SELECT<列名>,...FROM <表名>;
SELECT *可以取出表中所有的列,列的顺序在创建表时决定。*表示全部列。仅含有 SELECT 的语句,可以创造一行临时数据。有些数据库可能不支持仅 SELECT 的操作。
AS
AS关键字可以重命名选出的列:SELECT <列名> AS <新列名>- 新列名可以使用中文,但需要以双引号括起来。
SELECT <列名> AS "<中文列名>"
- 新列名可以使用中文,但需要以双引号括起来。
查询时新增常数列:
SELECT [数字/字符串] AS <常数列名>DISTINCT
DISTINCT对查询结果去重:- 对某一列去重:
SELECT DISTINCT <列名>- 列中所有的 NULL 值仅保留一条。
- 对多列去重:
SELECT DISTINCT <列名_1>, <列名_2>, ...DISTINCT关键字只能放在所有列名的前面。
- 对某一列去重:
筛选查询
SELECT <列名>, ...
FROM <表名>
WHERE <条件表达式>;
- 使用
WHERE子句筛选出符合查询条件的数据。 HAVING子句也可以筛选数据,具体见后文。
操作符
- 四则运算
- 加法
+ - 减法
- - 乘法
* - 除法
/
- 加法
- 比较运算
- 等于
= - 不等于
<> - 大于
> - 大于等于
>= - 小于
< - 小于等于
<= - 字符串类型的大小比较按字典顺序排列:1、10、11、2、222、3
- 等于
- 逻辑运算(三值逻辑)
- 与
AND - 或
OR- AND 优先 OR 执行,需要使用括号来明确运算顺序。
- 非
NOT- 方便地否定某一条件,但不要滥用。
- 与
AND 真值表
| P | Q | P & Q |
|---|---|---|
| 真 | 真 | 真 |
| 真 | 假 | 假 |
| 真 | 不确定 | 不确定 |
| 假 | 真 | 假 |
| 假 | 假 | 假 |
| 假 | 不确定 | 假 |
| 不确定 | 真 | 不确定 |
| 不确定 | 假 | 假 |
| 不确定 | 不确定 | 不确定 |
OR 真值表
| P | Q | P & Q |
|---|---|---|
| 真 | 真 | 真 |
| 真 | 假 | 真 |
| 真 | 不确定 | 真 |
| 假 | 真 | 真 |
| 假 | 假 | 假 |
| 假 | 不确定 | 不确定 |
| 不确定 | 真 | 真 |
| 不确定 | 假 | 不确定 |
| 不确定 | 不确定 | 不确定 |
- 括号的使用符合数学规范。
- 聚合运算:使用聚合函数对数据进行多行汇总(输入多行输出一行)。
COUNT计算记录数/行数COUNT(*)时得到包含 NULL 的行数,COUNT(<列名>)时得到该列的 NULL 之外的行数。COUNT(DISTINCT <列名>)去重计数。
SUM计算合计值SUM(DISTINCT <列名>)合计去重项目。所有的聚合函数都可以使用 DISTINCT 先去重再聚合。
AVG计算平均值MAX计算最大值- 适用于能排序的数据类型。
MIN计算最小值- 适用于能排序的数据类型。
NULL
- NULL:没有值的标记。
- SQL 里的 NULL 和其他编程语言里的 NULL 是完全不同的东西。很多编程语言里,NULL 被赋予了常量,比如 0。
- 含有 NULL 的四则运算结果都是 NULL。
- 对含有 NULL 的列进行聚合运算,运算时会将含 NULL 的行排除在外。
- 要将 NULL 作为 0 计算时,需要额外设置。
- 不能对 NULL 进行比较运算,返回的结果也是 NULL。
- 因为比较谓词只适用于值,而 NULL 只是一个没有值的标记而已。
- 判断是否为 NULL,使用
IS NULL或IS NOT NULL。 - 数据库的数据一般都尽量不保存 NULL,来确保数据的有效和逻辑的简化。
- NULL 导致的三值逻辑:
- NULL 的两种含义:未知(unknown)和不适用/无意义(not applicable)
- 注意:unknown 是明确的布尔类型真值,而 NULL 的 unknown 含义只是一种含义。
- 含有 unknown 的三值真值表
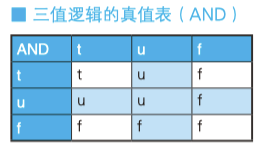
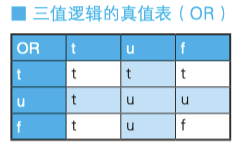
- 可以看出三值真值表具有优先级:
- AND 的情况:false > unknown > true
- OR 的情况:true > unknown > false
- 排中律变化:
WHERE age = 20 OR age <> 20 OR age IS NULL才能包含所有情况,如果漏写age IS NULL则会漏掉数据。 - 优先采用搜索类型 CASE:
CASE col WHEN NULL THEN 'X' END等同于CASE WHEN col = NULL THEN 'X' END,此时 CASE 中判断返回的是 unknown,永远不可能是 True,即永远不会出现 X。 - IN 和 EXIST 等价,但数据只要有一行是 NULL,则 NOT IN 和 NOT EXIST 不可等价。
分组
SELECT
<列名>,
...
