image restorationlatent
| keywords | image restoration |
|---|---|
| release time | 2020.4.20 |
| journal | CVPR2020 oral |
| intorduction | 实现了三个domain的图像转换,出色地实现了图像修复 |
| institution | Microsoft |
| other |
这篇文章和我目前的工作内容非常贴!!好好学习一下里面对一些内容的叙述方法~
PS: 这篇文章有两个版本,journal版本比CVPR的版本多了很多细节,推荐journal版本。
Title
Bringing Old Photos Back to Life
Information
论文地址:https://arxiv.org/pdf/2009.07047v1.pdf
github地址:https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life
Summary
作者将图像复原的问题分解成 图像的Decoder/Encoder + latent translation的问题。将真实受损老照片和生成的受损老照片用VAE映射到同一个latent space,再用一个考虑了global和local的网络将其映射到干净照片的latent space,最后生成图片。
Contribution(s)
- latent restoration
-
Problem Statement
恢复受损严重(severe degradation)的老照片。
作者把degradation分为两类:非结构化受损(噪声、模糊、色彩淡化、低分辨率),结构化受损(孔缝、划痕、污点)
现有图像复原方法都很依赖生成图像的质量;仅考虑非结构化受损/结构化受损的一方面,没有全部考虑。因此总结一下面临的挑战:无法监督学习,degradation复杂,无法准确构造老照片的数据集。Method(s)
Restoration via latent space translation
作者为了减化问题,将老照片修复当成是image translation问题。区别于一般的image translation学习两个不同domain间的联系,本文需要学习三个domain:真实的老照片R,生成的受损老照片X、对应的修复好的ground truth Y。三维domain的转换在本文算法中至关重要。
X和Y中的图片是一一对应的,也就是说x是根据y生成的受损照片。想直接学习从R到Y的映射很难,因为不配对无法使用监督学习。为此,作者将translation分解成两个步骤,如下图所示。
将R、X、Y映射到latent code Z(映射网络用E表示,图中的蓝色实线、紫色实线)。由于R(真实老照片)和X(生成的老照片)都受损,他们应表现出相同特征,latent code应该在同一空间内。为此作者将R和X的latent space加了些限制,做了对齐。
- 学习从X的latent space到Y的latent space的映射(映射网络用T表示,图中的黄虚线)
- 学习从latent code生成修复后照片Y的生成网络G
