
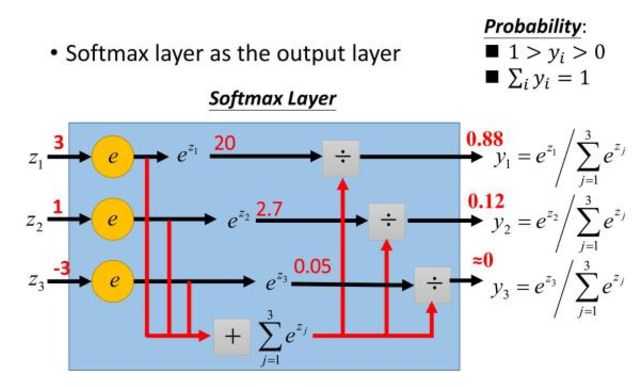
激活函数
sigmoid/softmax
函数形式:
函数图像: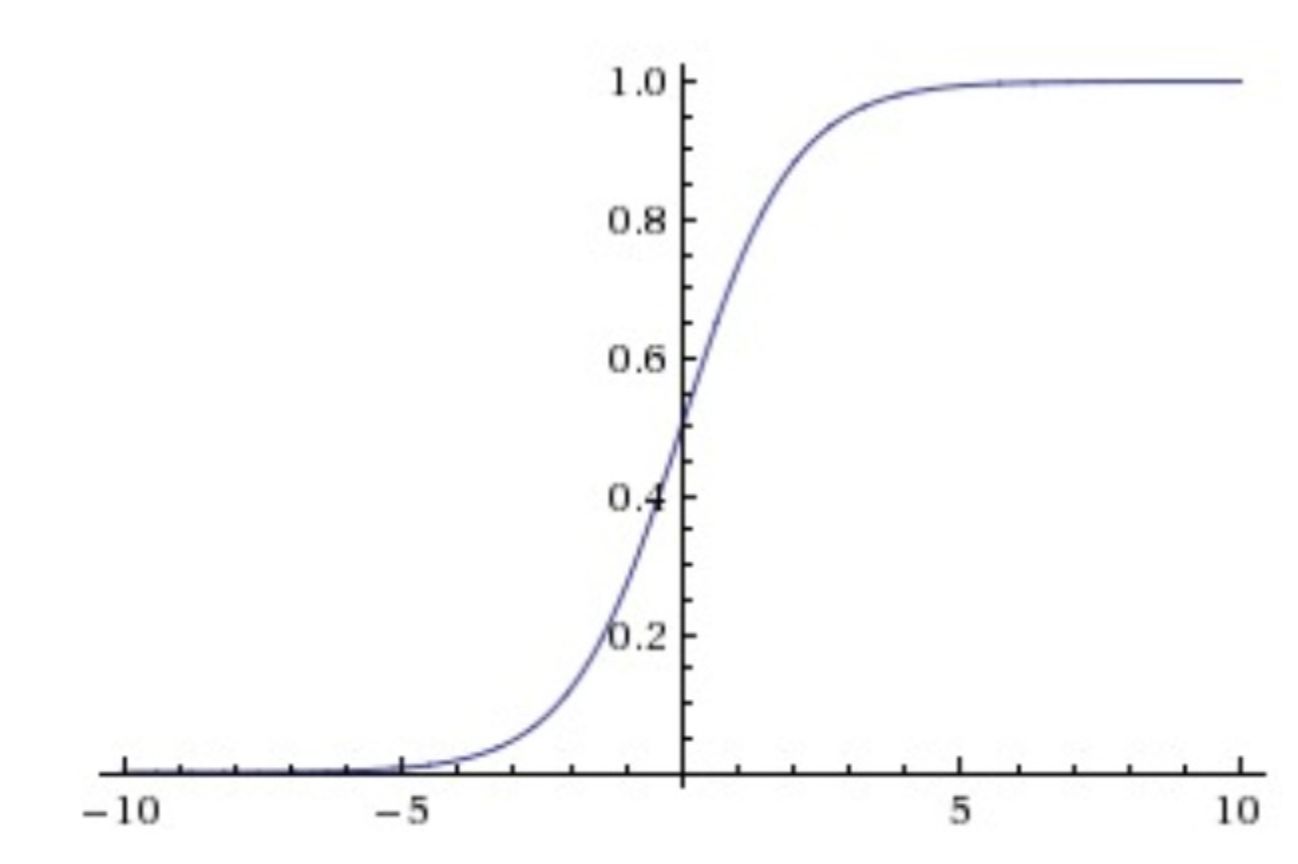
函数性质:

- 存在饱和区。对于过大或过小的输入,Sigmoid函数会产生饱和使梯度消失。当神经元的激活在接近0或1处时会饱和,在这些区域梯度几乎为0,这就会导致梯度消失,几乎就有没有信号通过神经传回上一层。
- 有指数运算,计算量大。
- 不以0为中心,输出值为正直。这会导致在BP时,多个参数的更新都是统一方向,要么全部正,要么全部负,从而出现zigzag现象,使收敛缓慢(可通过tanh函数解决)

softmax函数是sigmoid的扩展,当类别数k=2时,softmax等价于sigmoid。
tanh
函数形式:
函数图像: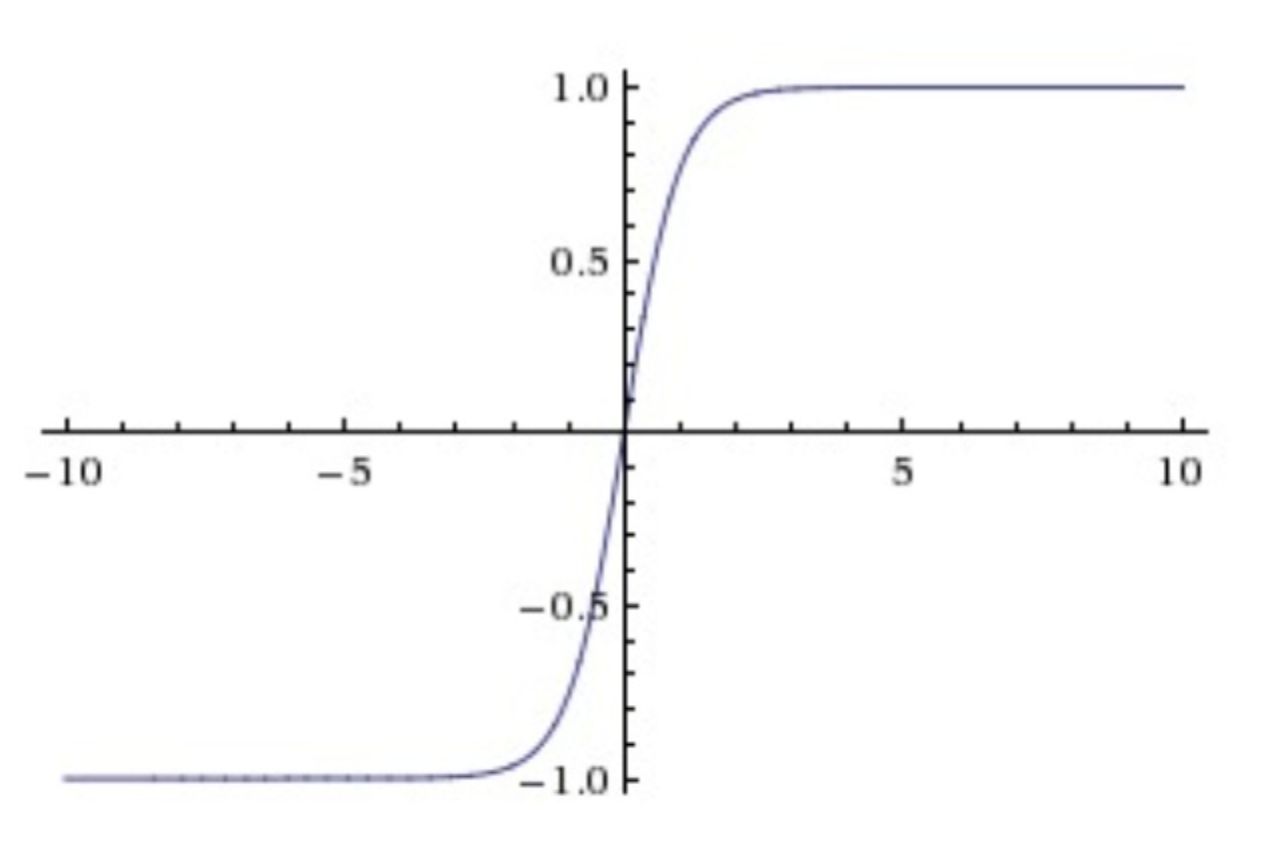
函数性质:
- tanh函数是sigmoid函数向下平移和收缩后的结果。
-
ReLU
函数形式:

函数图像: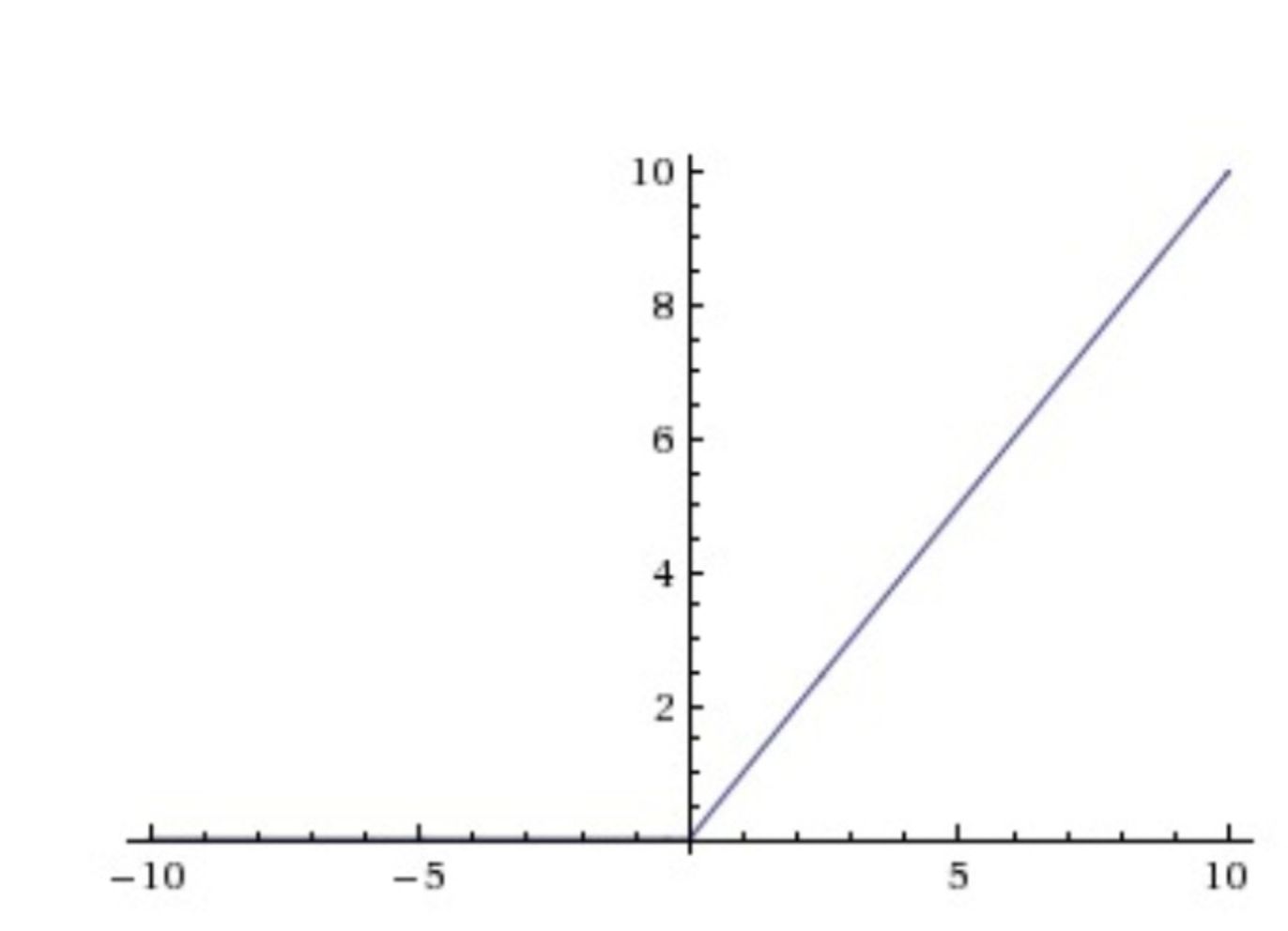
函数性质: 没有指数运算,计算速度快,收敛速度快。
- 无饱和区,解决梯度消失问题fan。
- 变相失活神经元,引入正则化,防止过拟合,相当于dropout。
Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生:(1)非常不幸的参数初始化,这种情况比较少见 (2)learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用He初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
(可引入leaky relu解决)
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!Leaky ReLU
函数形式:

函数图像: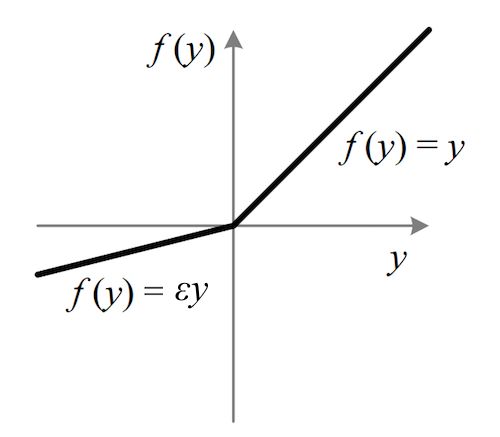
函数性质:为了解决Dead ReLU Problem,提出了将ReLU的前半段设为αx而非0,通常α=0.01。
- 理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
Maxout
函数形式:
函数图像:
函数性质:
- Maxout的拟合能力非常强,可以拟合任意的凸函数。Maxout具有ReLU的所有优点,线性、不饱和性。同时没有ReLU的一些缺点。如:神经元的死亡。
每个神经元中有两组(w,b)参数,那么参数量就增加了一倍,这就导致了整体参数的数量激增。
GELU
函数形式:

函数图像: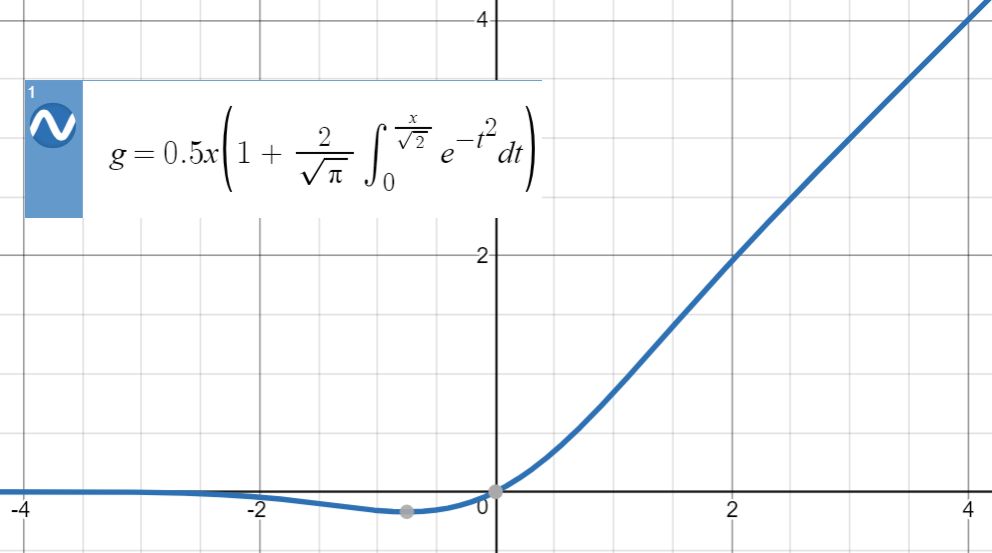
函数性质:神经元的输入x乘以其对应标准正态分布的分布函数。分布函数的参数为神经元的x本身,代表的意义是,X有多大概率是小于x的。