FROM <表名>
[WHERE <筛选条件>]
GROUP BY <列名>, ...
[HAVING <分组结果的筛选条件>]
;
GROUP BY能实现对数据的分组,返回的分组结果是无序的。- 配合聚合函数使用,可以实现分组聚合。分组列必须同时存在于
SELECT子句和GROUP BY子句中。 - 分组列中含
NULL时,NULL也会作为一组。 GROUP BY子句不能使用SELECT子句中的别名,因为GROUP BY会先于SELECT执行。个别数据库支持在GROUP BY中使用别名,但并不是通用的方式。- 不能在
WHERE中对聚合结果进行筛选。需要使用HAVING子句。 HAVING可以当作在GROUP BY的“结果表”上进行操作。HAVING仅能筛选分组列、聚合结果、常数。- 筛选分组列的逻辑,最好写在
WHERE子句中。一是逻辑上更清晰,WHERE是对行的筛选,HAVING是对分组结果的筛选。二是执行速度会更快。
- 筛选分组列的逻辑,最好写在
排序
SELECT <列名>, ...
FROM < 表名 >
ORDER BY <排序列>, ...
ORDER BY子句可以实现按某列进行排序。默认升序排列,可以排序列后接ASC明确按升序排列,可以在排序列后接DESC进行降序排列。- 多个排序列,会按排序列的先后次序排序。
- NULL 的结果会排序到所有数据的开头或末尾,取决于数据库。
- 排序列可以使用
SELECT子句中的别名。因为SELECT先于ORDER BY子句,后于GROUP BY子句执行 ORDER BY可以按未 SELECT 的语句排序。ORDER BY可以按聚合函数的结果排序。ORDER BY可以按列编号排序。- 列编号:
SELECT子句中的列按照从左到右的顺序进行排列时所对应的排序号。 - 不推荐使用,因阅读困难。特别是语句复杂时。SQL-92 中说该功能会被删除。
- 列编号:
视图
- 使用 SELECT 语句时不需要考虑视图和表的差异。
- 表和视图的差别
- 视图保存的是 SELECT 语句,不存储数据。使用时执行该 SELECT 语句创造出临时表。
- 可以使用所有的 SELECT 子句
- 表保存的是数据。
- 视图保存的是 SELECT 语句,不存储数据。使用时执行该 SELECT 语句创造出临时表。
- 视图的优点:
- 节省存储设备的容量,因为视图不存储数据。
- 频繁使用的 SELECT 语句作为视图保存,方便使用,提高效率,特别对于长 SELECT。
- 视图的数据会随着原表自动更新。
- 可以通过视图限制用户的权限,提供给他们所需的数据,而不需要对其开放重要的表权限。
- 多重视图:可以以视图为基础创建新的视图。
- 大多数 DBMS 中使用多重视图会降低 SQL性能,所以尽量避免。
- 也有些 DBMS 会在内部对 SQL 重组。
- 视图的限制
- 不能使用 ORDER BY 子句。因为视图和表一样,数据行是没有顺序的。
- 有些 DMBS 是可以使用 ORDER BY 子句的。
- 一定条件下可以进行视图的增删改。简单说,无法判断如何将视图的修改反映到原表中时,操作无法进行。
- SELECT 子句中未使用 DISTINCT
- FROM 子句只有一张表
- 未使用 GROUP BY 子句
- 未使用 HAVING 子句
- 不能使用 ORDER BY 子句。因为视图和表一样,数据行是没有顺序的。
-- 创建 View
CREATE VIEW <视图名> (<视图列名1>, <视图列名2>...)
