1. 整体俯瞰Norm
按照我一贯以来学习新事物和书写博文的方式,咱们先从大方向整体把握一下Norm这个对于NN(神经网络)及其重要东西。
1.1 为什么需要Norm
它能加快神经网络收敛速度,不再依赖精细的参数初始化过程,可以使用较大的学习率等很多好处。
深度学习中的Internal Covariate Shift (ICS)问题及其影响。啥是 Internal Covariate Shift?谷歌直译一下的意思为“内部协变量移位”,下面给出大神的具体意译意思:
大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift 就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有x,
大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
ICS会导致什么问题?
机器学习领域有个很重要的假设:IID(independent and identically distributed)独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。而ICS问题就是NN中每个神经元的输入数据不再是“独立同分布”,这当然会导致一系列的问题:
- 下一层的参数需要不断适应来自于上一层新的输入数据分布,降低学习速度。
- 上层输入的变化可能趋向于变大或者变小,导致下层落入饱和区,使得学习过早停止。
- 每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
所以我们就需要Norm方法在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
1.2 瞧一瞧家谱
学习新东西的一大禁忌就是直接扎入无穷无尽的细节,所以咱们先俯瞰一下深度学习中Norm这个家族的家谱:
- BN(Batch Normaliazation)2015
- LN(Layer Normaliazation)2016,WN(Weight Normaliazation)2016,IN(Instance Normaliazation)2016
- CN(Cosine Normaliazation)2017
- GN(Graph Normaliazation)2018
别急,咱们在第二章会详细介绍里面的各种Norm方法,现在把控了Norm家谱的整体方向,你就已经超过50%的浑水摸鱼的算法工程师了。
1.3 Norm基本思想和通用框架