- GELU激活函数本身也有正则化的效果。即输入x越小,越容易被dropout。ReLU和Dropout都会返回一个神经元的输出,其中,ReLU会确定性的将输入乘上一个0或者1,Dropout则是随机乘上0。而GELU也是通过将输入乘上0或1来实现这个功能,但是输入是乘以0还是1,是在同时取决于输入自身分布的情况下随机选择的。换句话说,是0还是1取决于当前的输入有多大的概率大于其余的输入。
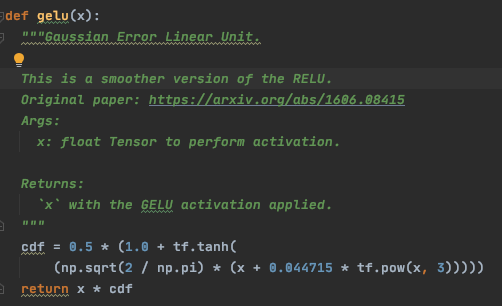
- 因为其没有精确的表达式,原论文给出了两种近似表达式,一种基于sigmoid函数,一种基于tanh函数:


损失函数
| 算法模型 | 损失函数 |
|---|---|
| 线性回归 | MSE loss |
| LR | log/CE loss |
| SVM | hinge loss |
| Adaboost | 指数损失函数 |
| 双/三塔模型 | margin/contrast/triple loss |
| 不平衡困难样本 | focal loss |
MSE loss

Log/CE Loss

交叉熵损失函数常用于逻辑回归分类模型。其实交叉熵损失函数可以由最大似然函数在伯努利分布的条件下推导出来,或者说最小化交叉熵函数的本质就是对数似然函数的最大化。具体推导可以见,LR模型中的细节。
ranking/margin/contrast/triple loss