- 最终,修复一张老照片的流程为:

Domain alignment in the VAE latent space
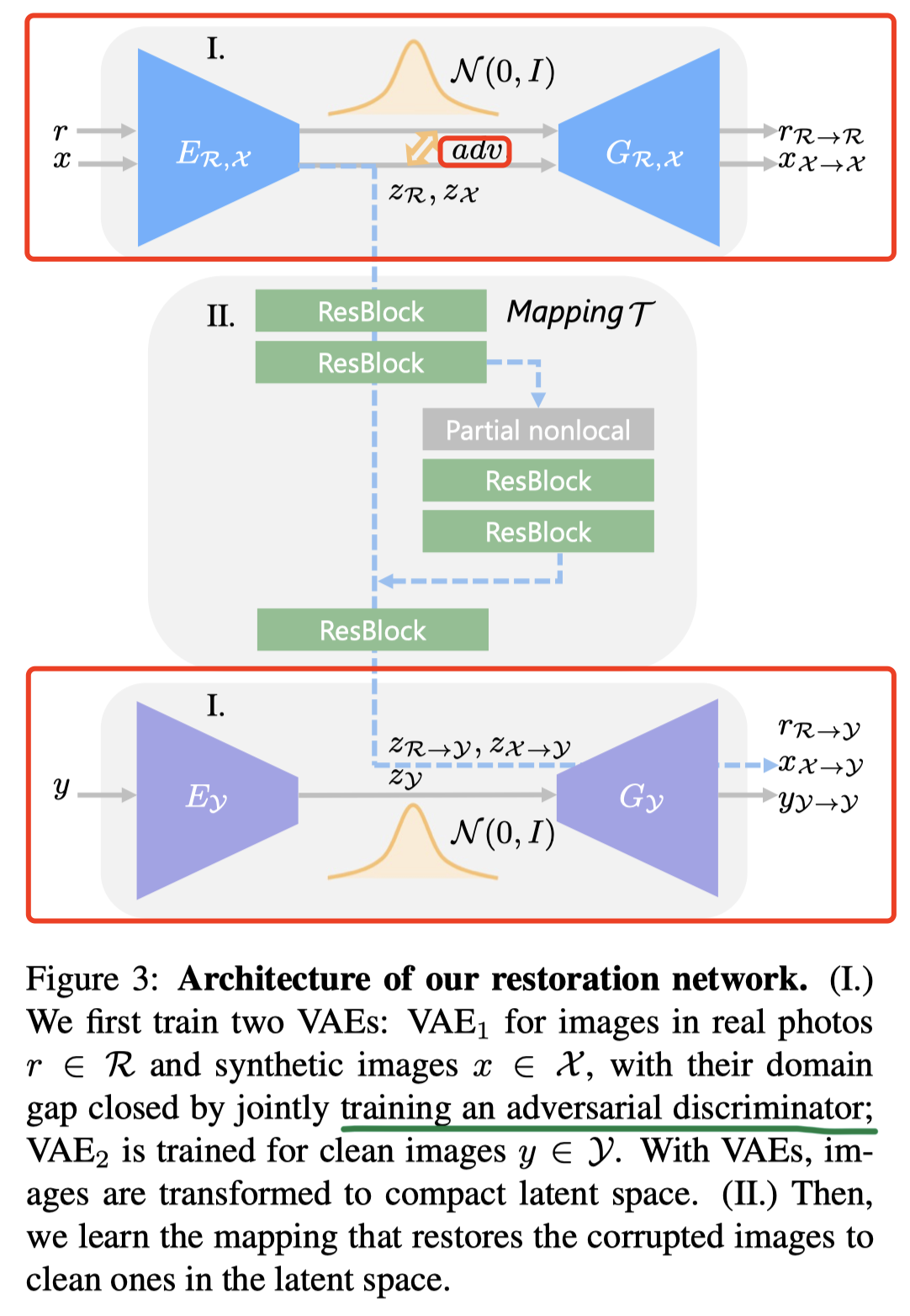
整个结构可以分成两个阶段,如上图中的阿拉伯数字所示。本节介绍网络结构的第一阶段:学习图像和latent code间的映射。
上文也提到了,需要将真实老照片和生成老照片映射到同一个latent space中。为了达到这一目标,真实老照片和生成老照片的映射共用一个VAE1(包括Encoder和Generator)。全部的VAE都假设latent codes呈高斯先验,这样图像可以通过采样重建。此外,作者还采用了re-parameterization trick(文献46)支持随机采样可微,这样就能用数据集R和X来分别优化VAE1。
用R来优化VAE1的损失函数如下:
解释一下这个公式,第一部分是KL散度,用来惩罚潜在分布和高斯先验的偏差,第二部分指VAE重建图像得到的输出需要和输入一致,第三部分则是引入LSGAN中的least-square loss,用来提高VAE生成图像的真实性。用X优化VAE1和用Y优化VAE2的方法同理。(这里的 作者在实现中取10)
作者在实现中取10)
为了使R和X映射到的latent space尽可能紧凑(这样可以缩小domain gap),作者首先采用了VAE而非vanilla autoencoder,这是因为用KL散度约束的VAE latent编码会更紧凑。接着,作者还训练了一个Discriminator,用来区分某一latent code是来自R还是来自X(即上图中的adv标识)。Discriminator的loss被定义为:
最后整个VAE1的优化目标为:
Restoration through latent mapping
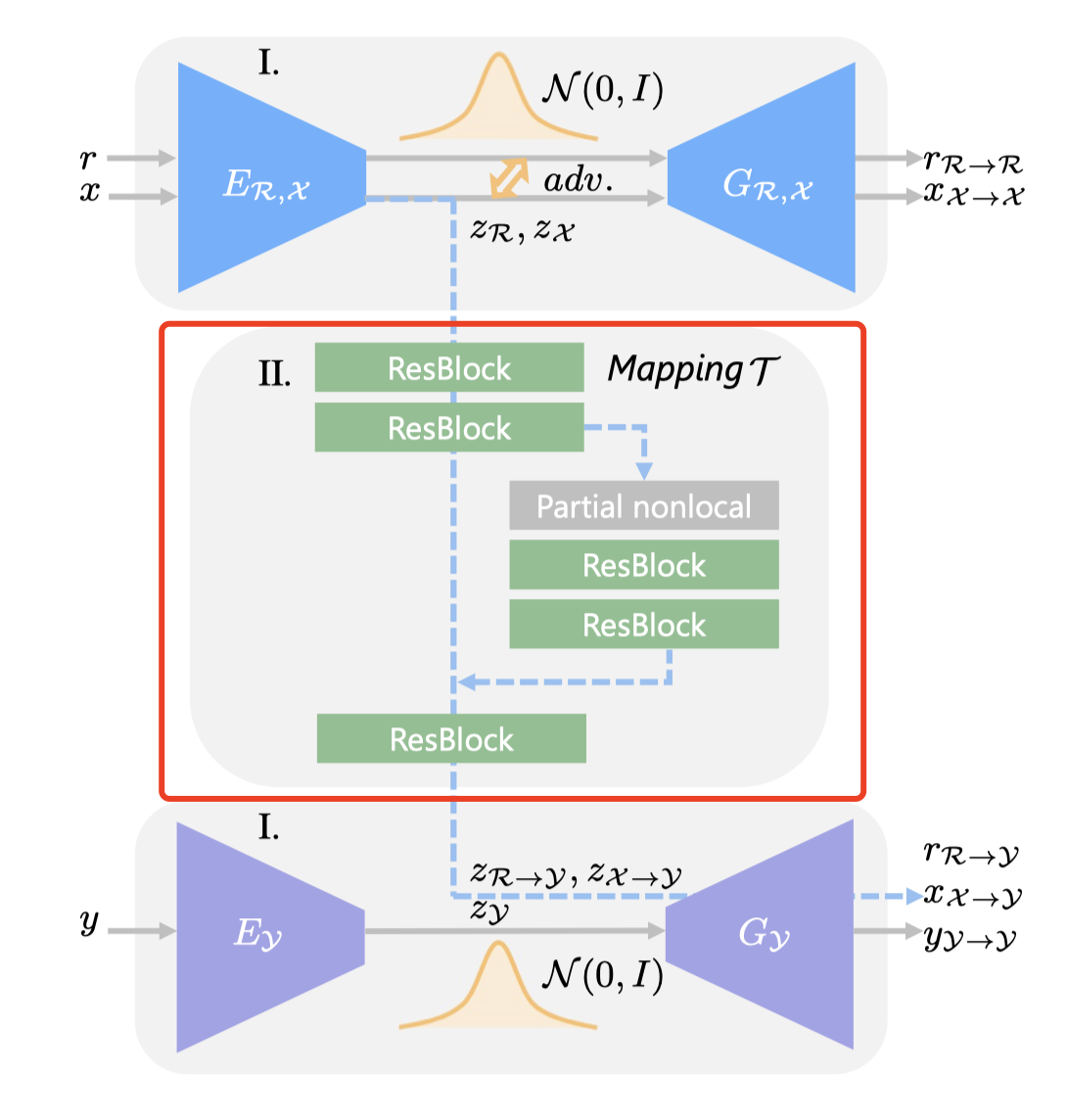
修复网络的第二阶段,学习从生成老照片到修复后照片的latent code的映射M。
作者认为学习latent restoratioin有三个好处。1. R和X对齐到同样的latent space了,学习到的映射同将能将R的latent code映射到干净无瑕疵的空间。2. 学习低维度的latent映射比学习高维的图像空间映射简单的多。3. 第一阶段的两个VAE是独立训练的,因此图像的重建过程不会受彼此的影响。这样,生成器Gy能永远得到一个干净的图像(与之对应的,如果我们直接使用像素级别的映射,原图中的瑕疵很可能仍然存在。
在这个阶段,作者会固定两个VAE的参数,只训练映射网络。映射网络的损失函数为:
(实验中, )它由三部分组成,第一部分表示latent space loss,用预期的latent code和输出的latent code的L1距离表示。第二部分借LSGAN的形式引入判别器,利用adversarial loss引导图像的真实性。第三部分,引入feature matching loss让GAN训练地更稳定,通俗地讲,就是一对图像pair,x和y,x获得的修复照片和y获得的重建图像,在adversarial network
