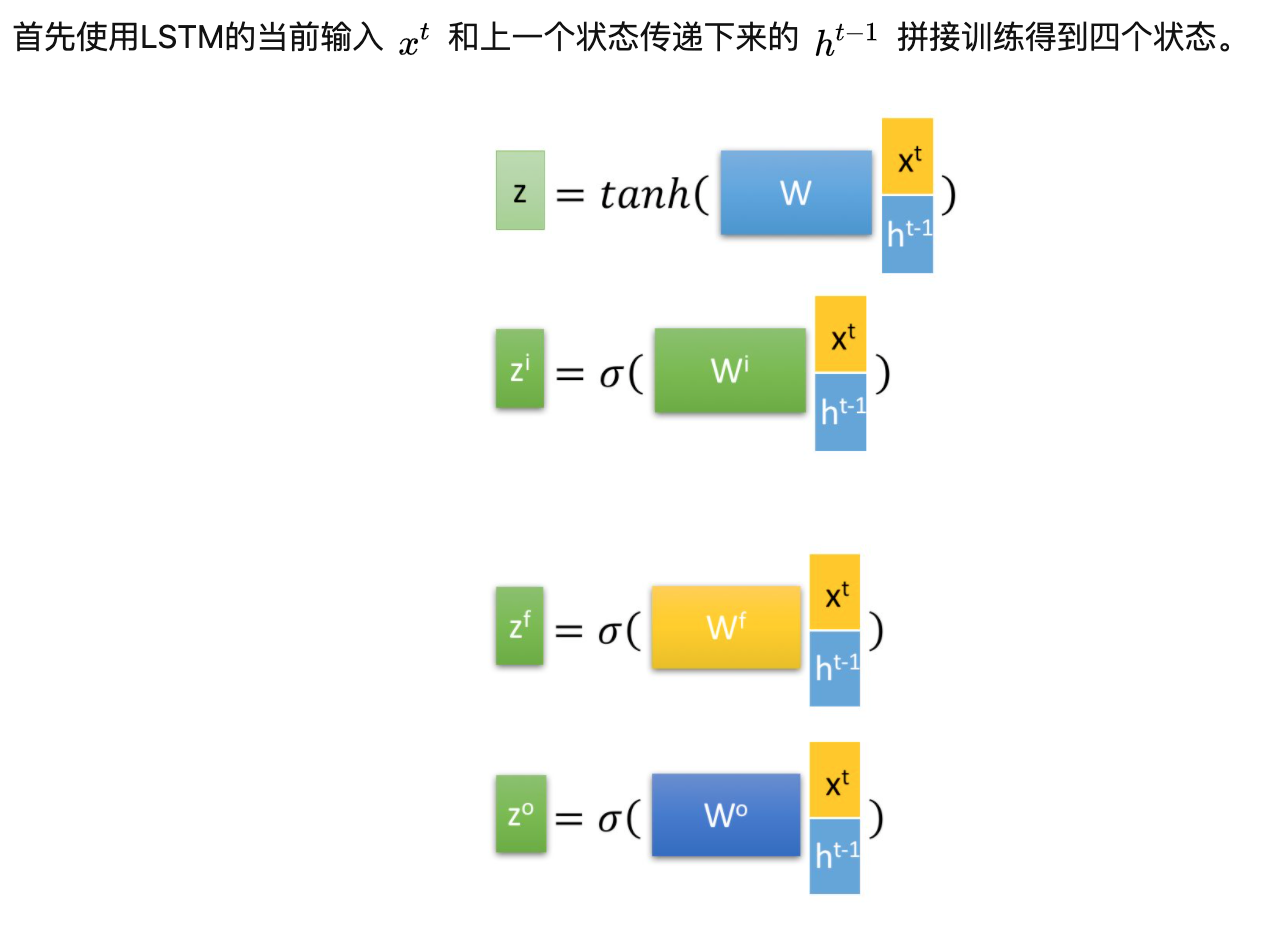
其中Zf为遗忘门(forget),Zi为输入门(input),Zo为输出门(ouput)。其中利用了不同的激活函数是因为,zf、i、o为门控信号需要将值映射为0~1区间,更拟合门的方式,而z为输入的数据。具体原因可以见末尾节的细节思考一章。
GRU
GRU(Gate Recurrent Unit)的优点
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
GRU和输入和输出与RNN一致: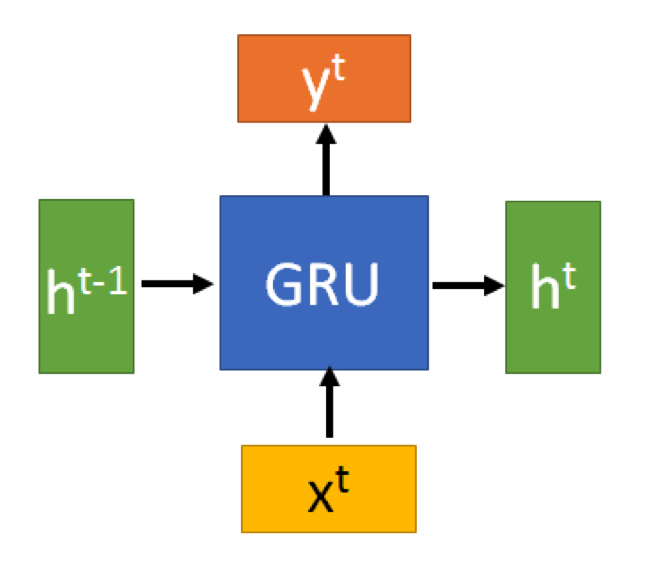
内部具体处理逻辑,比LSTM少了一个门,所以参数量也减少了许多:
和LSTM类似,对于ht-1和xt进行整合,映射为两个门信号: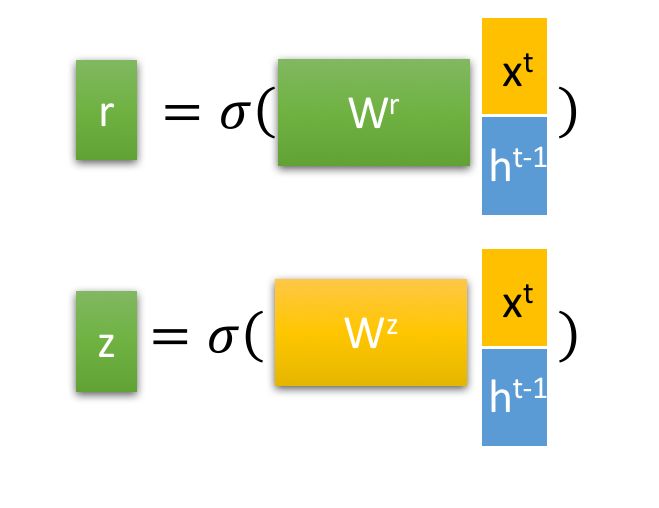
r为重置门,z为控制更新门,起到选择以及遗忘的作用。
先用重置门将输入重置: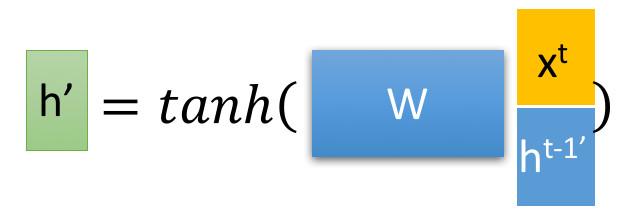
随后使用更新门z获取ht: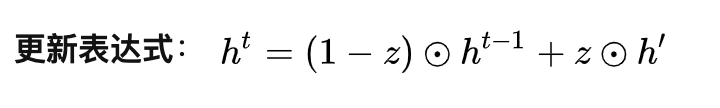
GRU使用一个更新门z就代替了LSTM中的两个门(遗忘门和输出门),从而起到遗忘和选择的作用。
GRU与LSTM关系
- LSTM(1997)提出时间远早于GRU(2014)
- GRU相比LSTM,效果几乎相当,但因为少了一个门,参数量减少,效率较高。
思考细节
1. LSTM为什么使用两种激活函数?
在LSTM中,遗忘门、输入门和输出门使用 Sigmoid函数作为激活函数;在生成候选记忆时,使用双曲正切函数tanh作为激活函数。值得注意的是,这两个激活函数都是饱和的也就是说在输入达到一定值的情况下,输出就不会发生明显变化了。如果是用非饱和的激活图数,例如ReLU,那么将难以实现门控的效果。
两种激活函数用到的地方不同。 sigmoid函数主要用于各种门信号的生成转换。其输出在0-1之同,符合门控的物理定义,且当输入较大或较小时,其输出会非常接近1或0,从而保证该门开或关。