AS -- 必不可少的 AS
<SELECT 语句>
;
-- 删除 View
DROP VIEW <视图名> (<视图列名1>, <视图列名2>...);
-- 删除关联视图
DROP VIEW <视图名> CASCADE;
子查询 Sub-query
- 子查询可以被认为是一次性视图(SELECT 语句)。与视图不同,子查询在 SELECT 语句执行完毕之后就会消失。
- 可以说,子查询就是将用来定义视图的 SELECT 语句直接用于 FROM 子句当中。
- 首先会执行 FROM 子句 中的 SELECT 语句,然后才会执行外层的 SELECT 语句。
- 子查询的层数没有上限。
原则上子查询必须设定名称,最好是按查询结果的含义赋予名称,便于理解。
-- 一个子查询案例 SELECT product_type, cnt_product FROM (SELECT * FROM (SELECT product_type, COUNT(*) AS cnt_product FROM Product GROUP BY product_type) AS ProductSu WHERE cnt_product = 4) AS ProductSum2;标量子查询:是返回单一值的子查询。
- 在很多场合下很有用处。
- 能够使用常数或者列名的地方, 无论是 SELECT 子句、 GROUP BY 子句、 HAVING 子句, 还是 ORDER BY 子句,几乎所有的地方都可以使用。
- 标量子查询绝对不能返回多行结果。否则不能被用在 = 或者 <> 等需要单一输入值的运算符当中,也不能用在 SELECT 等子句当中。
-- WHERE 句中的标量子查询 SELECT product_id, product_name, sale_price FROM Product WHERE sale_price > (SELECT AVG(sale_price) FROM Product);
关联子查询
- 在子查询中添加的 WHERE 子句的条件,并和主查询关联,则形成关联子查询。
- 注意,关联条件必须写在子查询中。
-- 关联子查询的案例 SELECT product_type, product_name, sale_price FROM Product AS P1 WHERE sale_price > (SELECT AVG(sale_price) FROM Product AS P2 -- 此处是关键,关联条件必须写在子查询中。 WHERE P1.product_type = P2.product_type GROUP BY product_type);
函数
- sql 中的函数为使用者提供了丰富的功能,借助内置函数,我们可以按需求操作数据,而不用关心复杂操作的具体实现方式。
- 函数大致分类
- 算术函数:数值计算
- 字符串函数:操作字符串
- 日期函数:操作日期
- 转换函数:转换数据类型和值
- 聚合函数:进行数据聚合
- 函数总数较大,但常用的不过一二十种。学习函数具体功能的最佳方式,就是查看当前数据库提供的参考文档。
算术函数
- 最常用的加减乘除功能,已经由相应的操作符提供。
ROUND(对象数值, 保留小数的位数)四舍五入ABS()绝对值MOD(被除数, 除数)计算除法余数,是modulo的缩写。
字符串函数
- 注意!不同数据库的字符串函数有明显的差异,需先自行学习一遍,才能找到适合的函数。
字符串A || 字符串B拼接字符串,如果有一个字段是 NULL,结果也是 NULL。- 可以继续串联着拼接多个字符串。
