索引
- 每个表至少都有一个主键索引,表中所有的数据行都是存放在主键索引这个 B+ 树的叶子节点上
- 如果你给表的其他字段加了索引的话,这个索引就是二级索引了,二级索引也是 B+ 树。
- 二级索引和主键索引的不同之处在于其叶子节点上保存的值不一样,表中所有字段的值都被完整的保存在主键索引的叶子节点上,但是二级索引的叶子节点只保存对应主键的值。
示例:
我们举一个具体的例子来还原下这个问题。首先提供一个表,表中有三个字段 (id,k,m),分别给主键 id 和字段 k 建立主键索引和二级索引。
mysql> create table t( id int primary key, k int not null, m int(11), index (k))engine=InnoDB;
然后再给表中插入几条数据,用R1、R2、R3、R4、R5表示,插入的具体数据如下:R1~R5 的 (id,k,m) 值分别为 (100,1,1000)、(200,2,2000)、(300,3,3000)、(500,5,5000)、(600,6,6000)。
刚刚有说过,主键索引叶子节点上保存完整的整行记录值,二级索引叶子节点保存主键的值,所以上面这个表 t 的数据在 mysql 底层的存储就如下示意图。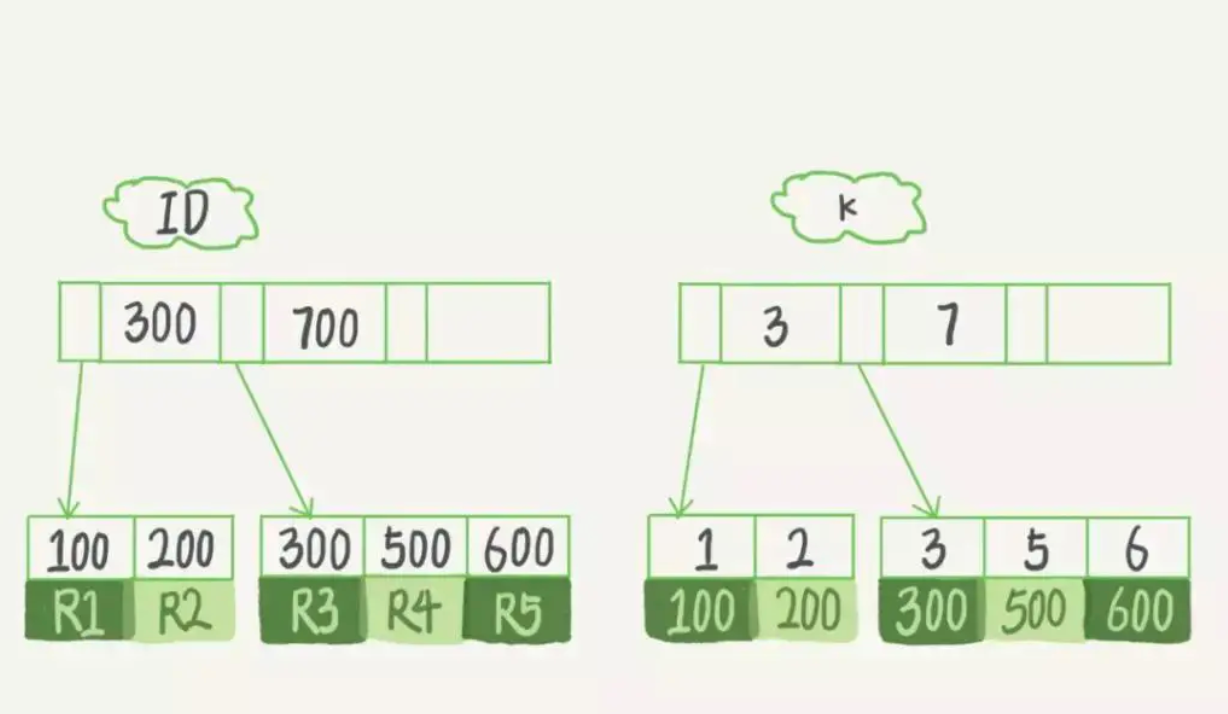
表 t 一共有 3 个字段,字段 m 上没有索引,也就是说表 t 上有两个索引,所以对应有 2 个 B+ 树,一个表上有多少个索引,其实就会有多少个 B+ 树。
select * from t where m > 1000 and m < 3000;
比如下面这条 sql 语句,显然没有可用的索引,所以只能走全表扫描了,即把主键索引上的叶子节点从头到尾都扫描一遍,然后每扫描到一行把字段 m 的值拿出来再比对一下,筛选出满足条件的记录,这个查询是非常低效的。
select * from t where k > 3 and k < 6;
再来看另一条 sql 语句,这个语句可以使用索引 k,所以该查询会先到二级索引 k 这个 B+ 树上,快速找到满足要求的叶子节点,而这里的叶子节点上只保存了主键的值,所以还需要通过获得的主键 ID 值再回到主键索引上查出所有字段的值,这个过程称作回表。
这就是为什么加了索引后,mysql 查询会变快的原因了,其实刚提到的这个回表过程还可以再优化的,就是利用覆盖索引。
常用sql复杂操作
窗口函数
参考文献

若有收获,就点个赞吧
0 人点赞