tanh函数用于状态和输出上,是对数据的处理,这个函数也可以用其他函数替代。在生成候选记亿时,使用tanh函数,是因为其输出在-1-1之间,这与大多数场景下特征分布是0中心的吻合。此外,tanh函数在输入为0近相比 Sigmoid函数有更大的梯度,通常使模型收敛更快。
激活函数的选择也不是一成不变的。例如在原始的LSTM中,使用的激活函数是 Sigmoid函数的变种,h(x)=2sigmoid(x)-1,g(x)=4 sigmoid(x)-2,这两个函数的范国分别是[-1,1]和[-2,2]。并且在原始的LSTM中,只有输入门和输出门,没有遗忘门,其中输入经过输入门后是直接与记忆相加的,所以输入门控g(x)的值是0中心的。后来经过大量的研究和实验,人们发现增加遗忘门对LSTM的性能有很大的提升且h(x)使用tanh比2 sigmoid(x)-1要好,所以现代的LSTM采用 Sigmoid和tanh作为激活函数。事实上在门控中,使用 Sigmoid函数是几乎所有现代神经网络模块的共同选择。例如在门控循环单元和注意力机制中,也广泛使用 Sigmoid i函数作为门控的激活函数。
此外,在一些对计算能力有限制的设备,诸如可穿戴设备中,由于 Sigmoid函数求指数需要一定的计算量,此时会使用0/1门让门控输出为0或1的离散值,即当输入小于阈值时,门控输出为0;当输入大于阈值时,输出为1。从而在性能下降不著的情况下,减小计算量。
2. LSTM为什么能够缓解梯度消失/爆炸,如何缓解?
- LSTM的动机是给这个递归的梯度加一个常量。有了这个,就不会梯度爆炸或者消失了。为了实现这个目的,LSTM隐入了一个cell状态 Ct。
- cell状态的加法更新策略使得梯度传递更恰当。
- 门控单元可以决定遗忘多少梯度,他们可以在不同的时刻取不同的值。这些值都是通过隐层状态和输入的函数学习到的。
3. LSTM中为什么Ct改变缓慢,ht改变波动剧烈?
ct主要作用是综合保存当前状态节点和上个节点的权衡,所以每次只会改变一些。 而ht主要作用是和当前输入组合获取门孔信号信息的,对于不同的当前输入,传递给下个状态的ht也会变化较大。
参考文献
一文弄懂关于循环神经网络(RNN)的Teacher Forcing训练机制 人人都能看懂的LSTM 详解LSTM 为什么LSTM会减缓梯度消失?

若有收获,就点个赞吧
0 人点赞