其实,万变不离其中,各种Norm算法的框架都是通用的,理解了它的通用框架,所有Norm算法基本就不在话下了,这就是所谓的四两拨千斤,四两是核心通用思想和框架,千斤就是各种Norm算法细节。废话不多说了,直接开整。
以NN中的一个普通神经元为例,神经元接受一组输入(向量) ,通过某种运算,输出一个值(标量)
,通过某种运算,输出一个值(标量) 。一般值经过线性变换后,再进行激活函数的激活:
。一般值经过线性变换后,再进行激活函数的激活: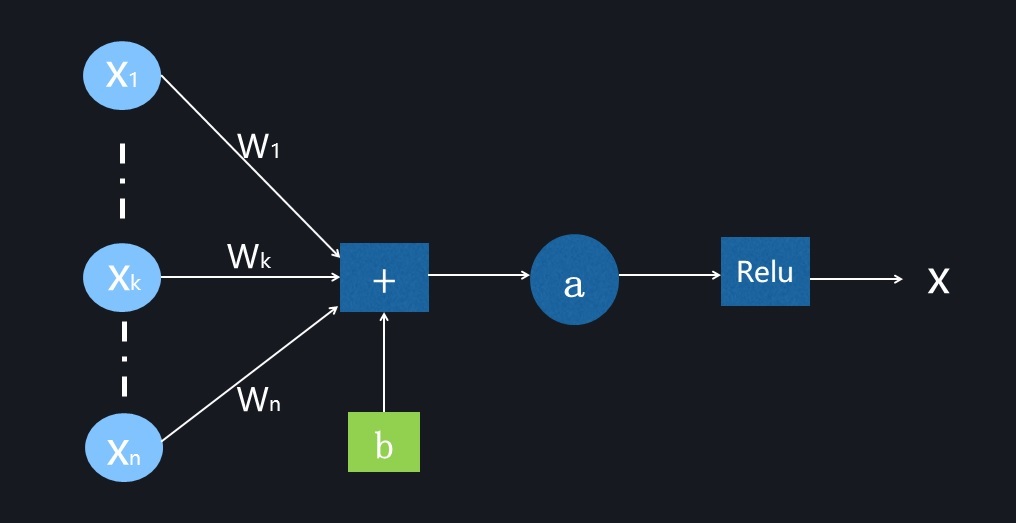
而Norm的思想就是在将 送给下一层的神经元之前,先对其做平移和伸缩变换, 将
送给下一层的神经元之前,先对其做平移和伸缩变换, 将 的分布规范化成在固定区间范围的标准分布。当然有不同的位置可以选取,第一种是原始BN论文提出的,放在激活函数之前;另外一种是后续研究提出的,放在激活函数之后,不少研究表明将BN放在激活函数之后效果更好。
的分布规范化成在固定区间范围的标准分布。当然有不同的位置可以选取,第一种是原始BN论文提出的,放在激活函数之前;另外一种是后续研究提出的,放在激活函数之后,不少研究表明将BN放在激活函数之后效果更好。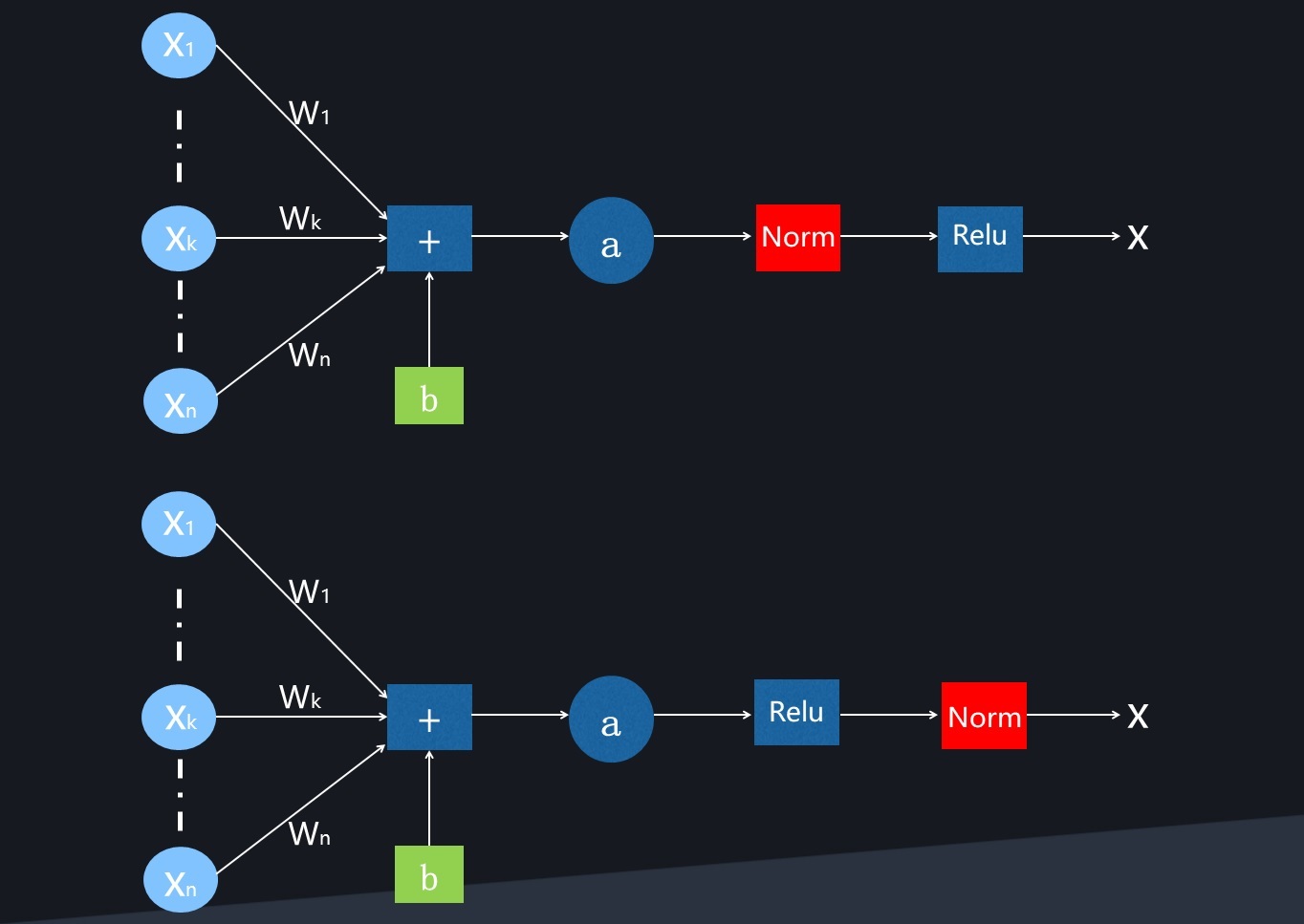
Norm的通用框架如下: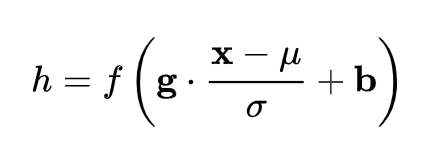
是平移参数(shift parameter),
是缩放参数(scale parameter)。通过这两个参数进行 shift 和 scale 变换:
,得到的数据符合均值为 0、方差为 1 的标准分布。
是再平移参数(re-shift parameter),
是再缩放参数(re-scale parameter)。将上一步得到的进一步变换为:
,最终得到的数据符合均值为
,方差为
的分布。
这时候就有点难受了,说好的处理 ICS,第一步都已经得到了标准分布处理好了,第二步却又给变走了,其实这么做是有原因的:
通过第一步的Norm后,就相当于把非线性函数又替换成线性函数了,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以Norm为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者由移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。
经过这么的变回来再变过去,会不会跟没变一样?
