DropOut
DropOut实现的两种方式
训练时神经元以概率p丢弃,测试时对每个神经元的权重要预先乘以1-p,以恢复在训练中该神经元有p的概率被丢弃。(即对每个单元的参数预先乘以概率p(训练的时候预设的不丢弃的概率),使得训练和预测的输出期望保持一致。)
在代码上有两种做法,一种是在训练的时候对输出除以1-p,另外一种则是在预测的时候对输出乘以1-p。
对应paddle中的两种实现选择如下: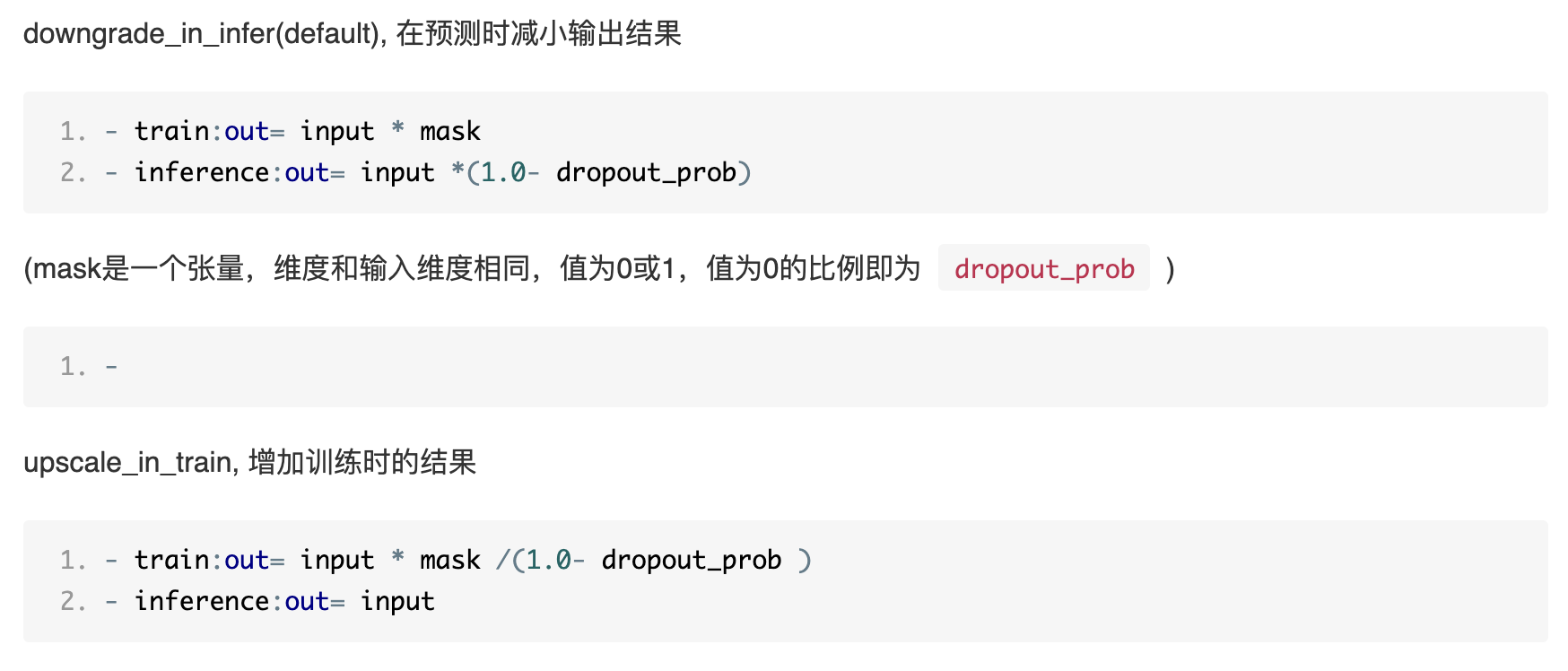
import numpy as npp = 0.5 # 神经元激活概率def train_step(X):""" X contains the data """# 三层神经网络前向传播为例H1 = np.maximum(0, np.dot(W1, X) + b1)U1 = np.random.rand(*H1.shape) < p # first dropout maskH1 *= U1 # drop!H2 = np.maximum(0, np.dot(W2, H1) + b2)U2 = np.random.rand(*H2.shape) < p # second dropout maskH2 *= U2 # drop!out = np.dot(W3, H2) + b3def predict(X):# ensembled forward passH1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activationsH2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activationsout = np.dot(W3, H2) + b3
p = 0.5 # probability of keeping a unit active. higher = less dropout
def train_step(X):
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass: compute gradients... (not shown)
# perform parameter update... (not shown)
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3
因为第2种方法,更便捷,无需频繁在训练和测试时改动网络,所以一般采取第二种方式实现dropout。
DropOut解决过拟合原理
取平均的作用 。相当于训练了不同的神经网络,引入随机性,来进行综合决策。类似于bagging的思想。
由于每个epoch前向的时候都是以一定概率随机的丢弃某些神经元,所以每个epoch训练的时候其实是在训练不同的网络,类似bagging。
R-Dropout
灵感来自于2021年7月份最新的论文《R-Drop: Regularized Dropout for Neural Networks》
具体思路(What)
思路很简单,但效果很好,“大道至简”。
通过“Dropout两次”的方式来得到同一个输入的不同特征向量,并将它们视为正样本对。
结合两次样本的各自交叉熵loss和之间的KL散度loss作为新的loss
个人理解,为什么效果很好(Why)
R-Dropout可以看成是Dropout的改进。
原始的Dropout的理想步骤应该是:
对同一个输入多次传入模型中(模型不关闭Dropout),然后把多次的预测结果平均值作为最终的预测结果。
但我们一般情况下的预测方式为方便实现是直接关闭Dropout进行确定性的预测。
我们训练的是不同Dropout的融合模型,预测的时候用的是关闭Dropout的单模型,两者未必等价,这就是Dropout的训练预测不一致问题。
它通过增加一个正则项,来强化模型对Dropout的鲁棒性,使得不同的Dropout下模型的输出基本一致,因此能降低这种不一致性,促进“模型平均”与“权重平均”的相似性,从而使得简单关闭Dropout的效果等价于多Dropout模型融合的结果,提升模型最终性能。
具体实现(How)
主要改动为两部分,一部分为数据的重新构造生成,另一部分为新的loss实现
class data_generator(DataGenerator):
"""数据生成器
"""
def __iter__(self, random=False):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for is_end, (text, label) in self.sample(random):
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
# batch_token_ids.append(token_ids)
# batch_segment_ids.append(segment_ids)
# batch_labels.append([label])
for i in range(2):
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append([label])
# if len(batch_token_ids) == self.batch_size or is_end:
if len(batch_token_ids) == self.batch_size * 2 or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
from keras.losses import kullback_leibler_divergence as kld
def categorical_crossentropy_with_rdrop(y_true, y_pred):
"""配合上述生成器的R-Drop Loss
其实loss_kl的除以4,是为了在数量上对齐公式描述结果。
"""
loss_ce = K.categorical_crossentropy(y_true, y_pred) # 原来的loss
loss_kl = kld(y_pred[::2], y_pred[1::2]) + kld(y_pred[1::2], y_pred[::2])
return K.mean(loss_ce) + K.mean(loss_kl) / 4 * alpha
参考文献
又是Dropout两次!这次它做到了有监督任务的SOTA R-Drop: Regularized Dropout for Neural Networks https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/fluid/layers/dropout_cn.html

若有收获,就点个赞吧
0 人点赞