||适用于 PostgreSQL+适用于 SQLServerCONCAT()适用于 MySQL 和 HiveQL
LENGTH(字符串)字符串长度- SQLServer 中是
LEN() - 字符分单字节和多字节,汉字全角字符会占用2个或以上字符,需要注意。
- SQLServer 中是
LOWER()和UPPER()英文大小写转换REPLACE(对象字符串, 待替换的字符串, 替换的字符串)SUBSTRING(对象字符串 FROM 开始截取的位置 FOR 截取的字符数)字符串的截取,这是 PostgreSQL 和 MySQL 的专用语法。SUBSTRING(对象字符串,截取的起始位置,截取的字符数)SQLServerSUBSTR(对象字符串,截取的起始位置,截取的字符数)Oracle 和 DB2
日期函数
- 各 DBMS 的日期函数各不相同,以数据库文档为准。
转换函数
- (1)是指数据类型的转换,即类型转换,各类编程语言中都有,即 CAST。
- (2)是指值的转换。
CAST(转换前的值 AS 想要转换的数据类型)进行类型转换COALESCE(数据1, 数据2, 数据3 …… )将 NULL 转换为其他值- 有的数据库里是
NVL()
- 有的数据库里是
聚合函数
主要就是 count(), min(), max() 等。见《Hive 聚合函数》
谓词
谓词 predicate,可以认为是函数的一种,不过函数可以返回任何值,谓词返回的都是真值(TRUE/FASLE/UNKNOWN)。
-
LIKE
用于判断字符串部分一致。之前的
=只能判断字符串是否完全一致。%是代表“0 字符以上的任意字符串”的特殊符号_代表 “任意一个字符”
- 前方一致:
col LIKE 'ddd%' - 中间一致:
col LIKE '%ddd%' - 后方一致:
col LIKE '%ddd'
BETWEEN
- 选择某个值在某一段范围内
- 字符串时候,
WHERE NAME BETWEEN 'A' AND 'J'是 [A,J) - 数值的时候,则首尾都包含
WHERE YEAR BETWEEN 1999 AND 2000- 如果不想包含临界值,则用
<和>
- 如果不想包含临界值,则用
IS NULL 和 IS NOT NULL
- NULL 的判断不能用
=
IN
- OR 的简便用法,当需要比较的值数量较多时,用 IN 方便。
- 也可以
NOT IN - 可以使用子查询作为 IN 的参数。
SELECT product_name, sale_price
FROM Product
WHERE product_id IN (SELECT product_id FROM ShopProduct WHERE shop_id = '000C');
EXIST
- 基本上可以用 IN 或者 NOT IN 来替代。相对而言,理解较难。但是熟练使用,也可提供便利。
- EXIST (存在)谓词的主语是“记录”。
- EXIST 只需要在右侧书写 1 个参数,该参数通常都会是一个子查询。
- NOT EXIST 与 EXIST 相反,当“不存在”满足子查询中指定条件的记录时返回真( TRUE )。
-- 000C 店铺 的在销商品单价
SELECT product_name, sale_price
FROM Product AS P
WHERE EXISTS (SELECT *
FROM ShopProduct AS SP
WHERE SP.shop_id = '000C'
AND SP.product_id = P.product_id);
-- EXIST只关心是否有满足条件的记录,而不关心列,所以子查询中的 SELECT * 写成 SELECT 1 也行