)它由三部分组成,第一部分表示latent space loss,用预期的latent code和输出的latent code的L1距离表示。第二部分借LSGAN的形式引入判别器,利用adversarial loss引导图像的真实性。第三部分,引入feature matching loss让GAN训练地更稳定,通俗地讲,就是一对图像pair,x和y,x获得的修复照片和y获得的重建图像,在adversarial network  和预训练网络VGG的多层次特征是一致的(本质上就是perceptual loss)。
和预训练网络VGG的多层次特征是一致的(本质上就是perceptual loss)。
Multiple degradation restoration
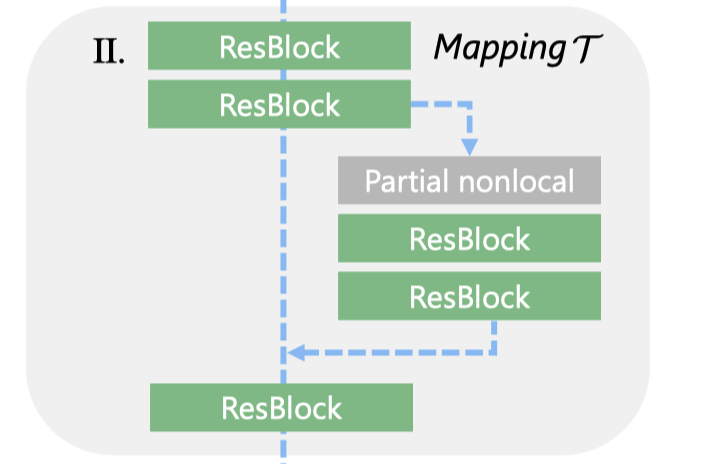
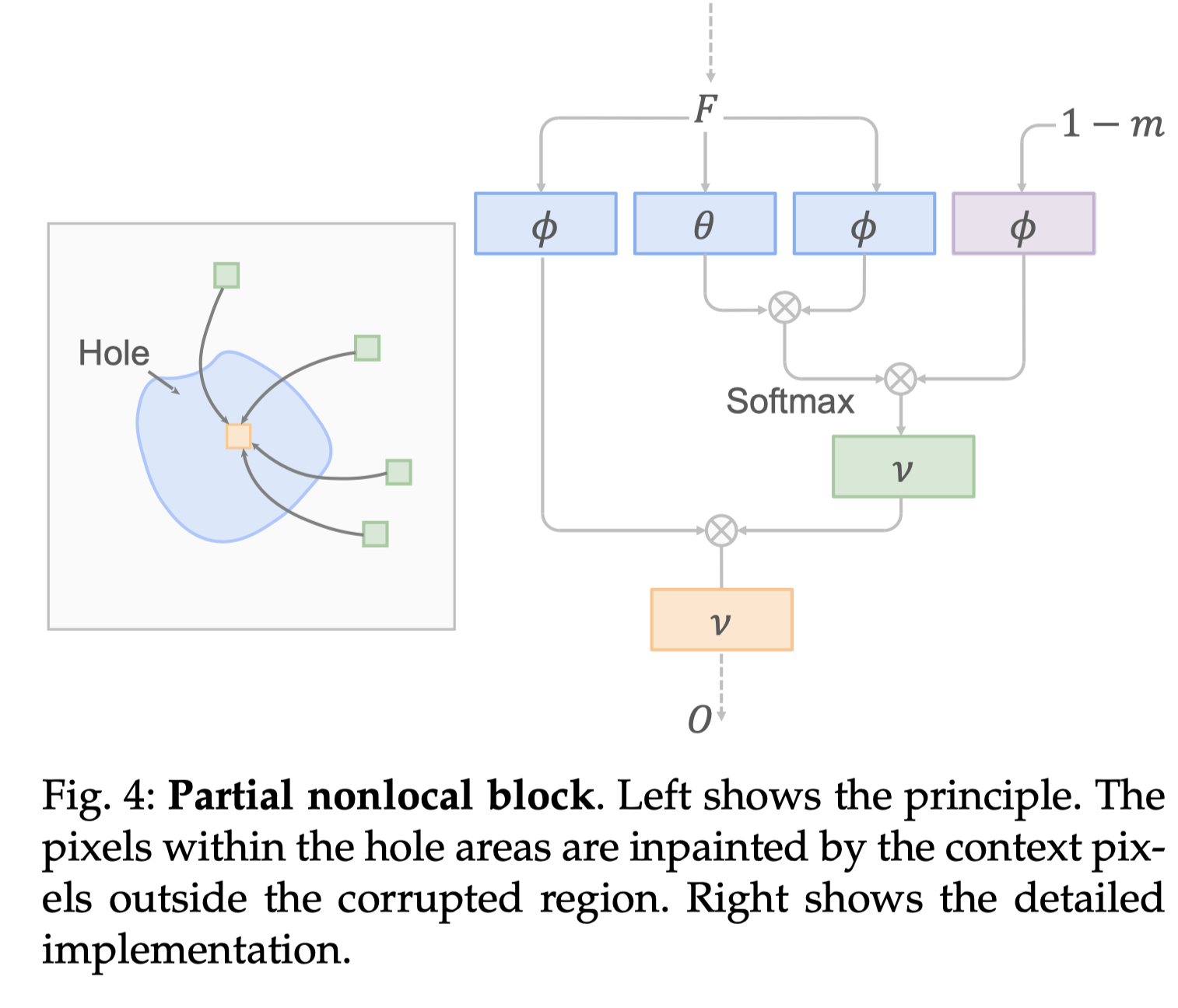
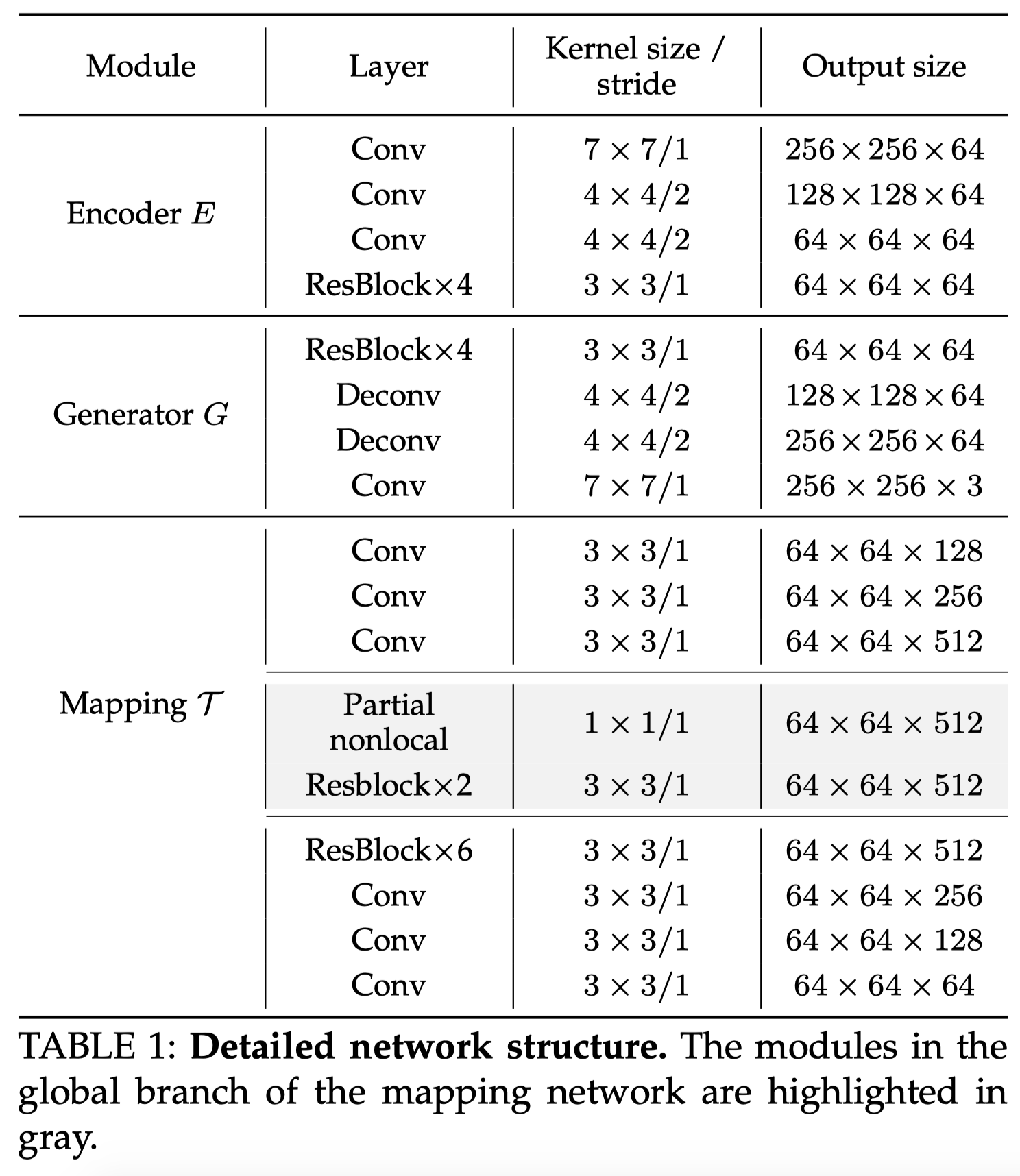
上一节只讲了latent code间映射的整体逻辑,但没有具体讲解网络。之前我们提过,老照片的瑕疵有结构化的和非结构化的。结构化瑕疵的修复依赖于整体特征,非结构化瑕疵的修复则依赖于局部特征。为此,作者构造了global branch,其中包含partial nonlocal block用来考虑全局纹理。
假设F是中间的特征图,m是二值mask,会采样到与F同样的大小,1表示需要修复的受损区域。在F中,i位置的像素和j位置的像素相似度 会根据掩摸后Fi和Fj的相关性(
会根据掩摸后Fi和Fj的相关性( )来计算:
)来计算: 通过embedded Gaussian计算得到。
通过embedded Gaussian计算得到。 用来将F映射到高斯空间。最终,partial nonlocal block的输出为:
用来将F映射到高斯空间。最终,partial nonlocal block的输出为: ,是每个位置的加权平均相关性特征。前面提到的
,是每个位置的加权平均相关性特征。前面提到的 都是用1×1卷积实现的。
都是用1×1卷积实现的。
除了global branch,还有一个local branch,根据掩码将它们的结果结合起来:
 表示Hadamard product(其实就是矩阵对应元素相乘)
表示Hadamard product(其实就是矩阵对应元素相乘)
整体结构
Experiment
Training dataset
真实数据集来自Pascal VOC dataset
收集了一些老照片的纹理和刮痕,用随机透明度的layer addition, lighten-only and screen modes叠加到真实照片上。为了模拟大范围的照片损坏,作者还生成了带有羽毛和随机形状的孔。
5,718张真实老照片
scratch detection
前面也提到了,partial nonlocal block是需要一个binary mask来标注结构化瑕疵。这里作者是训练了一个Unet结构的网络(作者称其为检测网络)。这个检测网络一开始只用生成图像训练,利用focal loss平衡正负向本。接着从783张有刮痕的老照片中挑出了400张进行finetune。finetune之后的ROC挺高,到0.91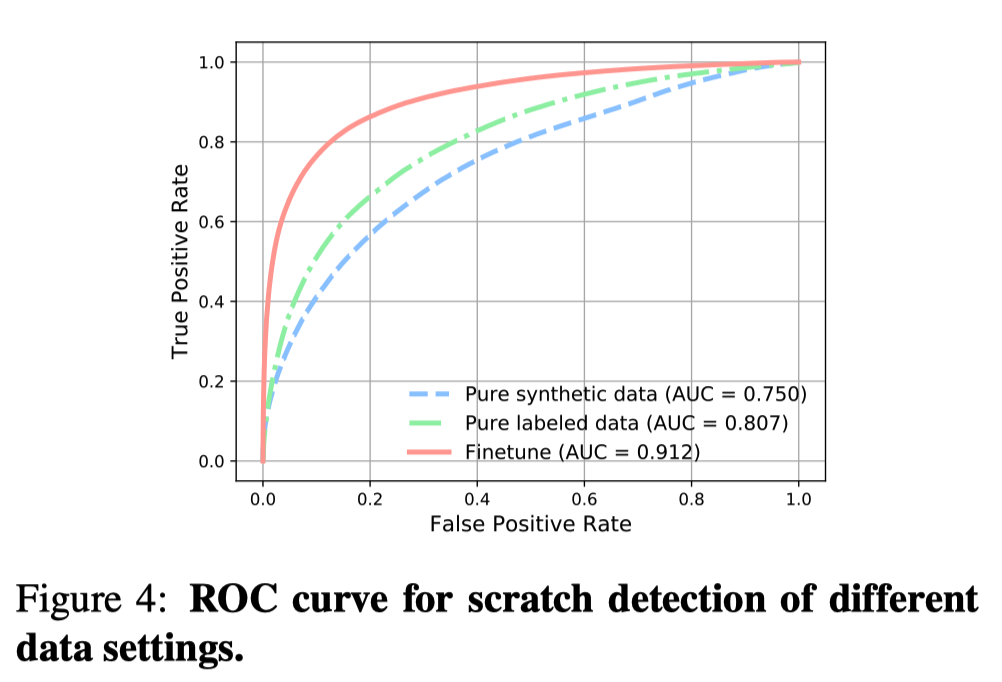