当然不会,不然干嘛要折腾这么一大圈。主要是为啥不会,因为再变换引入的两个新参数 g 和 b,可以表示旧参数作为输入的同一族函数,但是新参数有不同的学习动态。在旧参数中,x的均值取决于下层神经网络的复杂关联;但在新参数中,
仅由
来确定,去除了与下层计算的密切耦合。新参数很容易通过梯度下降来学习,简化了神经网络的训练。
这样的 Normalization 离标准的白化还有多远?
标准白化操作的目的是“独立同分布”。独立就不说了,暂不考虑。变换为均值为
、方差为
的分布,也并不是严格的同分布,只是映射到了一个确定的区间范围而已(这里可以进行继续深入研究)。
2. 深入细聊Norm
介绍完Norm的基本思想后和通用框架后,各种Norm算法其实也都是大同小异水到渠成了,可别看咱随意这么一说出口,如果让咱自己研究说不定一个都想不出来,所以算法工程师还是要多动脑动手,更重要的是借鉴前人的发展路径,站在巨人的肩膀上。
2.1 BN (Batch Normalization)
Google于2015年提出的BN是Norm家族的鼻祖,可见其重要的程度。其规范化针对单个神经元进行,利用网络训练时一个 mini-batch 的数据来计算该神经元 的均值和方差,因而称为 Batch Normalization。
的均值和方差,因而称为 Batch Normalization。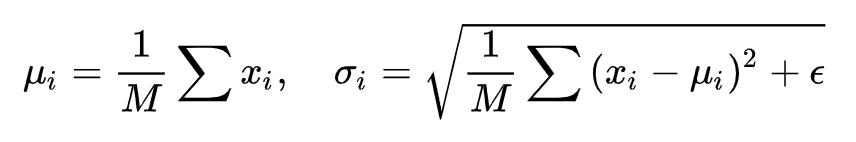
其中的 就是mini-batch 的size(即一个batch中的数据量),相对于一层神经元的水平排列,BN 可以看做一种纵向的规范化,如下图所示。
就是mini-batch 的size(即一个batch中的数据量),相对于一层神经元的水平排列,BN 可以看做一种纵向的规范化,如下图所示。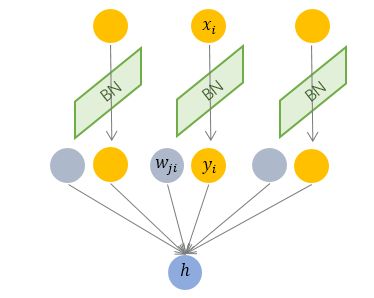
BN的缺点:
- BN 独立地规范化每一个输入维度
,但规范化的参数是一个 mini-batch 的一阶统计量和二阶统计量。这就要求 每一个 mini-batch 的统计量是整体统计量的近似估计,或者说每一个 mini-batch 彼此之间,以及和整体数据,都应该是近似同分布的。分布差距较小的 mini-batch 可以看做是为规范化操作和模型训练引入了噪声,可以增加模型的鲁棒性;但如果每个 mini-batch的原始分布差别很大,那么不同 mini-batch 的数据将会进行不一样的数据变换,这就增加了模型训练的难度。因此,BN 比较适用的场景是:每个 mini-batch 比较大,数据分布比较接近。在进行训练之前,要做好充分的 shuffle. 否则效果会差很多。
- 由于 BN 需要在运行过程中统计每个 mini-batch 的一阶统计量和二阶统计量,因此不适用于动态的网络结构和 RNN 网络。不过,也有研究者专门提出了适用于 RNN 的 BN 使用方法,这里先不展开了。
- BN要求计算统计量的时候必须在同一个Mini-Batch内的实例之间进行统计,因此形成了Batch内实例之间的相互依赖和影响的关系。如何从根本上解决这些问题?一个自然的想法是:把对Batch的依赖去掉,转换统计集合范围。在统计均值方差的时候,不依赖Batch内数据,只用当前处理的单个训练数据来获得均值方差的统计量,这样因为不再依赖Batch内其它训练数据,那么就不存在因为Batch约束导致的问题。在BN后的几乎所有改进模型都是在这个指导思想下进行的。
2.2 LN (Layer Normalization)