CASE 表达式
- CASE 表达式提供了条件分支的功能。
- CASE 表达式是标准SQL中提供的功能,有些 DBMS 还提供了一些特有的 CASE 表达式的简化函数, 例如 Oracle 中的 DECODE 、MySQL 中的 IF 等。
- 在发现为真的 WHEN 子句时, CASE 表达式的真假值判断就会中止,而剩余的 WHEN 子句会被忽略。为了 避免引起不必要的混乱,使用 WHEN 子句时要注意条件的排他性。
- 养成写 ELSE 语句的习惯,避免语句执行完毕时无 ELSE 而输出 NULL。
- CASE 语句内可以使用聚合函数,可以使得需要先聚合后再判断的语句变得简单。
```sql
CASE WHEN < 求值表达式 > THEN < 表达式 >
WHEN < 求值表达式 > THEN < 表达式 >WHEN < 求值表达式 > THEN < 表达式 >
. . ELSE < 表达式 > END.
— 使用搜索 CASE 表达式的情况 SELECT product_name, CASE WHEN product_type = ‘ 衣服 ‘ THEN ‘A : ‘ | | product_type WHEN product_type = ‘ 办公用品 ‘ THEN ‘B : ‘ | | product_type WHEN product_type = ‘ 厨房用具 ‘ THEN ‘C : ‘ | | product_type ELSE NULL END AS abc_product_type FROM Product;
— 使用简单 CASE 表达式的情况 SELECT product_name, CASE product_type WHEN ‘ 衣服 ‘ THEN ‘A : ‘ | | product_type WHEN ‘ 办公用品 ‘ THEN ‘B : ‘ | | product_type WHEN ‘ 厨房用具 ‘ THEN ‘C : ‘ | | product_type ELSE NULL END AS abc_product_type FROM Product;
— CASE 中使用聚合函数 SELECT std_id, CASE WHEN COUNT(*) = 1 — 只加入了一个社团的学生 THEN MAX(club_id) ELSE MAX(CASE WHEN main_club_flg = ‘Y’ THEN club_id ELSE NULL END) END AS main_club FROM StudentClub GROUP BY std_id;
<a name="JYnee"></a>
## 集合运算
- 对满足同一规则的记录进行的加减等四则运算。通过集 合运算,可以得到两张表中记录的集合或者公共记录的集合,又或者其中 某张表中的记录的集合。
<a name="xvGKX"></a>
### UNION
- UNION 用于取两段查询结果的并集。需要注意:
- (1)列数量必须相同。
- (2)对应的列的类型必须一致。
- (3)可以使用任何 SELECT 语句,但 ORDER BY 子句只能在最后一段子查询中使用。
- UNION 会去除重复的记录。UNION ALL 可以保留重复的行。
```sql
SELECT product_id, product_name
FROM Product
WHERE product_type = ' 厨房用具 '
UNION
SELECT product_id, product_name
FROM Product2
WHERE product_type = ' 厨房用具 '