Evaluation
1、 和SOTA方法的Quantitative comparison
评价标准:
- PSNR、SSIM:low-level的区别,Operation-wise attention model最优
- LPIPS:更符合人的感知
- FID:生成模型的质量,主要计算生成图像和gt图像在特征分布的距离
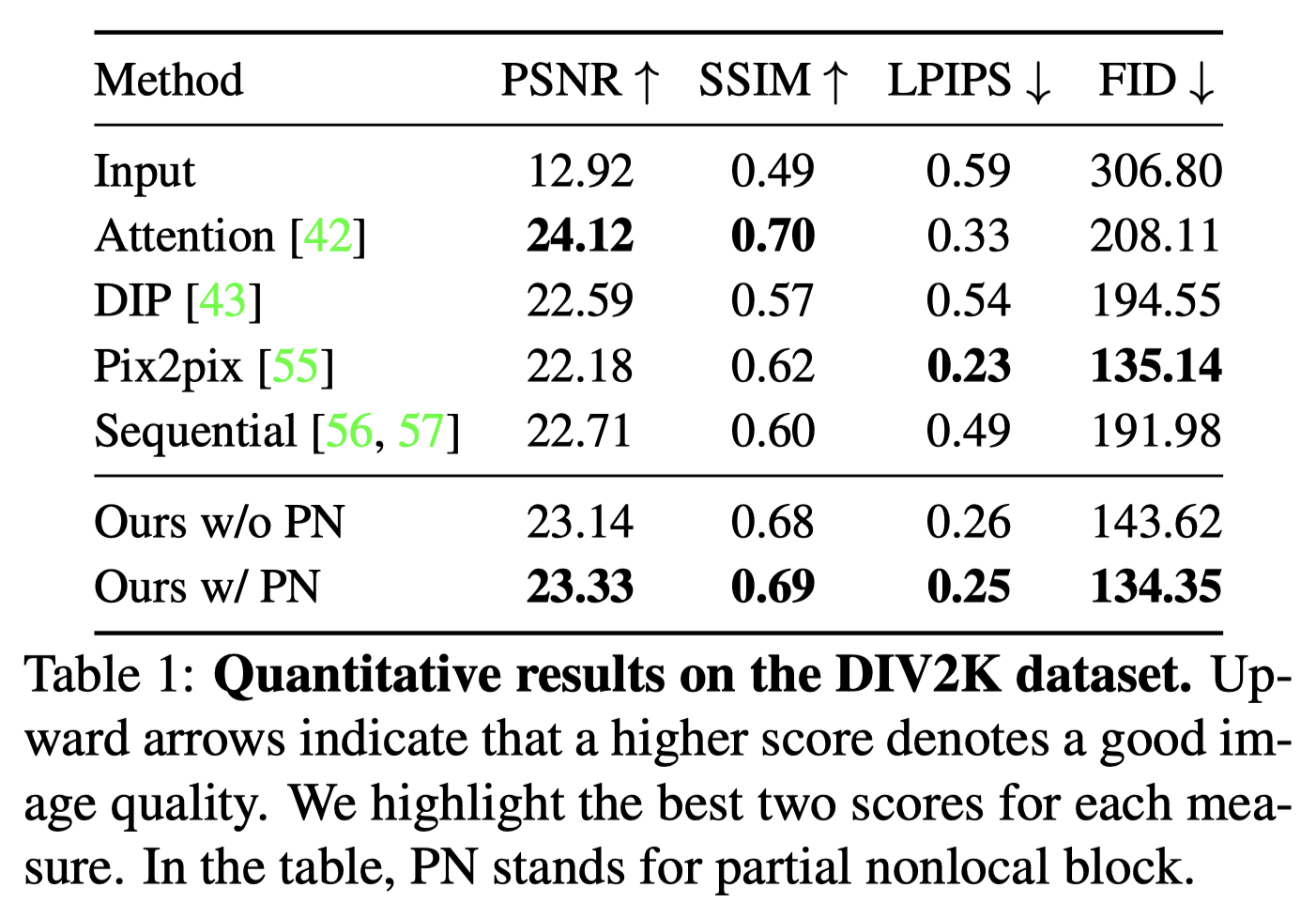
虽然这些指标没有都排第一,但作者有给一个合理的解释,证明总体效果仍然是有较高竞争力的。表中的PN表示partial nonlocal block,w/ 是with的意思,w/o是withoud,也证明有global branch效果会更好。
2、Qualitative comparison

此外,作者还做了user study
3、Ablation Study
(1)Pix2Pix
(2)用KL loss约束的两个VAE(这儿没能理解)
(3)两阶段的网络,即先训练两个VAE,再在不固定VAE的情况下训练映射网络
(4)上文叙述的完整网络(即在3的基础上需要固定VAE)


Conclusion
- 效果很好
- 但仍然无法解决复杂的伪影
Code
Notes
好的英语写法:
Prior to the deep learning era
好的叙述方法
- 受损包括结构化受损和非结构化受损。结构化瑕疵:污点、刮痕,非结构化瑕疵:模糊、噪声、低分辨率、色彩淡化。
