0. 新手小白常见的问题
- 在遇到待解决问题时,往往不是先做大量的计划和理清思路,而是直接大量找源码。
- 无脑极低效率的暴力调参,步入到
“找到一份开源代码” “跑了一下,调了调参“ ”效果不好,下一个” “效果好,拿去做集成” 的怪圈
然后以这种暴力搜索的方式解决问题久了之后,他开始对别人吹嘘:“害,俺们深度学习这一行,就是跑跑代码调调参,没有一点竞争力”。自嘲的话语被奉为圭臬可能是深度学习领域的最大悲剧。
- 极差的代码管理意识:是否使用Git是区分好的炼丹师和差劲的炼丹师的重要标准
- 极差的脚本管理意识:炼丹师很重要的技能,很大程度的决定了开发的效率和质量;底层的脚本要尽可能的做到通用、高效,组件化,并最好有充分测试(如unittest或者黑盒测试,无数次因为底层脚本清洗不充分导致上层模型出现badcase)
对于上述问题,你是否中招了?下面以三种方法来解决上述问题:
准:以最少的试错次数找出最优策略 快:以最快的速度解决一个算法问题 稳:以最不容易出错的方式管理实验
1. 准
最重要的一点是要避免蛮力试错,你要形成自己最高效的管理流程方法。
1.1 找准起点-做好调研
接手一个算法问题后,如果时间很充裕,就可以先定位一下该算法问题所对口的学术会议或期刊,根据文章title,找几篇跟你的算法问题最接近的近两年的paper,慢慢调研。
通过这些paper的related work章节和实验章节,还很容易追溯出更早的工作,所以一般没有必要去手动调研更早期的paper。
如果时间不充裕,那么就要考察你的检索能力了。
非常不建议直接去github一个repo一个repo的蛮力调参,大量的宝藏方法是很难通过通用搜索引擎来找到的(虽然这种行为在比赛刷榜的时候随处可见)。
1.2 找准努力方向-构建系统迭代闭环策略
常用迭代闭环策略:
数据集分析 - 预处理策略 - 算法策略 - 模型评价 - case study
由于不同的问题有不同的限定,因此不存在一个绝对的流程可以恰好适合所有算法问题。 没有经验的小白会陷入第三四步的死循环,没有看到前两部和最后一步的重要性。
- 数据集分析。很重要,可以根据初步分析,剞劂很多不必要的调参,并对结果有更好的解释性。
- 预处理策略与算法策略。
- 模型评价。模型评价的问题在打比赛时一般不会遭遇,在比较成熟的算法任务中一般也被解决了。比如谈到文本分类,就能想到acc、f1等指标;谈到机器翻译,就能想到bleu等。然而有很多算法问题是很难找到一个无偏且自动的评价指标的。
- 案例研究。在经验不足的情况下,通过case study可以帮助你排除大量的不必要尝试,并有助于发现当前策略的瓶颈,针对性的寻找策略和创新。
1.3 找准翻车原因-重视bug
有时候调参和使用一些算法策略可以缓解bug带来的影响,导致小白误以为继续卖力的调参和疯狂试错就一定能把这个鸿沟填平。实际上,比起算法和超参,bug往往致命的多。
当然了,对于一些特殊的算法问题(比如众所周知的RL问题),超参数确实极其敏感,需要具体问题具体分析。
2. 快
2.1 摆脱洁癖,提高撸码速度
算法探索具有极强的不确定性,很可能你写了半天的代码最后由于不work而完全废弃,因此,从代码风格上来说,一定要避免把代码写成系统,各种面向对象的封装技巧一顿乱怼是非常不必要的。允许一些“垃圾代码”的存在可以大大提高实验迭代的效率。
底层脚本当然不能太随意,本文的“快”章节仅针对策略探索的场景,这种场景下基本不需要团队协作,代码也基本上是一次性用品。如果要把策略和工具沉淀下来给团队其他人用,是必须要重构一下的。