ORDER BY product_id;
INTERSECT
- 用于取出交集,即公共部分。
- 语法和 UNION 一样。 ```sql SELECT product_id, product_name FROM Product
INTERSECT
SELECT product_id, product_name FROM Product2 ORDER BY product_id;
<a name="hh1hO"></a>
### EXCEPT
- 用于集合的减法运算。
- 被减的集合 EXCEPT 减去的集合
```sql
SELECT product_id, product_name
FROM Product
EXCEPT
SELECT product_id, product_name
FROM Product2
ORDER BY product_id;
表的联结(JOIN)
表的联结操作,可谓是 SQL 数据处理的核心技能,也是各类 SQL 教材的重点。此处不赘述概念细节,只做语法功能的记录。
内联结 INNER JOIN
通过 ON 子句的联结条件进行。
- 使用联结运算将满足相同规则的表联结起来时, WHERE 、 GROUP BY 、 HAVING 、 ORDER BY 等工具都可以正常使用。
外联结 OUTER JOIN
- 有一点非常重要,那就是要把哪张表作为主表。
- 指定主表的关键字是 LEFT 和 RIGHT。
交叉联结 CROSS JOIN(笛卡尔积)
- 交叉联结在实际业务中并不会使用,但是所有联结操作的基础。
- 对满足相同规则的表进行交叉联结的集合运算符是 CROSS JOIN (笛卡儿积)。进行交叉联结时无法使用内联结和外联结中所使用的 ON 子句, 这是因为交叉联结是对两张表中的全部记录进行交叉组合,因此结果中的记录数通常是两张表中行数的乘积。
过时的语法
- SQL 是一门特定语法及过时语法非常多的语言,联结是其中特定语法的部分,现在还有不少年长的程序员和 系统工程师仍在使用这些特定的语法。(笔者:此句摘抄。让我心中欣慰,原来这些都是过时语法,而不是某种炫技。)
- 内联结的过时语法: ```sql SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name, P.sale_price FROM ShopProduct SP, Product P WHERE SP.product_id = P.product_id AND SP.shop_id = ‘000A’;
— 这样的语法不仅过时,而且还存在很多其他的问题,理由主要有以下三点: — 第一,使用这样的语法无法马上判断出到底是内联结还是外联结(又或者是其他种类的联结)。 — 第二,由于条件都写在 WHERE 子句之中,因此无法在短时间内分辨出哪部分是联结条件,哪部分是用来选取记录的限制条件。 — 第三,我们不知道这样的语法到底还能使用多久。每个 DBMS 的开发者都会考虑放弃过时的语法,转而支持新的语法。虽然并不是马上就不能使用了,但那一天总会到来的。
<a name="GTsc3"></a>
## 窗口函数
- 窗口函数也称为 OLAP 函数。
- 关系数据库提供支持 OLAP 用途的功能仅仅只有 10 年左右(以2016年前后算)的时间。
- 窗口函数基本语法:
- 原则上只能写在 SELECT 子句中。因为,在 DBMS 内部,窗口函数是对 WHERE 子句或者 GROUP BY 子句处理后的“结果”进行的操作。如果通过 WHERE 子句中的条件除去了某些记录,或者使用 GROUP BY 子句进行了汇总处理,那好不容易得到的排序结果也无法使用了。