其实这些loss本质都是相同的,只是名字不同而已。
- ranking loss:这个名字来自于信息检索领域,在这个应用中,我们期望训练一个模型对项目(items)进行特定的排序。比如文件检索中,对某个检索项目的排序等。Margin loss:这个名字来自于一个事实——我们介绍的这些loss都使用了边界去比较衡量样本之间的嵌入表征距离,见Fig 2.3
- Contrastive loss:我们介绍的loss都是在计算类别不同的两个(或者多个)数据点的特征嵌入表征。这个名字经常在成对样本的ranking loss中使用。但是我从没有在以三元组为基础的工作中使用这个术语去进行表达。
- Triplet loss:这个是在三元组采样被使用的时候,经常被使用的名字。
- Hinge loss:也被称之为max-margin objective。通常在分类任务中训练SVM的时候使用。他有着和SVM目标相似的表达式和目的:都是一直优化直到到达预定的边界为止。
不像其他损失函数,比如交叉熵损失和均方差损失函数,这些损失的设计目的就是学习如何去直接地预测标签,或者回归出一个值,又或者是在给定输入的情况下预测出一组值,这是在传统的分类任务和回归任务中常用的。ranking loss的目的是去预测输入样本之间的相对距离。这个任务经常也被称之为度量学习(metric learning)。