结构化瑕疵需要全局的纹理信息,而非结构化瑕疵更多地依赖于局部的像素信息 - 真实照片中的瑕疵多种多样,难以用生成图片的方法去构造他们。
- 目前的图像修复技术难以涵盖这么多的瑕疵,因此,我们将其看作一个Image translation问题
Criticism
- 为了使R和X映射到的latent space尽可能紧凑,作者采用了VAE而非vanilla autoencoder,那别的有尝试吗?比如使用style gan中的mapping network是什么效果?
作者说nonlocal block利用mask input排除受损区域。哪里来的mask input- 作者说monlocal block要mask input标识structured defect,说是训练一个检测网络。应该是训练了一个分割网络吧。
Reference
非结构化受损(噪声、模糊、色彩淡化、低分辨率)的图像复原技术:
- non-local self-similarity
- 15
- 16
- 17
- sparsity
- 18
- 19
- 20
- 21
- local smoothness
- 22
- 23
- 24
- image denoising
- 5
- 6
- 25
- 26
- 27
- 28
- 29
- super resolution
- 7
- 30
- 31
- 32
- 33
- deblur
- 8
- 34
- 35
- 36
结构化受损(孔缝、划痕、污点)的图像复原技术:
- 37
- 38
- 39
- 40

若有收获,就点个赞吧
0 人点赞