```sql
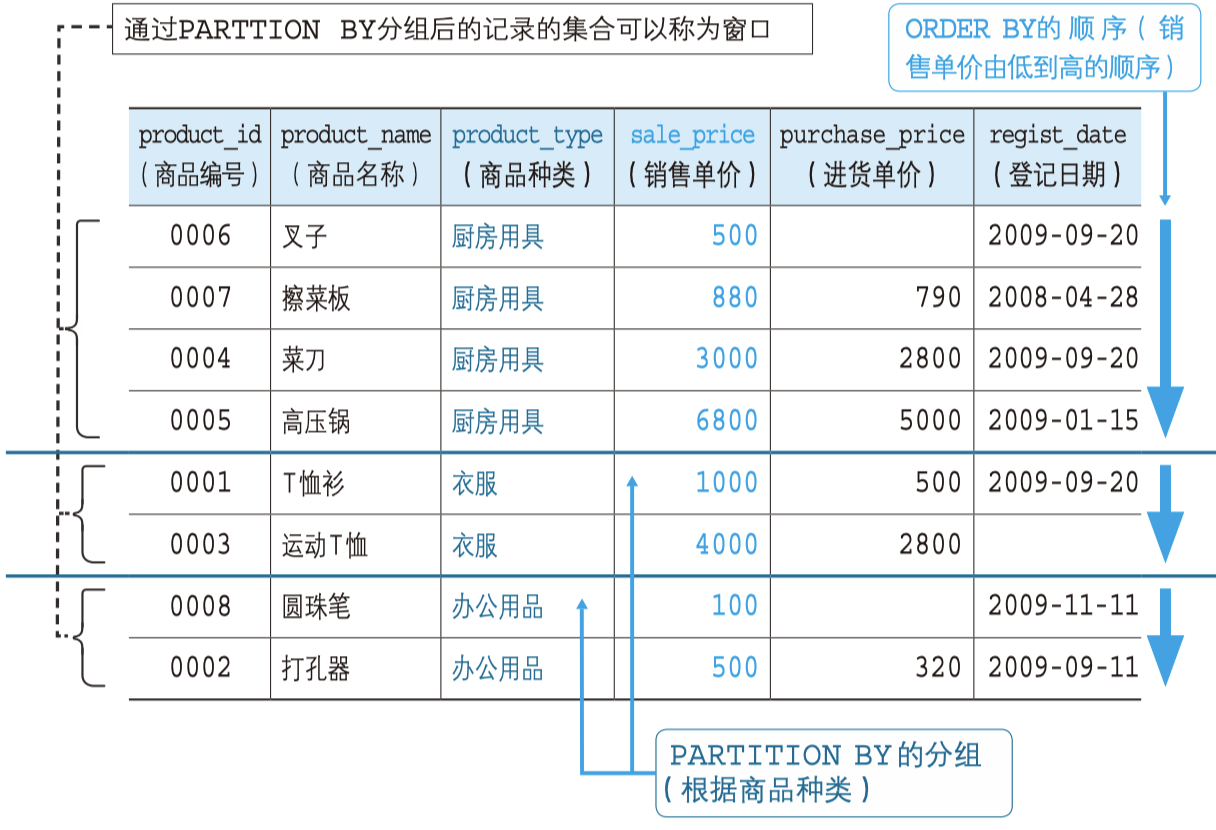
<窗口函数> OVER ([PARTITION BY <列清单>] ORDER BY <排序用列清单>)
-- PARTITION BY 能够设定排序的对象范围。和 GROUP BY 相比,PARTITION BY 并不具备 GROUP BY 子句的汇总功能。
-- 通过 PARTITION BY 分组后的记录集合称为窗口。此处的窗口并 非“窗户”的意思,而是代表范围。
-- PARTITION BY 并不是必需的,即使不指定也可以正常使用窗口函数。这和使用没有 GROUP BY 的聚合函数时的效果一样,也就是将整个表作为一个大的窗口来使用。
-- ORDER BY 能够指定按照哪一列、何种顺序进行排序。
-- OVER 子句中的 ORDER BY 只是用来决定窗口函数按照什么样的顺序进行计算的,对结果的排列顺序并没有影响。
-- 如果想要让记录切实按照 ranking 列进行排列,在 SELECT 语句的最后,使用 ORDER BY 子句进行指定即可。
- 窗口函数大体可以分为以下两种:
- (1)能够作为窗口函数的聚合函数(SUM、AVG、COUNT、MAX、MIN)
- (2)RANK、DENSE_RANK、ROW_NUMBER 等专用窗口函数
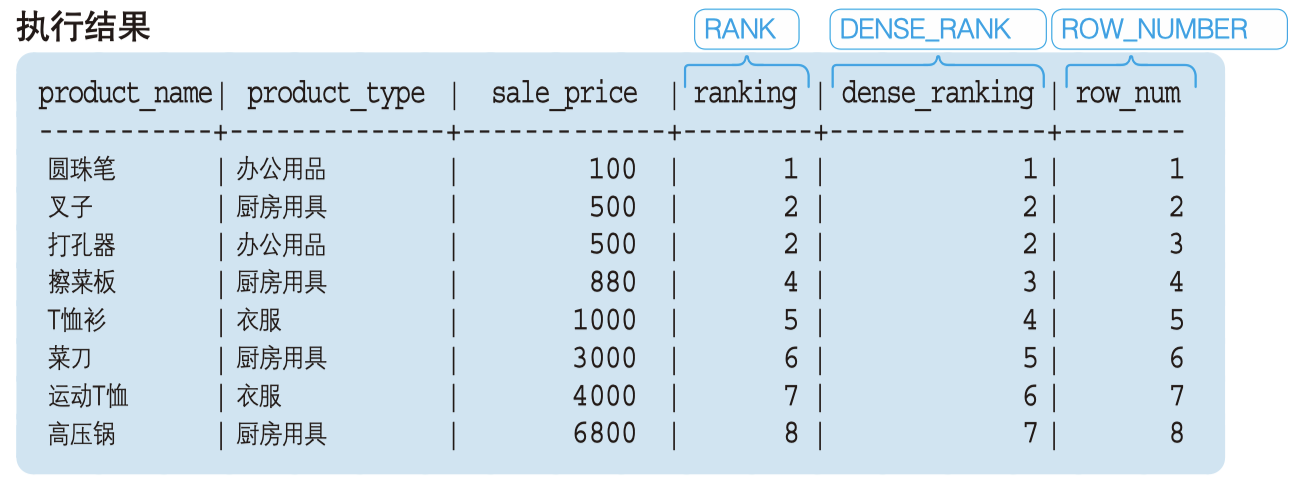
RANK()
- RANK 是用来计算记录排序的函数。
- 计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
- 例:有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
DENSE_RANK()
- 同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
- 例如:有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
ROW_NUMBER()
- 赋予唯一的连续位次。
例:有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……
三个排序函数的对比,都按 price 排序时:
计算移动平均
- 使用了 ROWS (“行”)和 PRECEDING (“之前”) 字,将框架指定为“截止到之前 n 行”,就是将作为汇总对象的记录限 定为如下的“最靠近的 n+1 行”。
- 当前行
- 之前1行 到 之前 n-1 行
- 之前n行 ```sql — 例子 1 SELECT product_id, product_name, sale_price, AVG (sale_price) OVER (ORDER BY product_id ROWS 2 PRECEDING) AS moving_avg FROM Product;
SELECT product_id, product_name, sale_price, AVG (sale_price) OVER (ORDER BY product_id ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving_avg FROM Product;
- 使用关键字 FOLLOWING (“之后”)替换 PRECEDING ,就可以指 定“截止到之后 ~ 行”作为框架
- 同时使用 PRECEDING (“之前”)和 FOLLOWING (“之后") 关键字来实现。