层规范化就是针对 BN 的上述不足而提出的。与 BN 不同,LN 是一种横向的规范化,如下图所示。它综合考虑一层所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入。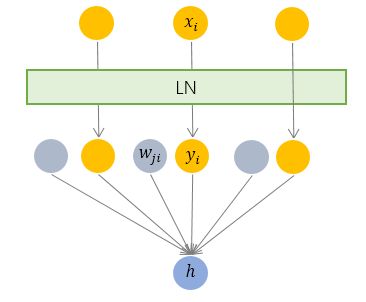
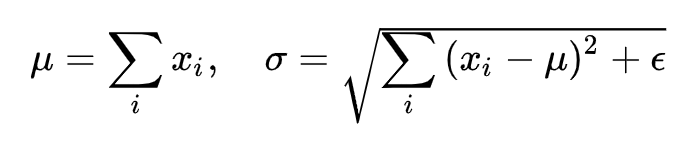
其中 枚举了该层所有的输入神经元。对应到标准公式中,四大参数
枚举了该层所有的输入神经元。对应到标准公式中,四大参数 均为标量(BN中是向量),所有输入共享一个规范化变换。
均为标量(BN中是向量),所有输入共享一个规范化变换。
LN的优缺点:
- LN 针对单个训练样本进行,不依赖于其他数据,因此可以避免 BN 中受 mini-batch 数据分布影响的问题,可以用于 小mini-batch场景、动态网络场景和 RNN,特别是自然语言处理领域。此外,LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间。
- BN 的转换是针对单个神经元可训练的——不同神经元的输入经过再平移和再缩放后分布在不同的区间,而 LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
2.3 WN (Weight Normalization)
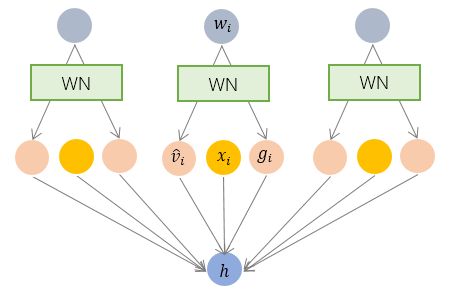
BN和LN都是对输入的特征数据 进行规范化,而WN则将规范化应用于线性变换函数的权重
进行规范化,而WN则将规范化应用于线性变换函数的权重 。具体而言,WN 提出的方案是,将权重向量
。具体而言,WN 提出的方案是,将权重向量 分解为向量方向
分解为向量方向 和向量模
和向量模 两部分:
两部分: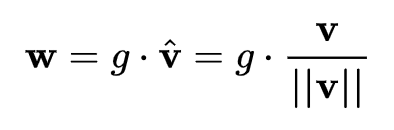

2.4 CN (Cosine Normalization)
3. Normalization为什么有效?
3.1 权重伸缩不变性
数据伸缩不变性(data scale invariance)指的是,当权重 按照常量
按照常量 进行伸缩时,得到的规范化后的值保持不变,即:
进行伸缩时,得到的规范化后的值保持不变,即: ,其中
,其中 ,上述规范化方法均有这一性质,这是因为,当权重
,上述规范化方法均有这一性质,这是因为,当权重 伸缩时,对应的均值和标准差均等比例伸缩,分子分母相抵:
伸缩时,对应的均值和标准差均等比例伸缩,分子分母相抵: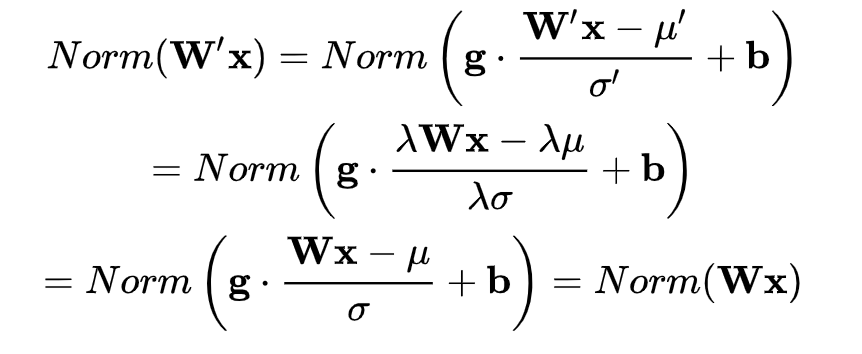
权重伸缩不变性可以有效地提高反向传播的效率,由于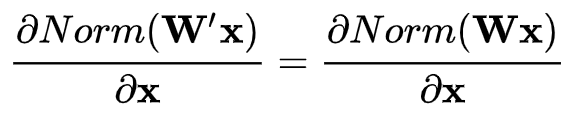 ,因此,权重的伸缩变化不会影响反向梯度的 Jacobian 矩阵,因此也就对反向传播没有影响,避免了反向传播时因为权重过大或过小导致的梯度消失或梯度爆炸问题,从而加速了神经网络的训练。
,因此,权重的伸缩变化不会影响反向梯度的 Jacobian 矩阵,因此也就对反向传播没有影响,避免了反向传播时因为权重过大或过小导致的梯度消失或梯度爆炸问题,从而加速了神经网络的训练。
3.2 数据伸缩不变性
与权重伸缩同理,数据伸缩不变性(data scale invariance)指的是,当数据 [公式] 按照常量 [公式] 进行伸缩时,得到的规范化后的值保持不变,即: ,其中
