目的:复杂模型比较笨重,线上推理响应速度慢,机器资源有限时,流量大可能撑不住。
知识蒸馏就用来解决这类问题。
做法:将复杂模型作为老师,简单模型作为学生,将老师模型学到的结果辅助学生进一步进行学习。Teacher学习能力强,可以将它学到的暗知识(Dark Knowledge)迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正上战场挡抢撑流量的是灵活轻巧的Student小模型。比如Bert,因为太重,很难直接上线跑,目前很多公司都是采取知识蒸馏的方法,学会一个轻巧,但是因为被Teacher教导过,所以效果也很好的Student模型部署上线。
方法:
1. logits蒸馏 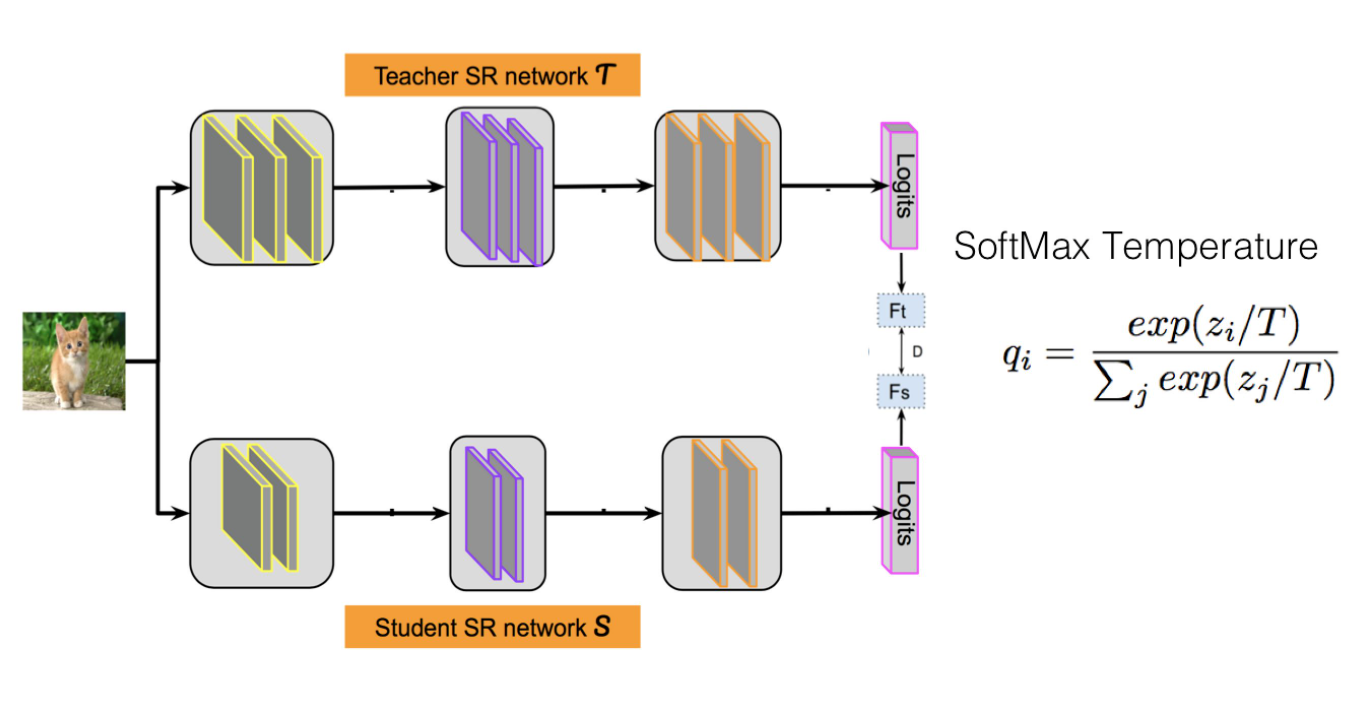
让Student的Logits去拟合Teacher的Logits,与原始交叉熵损失函数融合在一起,即Student的损失函数为: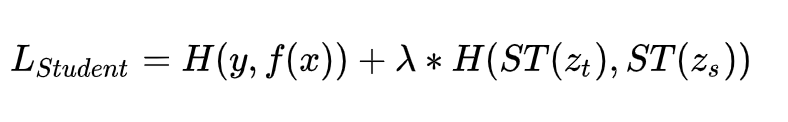