<a name="bkmIm"></a>
## GROUPING 运算符
- 为了满足计算合计之类的需求,标准 SQL 引入了 GROUPING 运算符。包含:
- ROLLUP
- CUBE
- GROUPING SETS
- 注意:此处的语法,还不确定 HiveQL 是否支持。
<a name="HRF1w"></a>
### ROLLUP()
- 从语法上来说,就是将 GROUP BY 子句中的聚合键清单像 `ROLLUP(<列1>, <列2>,...)` 来使用。
- 合计部分叫做超级分组记录 super group row,缺少键值,默认使用 NULL。
```sql
SELECT product_type, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type);
- 当 ROLLUP 中有多个列时,返回的小计是按列顺序的,如下图,ROLLUP同时给出了合计和小计。
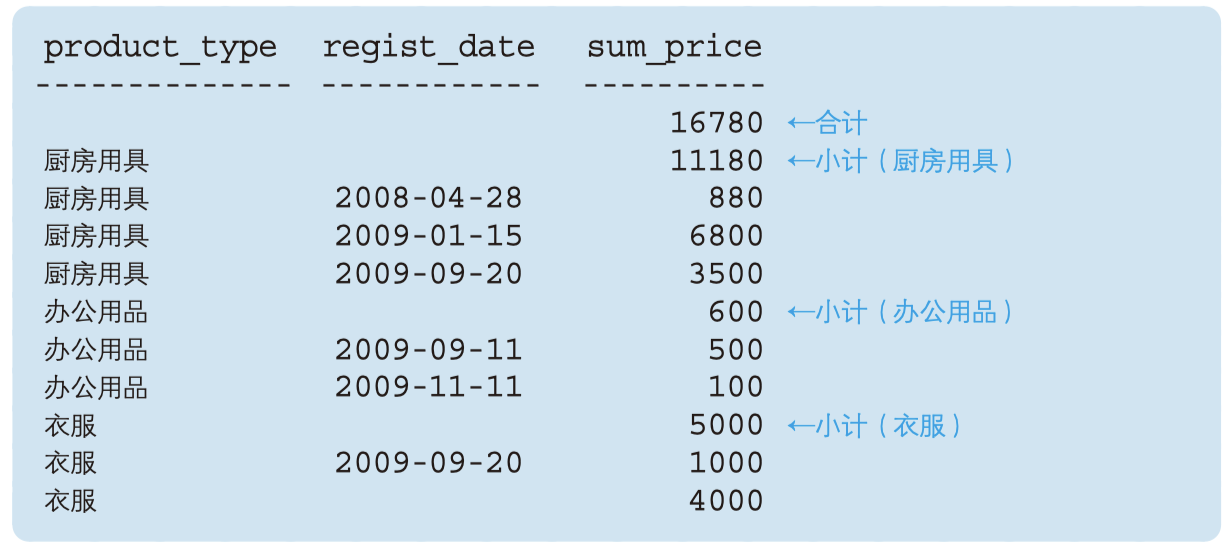
为了避免返回的 NULL 难以阅读,可以用 GROUPING 函数来判别。该函数在其参数列的值为超级分组记录 所产生的 NULL 时返回 1 ,其他情况返回 0。再通过数值判断,来指定合计或小计时候的字符串即可。
SELECT CASE WHEN GROUPING(product_type) = 1 THEN ' 商品种类 合计 ' ELSE product_type END AS product_type, CASE WHEN GROUPING(regist_date) = 1 THEN ' 登记日期 合计 ' ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date, SUM(sale_price) AS sum_price FROM Product GROUP BY ROLLUP(product_type, regist_date);CUBE()
所谓 CUBE ,就是将 GROUP BY 子句中聚合键的“所有可能的组合” 的汇总结果集中到一个结果中。
- 组合的个数为 2^n 个。
- CUBE 的语法和 ROLLUP 相同,只需要将 ROLLUP 替换为 CUBE 就 可以了。
GROUPING SETS
- GROUPING SETS 运算符可以用于从 ROLLUP 或者 CUBE 的结果中取出部分记录。
- 由于期望获得不固定结果的情况少之又少,这个操作符很少用到。
-- 如果希望从中选取出将“商品种类”和“登记日期”各自作为聚 合键的结果,或者不想得到“合计记录和使用 2 个聚合键的记录”时,可 以使用 GROUPING SETS SELECT CASE WHEN GROUPING(product_type) = 1 THEN ' 商品种类 合计 ' ELSE product_type END AS product_type, CASE WHEN GROUPING(regist_date) = 1 THEN ' 登记日期 合计 ' ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date, SUM(sale_price) AS sum_price FROM Product GROUP BY GROUPING SETS (product_type, regist_date);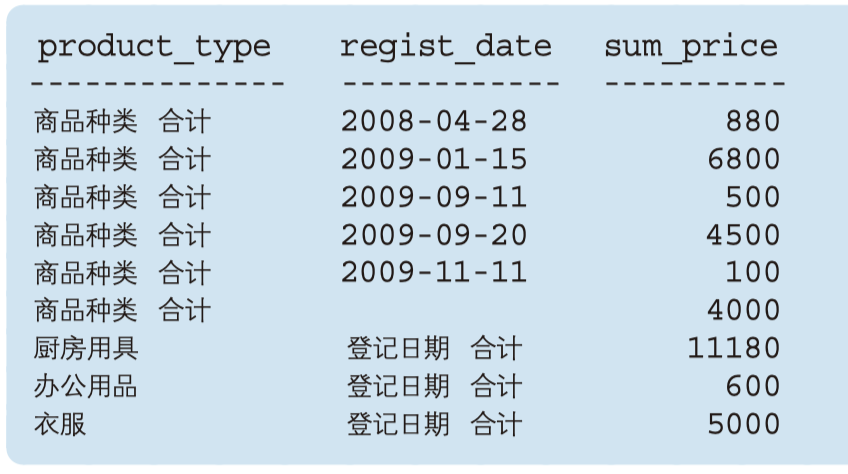

若有收获,就点个赞吧
0 人点赞