尽管我们并不需要关心这些表达的具体值是多少,只需要关心样本之间的距离是否足够接近或者足够远离,但是这种训练方法已经被证明是可以在不同的任务中都产生出足够强大的表征的。
针对不同输入可以暂将ranking loss分为两类:
- 使用一对的训练数据点(即是两个一组/pair wise),双塔
- 使用三元组的训练数据点(即是三个数据点一组/list wise),三塔
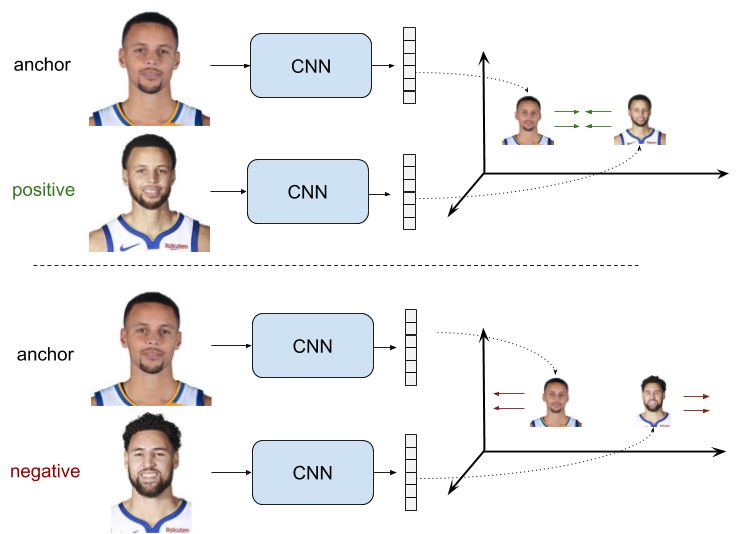
针对于双塔模型,我们的目标就是学习出一个特征表征,这个表征使得正样本对中的度量距离尽可能的小,而在负样本对中,这个距离应该要大于一个人为设定的超参数阈值 ,成对样本的ranking loss强制样本的表征在正样本对中拥有趋向于0的度量距离,而在负样本对中,这个距离则至少大于一个阈值。用
,成对样本的ranking loss强制样本的表征在正样本对中拥有趋向于0的度量距离,而在负样本对中,这个距离则至少大于一个阈值。用 分别表示这些样本的特征,则双塔模型的ranking loss如下:
分别表示这些样本的特征,则双塔模型的ranking loss如下:

假设用 分别表示样本对两个元素的表征,
分别表示样本对两个元素的表征, 是一个二值的数值,在输入的是负样本对时为0,正样本对时为1,距离
是一个二值的数值,在输入的是负样本对时为0,正样本对时为1,距离 是欧式距离,我们就能有最终的loss函数表达式:
是欧式距离,我们就能有最终的loss函数表达式:

可以很直观的看出该loss的性质:对于正样本,这个loss随着样本对输入到网络生成的表征之间的距离的减小而减少,增大而增大,直至变成0为止。对于负样本,这个loss只有在所有负样本对的元素之间的表征的距离都大于阈值 的时候才能变成0。
的时候才能变成0。
这里设置阈值的目的是,当某个负样本对中的表征足够好,体现在其距离足够远的时候,就没有必要在该负样本对中浪费时间去增大这个距离了,因此进一步的训练将会关注在其他更加难分别的样本对中。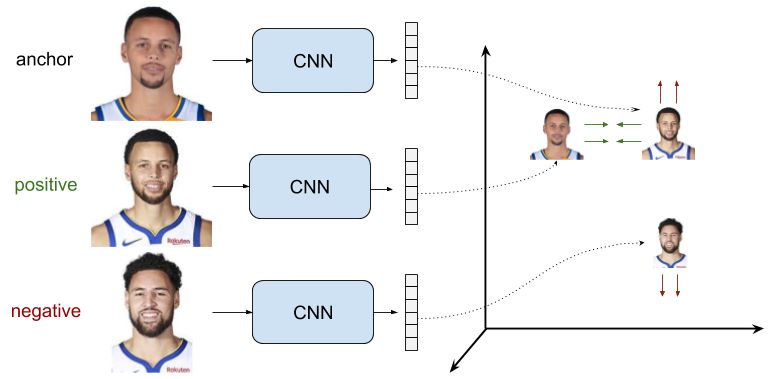
针对于三塔模型,三元组 中
中 代表锚点,
代表锚点, 代表正样本,
代表正样本, 代表负样本。其目标时让锚点和负样本之间的距离
代表负样本。其目标时让锚点和负样本之间的距离 与锚点和正样本之间的距离
与锚点和正样本之间的距离 之差大于一个阈值
之差大于一个阈值 ,由此目标可以构造出loss函数如下:
,由此目标可以构造出loss函数如下:


同样也很直观的看出triple loss的性质:
- 对于简单样本,
,此时,loss为0,网络参数将不更新,而去更新更困难的样本。
- 对于困难样本,
,及锚点与负样本的距离小于锚点与正样本的距离,此时,loss为比m大的正值,参数会继续更新。
Focal loss
主要用于解决样本不均衡和困难样本问题。以二分类任务为例,传统的交叉熵损失函数如下: ,其中
,其中
当样本不平衡时(负样本远多于正样本时),模型根据整体loss优化的方向并不是我们希望的。