2.2 分规模验证,快速完成实验
- 调通代码。这时候象征性的挂几百条样本就够了,修正语法错误和严重的逻辑错误。调试过程中一定要学会画出学习曲线(横轴为训练集大小)和收敛情况(横轴为迭代次数),二者的纵轴均是验证集误差。根据学习曲线来实时的确定模型的高偏/方差相关问题,以及是否需要更多的数据(还是目前数据量足矣,无需耗费精力和时间增加数据集并花费大量时间来处理和训练海量数据)等,这一点是非常重要的,它可以让你节省大量的时间和精力。
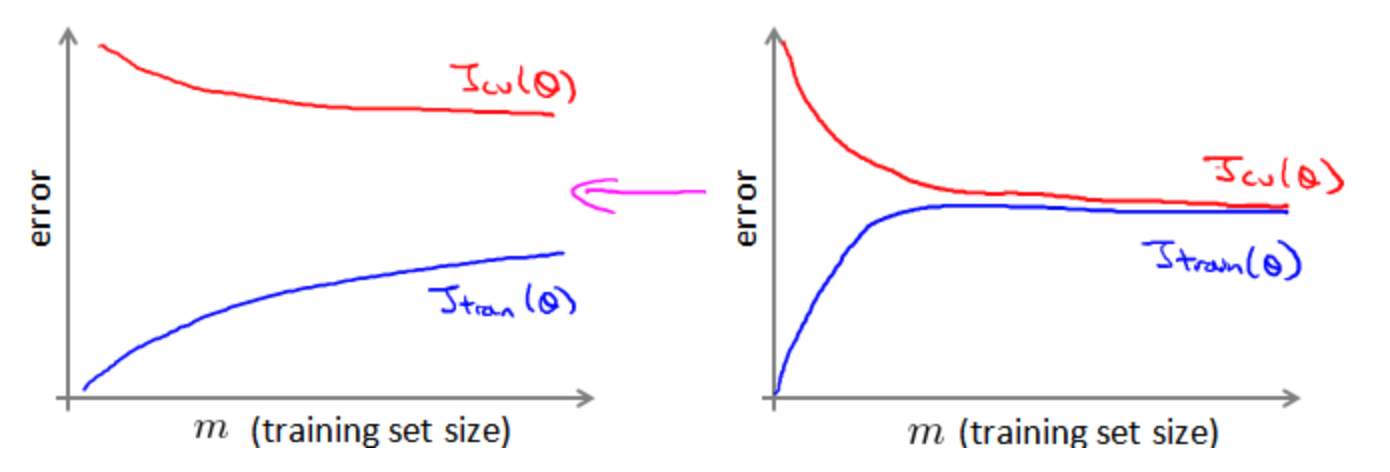
- 验证收敛性。很多bug不会报错,但会导致训练完全崩溃或者压根就没在训练。可以对几百条或者几千条样本进行训练,看看若干epoch之后训练loss是否能降低到接近0。
- 小规模实验。在万级或十万级别的小样本集上验证模型表现,分析超参数敏感性。这一阶段在数据规模不大时(比如几十万或一二百万)其实可有可无,当训练数据极其庞大时(十亿级甚至百亿级的话)还是必要的。有一些很细微的bug虽然不会影响收敛,却会显着影响最终模型的表现。此外也有助于发现一些离谱的超参数设置。
- 大规模实验。即,有多少训练数据,就上多少,甚至多训练几个epoch。进行到第四阶段时,应当绝对保证代码是高度靠谱的,基本无需调参的,否则试错代价往往难以承受。
2.3 理性调参,把算力和时间留给策略探索
调参的第一步,也是最重要的一步是进行超参数敏感性分析,找到对当前任务性能影响最大的几个超参数之后再进行精调。而要确定各个超参数的敏感性,一方面可以根据自身经验来定,一方面可以根据各paper中的取值(差异大的超参数可能是敏感超参,大家都取值相同的一般不敏感),实在不确定,跑两三组实验就够确定敏感性了,完全没有必要来个“网格搜索”。3. 稳
小白尝尝出现下面这些手忙脚乱的状况:- 诶?明明我记得这个脚本能跑出来95%的准确率,再一跑怎么成92%了?
- 我的模型去哪了?
- 这个模型怎么训出来的来着?
- 这俩策略有哪些diff来着?
3.1 实验管理和代码版本管理
采用Git来进行代码版本管理:
- 首先,务必保证训练日志、eval日志是以文件的形式存了下来,而不是打印到屏幕上变成过眼云烟了;此外,需要保证每一次运行时的settings(比如超参数、数据集版本、ckpt存储路径等)都能保存到日志文件中,且尽量封装一个run.sh来维护训练任务的启动环境。
- 之后就是看每个人自己的习惯,比如:主线策略每成功推进一步,就调用
git tag打个tag。这里的tag即策略名,与实验管理的表格中的策略名对齐;如果要在某个策略的基础上尝试一个很不靠谱的探索,那么可以在当前策略的基础上拉一个分支出来,在这个分支上完成相应事情后切回主分支。当然啦,万一这个分支上的策略work了,就可以考虑将其转正,合入主分支并打上相关tag。- 这样将来你想review某个策略时,只需要切换到相应的tag下面或者分支下面就可以啦,完整复现整个环境,并能直接追溯出跑该策略时的一切相关设置,以及该策略下的各种调参结果。
- 最后,“稳”字问题上还要考虑最后一种极端情况,就是整个实验环境被连根拔起╮( ̄▽ ̄””)╭比如硬盘损坏之类的严重故障。因此一定要记得做好备份工作,即周期性的将环境中的关键代码push到github等远程仓库。当然了,对于ckpt、数据集这种大型文件,可以写入
.gitignore文件中以免把仓库撑爆,这些大型文件的最佳归宿当然就是hadoop集群啦。
具体关于git的细节可以参考我的另一篇博文。
参考文献

若有收获,就点个赞吧
0 人点赞