一般而言,温度T要设置成大于1的数值,这样会减小不同类别归属概率的两极分化程度,因为Logits方法中,Teacher能够提供给Student的额外信息就包含在Logits数值里。如果我们在蒸馏损失部分,将T设置成1,采用常规的Softmax,也就是说两极分化严重时,那么相对标准的训练数据,也就是交叉熵损失,两者等同,Student从蒸馏损失中就学不到任何额外的信息。
- 特征蒸馏
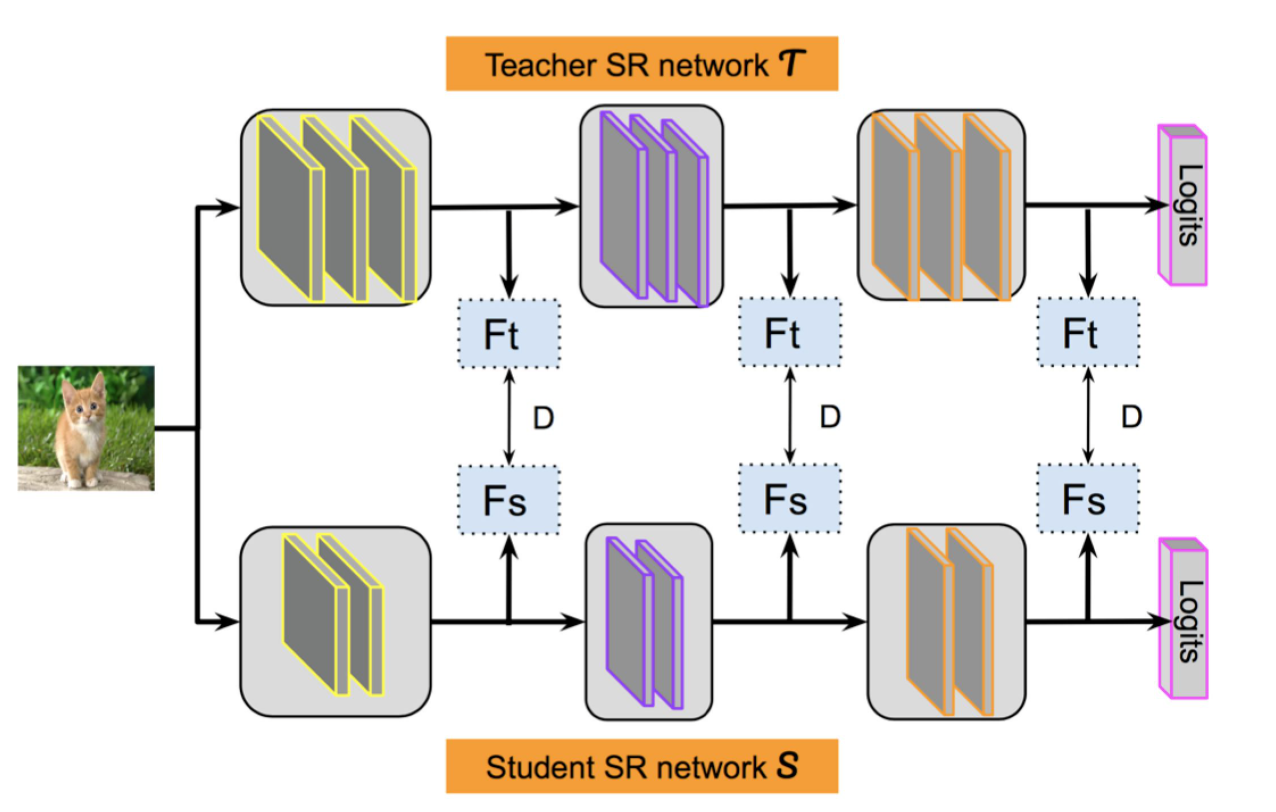
它不像Logits方法那样,Student只学习Teacher的Logits这种结果知识,而是学习Teacher网络结构中的中间层特征。
它强迫Student某些中间层的网络响应,要去逼近Teacher对应的中间层的网络响应。这种情况下,Teacher中间特征层的响应,就是传递给Student的暗知识。在此之后,出了各种新方法,但是大致思路还是这个思路,本质是Teacher将特征级知识迁移给Student。
以上两种方式的结合,即为两阶段(two-stage)蒸馏。

若有收获,就点个赞吧
0 人点赞