所以最直观的对loss改进的方式即加一个权重控制参数(balanced CE),使样本较多的类别其loss所占权重低一些,如下:
其中 即为权重系数,我们可以通过控制它的值来控制正负样本对总loss的影响权重占比。这个系数最直观的计算方式就是根据正负样本数量的占比来确定。
即为权重系数,我们可以通过控制它的值来控制正负样本对总loss的影响权重占比。这个系数最直观的计算方式就是根据正负样本数量的占比来确定。
但balanced CE值解决了样本不平衡的问题,并没有解决易分类和难分类样本的问题。由此引出focal loss:
其中, 即为具体的权重计算方法,其中
即为具体的权重计算方法,其中 为调节系数。
为调节系数。
focal loss的两个重要性质:
- 当一个正样本样本预测为正样本的概率很小(难样本),即
 较小,则权重系数会接近于1,其原本的loss受影响较小。反之,易分类样本,权重系数会接近于0,其对整体的loss影响会弱化很多。
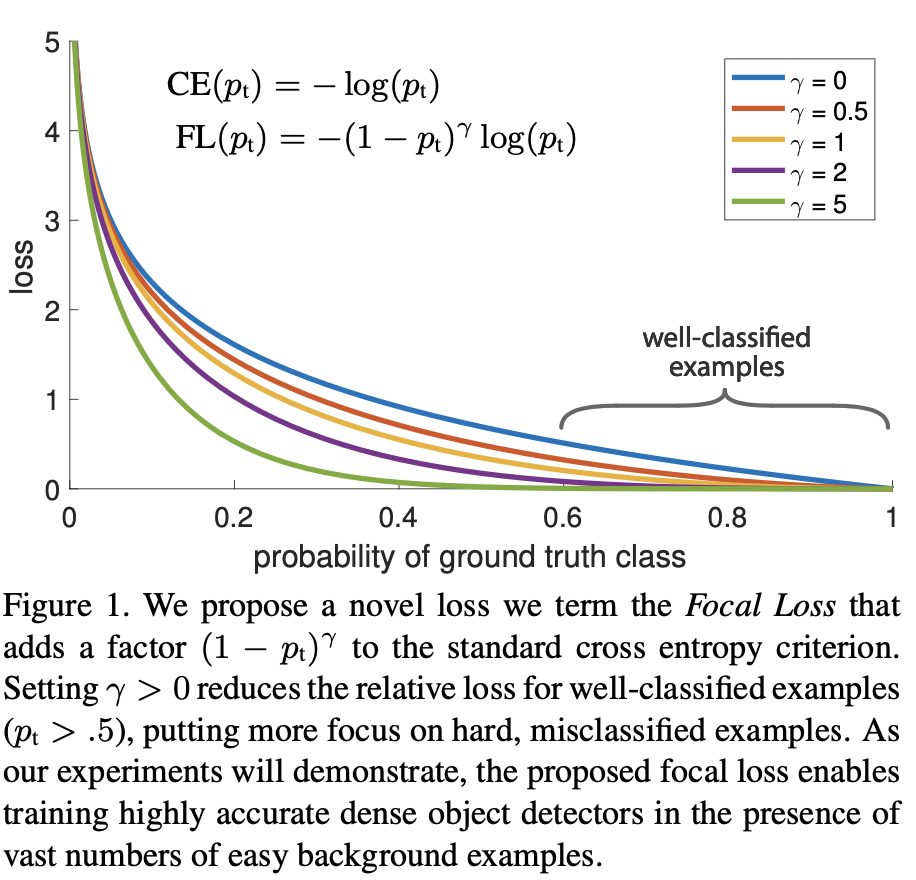
较小,则权重系数会接近于1,其原本的loss受影响较小。反之,易分类样本,权重系数会接近于0,其对整体的loss影响会弱化很多。 - 调节系数平滑的调节了易分类样本调低权重的比例。当调节系数为0时,loss即为原始的(balanced)CE;当其增加时,权重系数的缩放比例也会增加,原论文中的数据如下,原文实验中取2效果最好。
参考文献

若有收获,就点个赞吧
0 人点赞