,其中 。数据伸缩不变性仅对 BN、LN 和 CN 成立。因为这三者对输入数据进行规范化,因此当数据进行常量伸缩时,其均值和方差都会相应变化,分子分母互相抵消,而 WN 不具有这一性质。数据伸缩不变性可以有效地减少梯度弥散,简化对学习率的选择。
。数据伸缩不变性仅对 BN、LN 和 CN 成立。因为这三者对输入数据进行规范化,因此当数据进行常量伸缩时,其均值和方差都会相应变化,分子分母互相抵消,而 WN 不具有这一性质。数据伸缩不变性可以有效地减少梯度弥散,简化对学习率的选择。
4. 思维发散
4.1 为什么NLP中利用LN效果要比BN好(transformer/bert都用的是LN),而图像领域普遍用到的是BN?
首先需要说明的是,NLP中的LN和BN效果好都是实验出来的,具体内部严谨的原因推理目前还没有明确的解释,但从直观上可以多角度尝试解释一下。
首先要了解BN和LN的特点,BN是针对一个batch内多个样本的某个特征进行缩放归一化至相同分布,LN是针对单个样本的全部特征进行缩放归一化至相同分布。一个是纵向,一个是横向,他们采用的是不同维度的一阶(均值)和二阶统计量(方差)来进行特征的缩放。
再来看一下NLP和图像数据的不同特点。
BN要求数据的输入长度一致,但RNN输入是不定长的,但也可以通过padding、加载数据时把长度接近的文本放在同一个batch等常见trick方法解决,所以这并不是主要原因。 NLP的数据是一个个句子,复杂性较高,且词序并不影响理解,所以固定位置的词所表示含义可能完全不同,所以BN这种对不同句子的同一位置的词维度进行缩放,并不符合NLP的规律,因为同一位置的词并不代表同一或相似特征,因为LN是针对一句话进行缩放,此时各个词都已经映射到了同一隐向量空间,更符合NLP规律。 而且不同句子长度不同,padding的位置其实是无意义的,其参与BN统计缩放也会引入误差。而LN则不会出现这种问题。 其实主要还是看那一个维度的差异性更大,如果不同样本的同一位置差异性更大,则采用LN,若同一样本内部不同位置差异性更大则采用BN。
- 此外根据不同的论文也会有不同的启发
《PowerNorm: Rethinking Batch Normalization in Transformers》2020论文中提到的BN效果不好的原因,主要还是NLP数据与CV数据特性的差别对训练过程产生了影响,使得训练中batch的统计量不稳定。
BN在训练和预测阶段的不同
- 训练阶段利用的是当前batch中的均值和方差和历史模型的记录做移动平均。
- 预测阶段为了提升速度,直接利用模型训练好的一阶二阶统计量计算,是固定的。
- 之所以训练阶段不用全量的均值和方差,在训练过程中是没办法统计到全量训练集的统计量的,只能利用移动平均近似,即每个batch都将统计量微调一点的办法。
参考文献
- 详解深度学习中的Normalization,BN/LN/WN
- Batch Normalization导读
- 深度学习中的Normalization模型
- An Overview of Normalization Methods in Deep Learning
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Layer Normalization
- Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
- Cosine Normalization: Using Cosine Similarity Instead of Dot Product in Neural Networks

若有收获,就点个赞吧
0 人点赞
