Title
文章标题:Blind Face Restoration via Deep Multi-scale Component Dictionaries
代码:https://github.com/csxmli2016/DFDNet
Summary
这篇文章有意思,我认为质量比较高,融合了很多技巧,思路也新颖。
作者靠KMeans构造五官字典,在生成网络中利用AdaIN、类别搜索、字典的置信度和reverse RoIAlign获取字典信息并复原人脸,效果很好。
Contribution(s)
- 构造深度成分字典用来指导人脸复原(即针对左眼、右眼、鼻、嘴四个组成成分构造引导字典)
- 构造DFT block,这个block利用CAdaIN和confidence score从字典中获取信息并指导当前人脸的复原
-
Problem Statement
Method(s)
1. 构造离线字典

概念定义:component, 成分/组成成分,文章中其实就是指左眼、右眼、鼻、嘴
在数据集FFHQ的基础上,用DeepPose和Face++获得表情和姿势,根据这个分布从7K张数据集中挑1K张出来构造字典。用训练好的VggFace提取不同尺度下的特征,用dlib获得不同尺度下的人脸关键点,这两者加上RoIAlign方法就可以把同一个组成成分采样到同样的尺寸上,获得很多张同样大小的左右眼嘴鼻的特征图。之后再针对每一种组成成分,使用K-means聚类,K取值实际为512。
这样一通操作下来,相当于获得了四个尺度下,四个成分的字典。
(补充:关于字典的结构。 比如scale_1下,左眼的维度是 (512, 128, 40, 40),512是类别数量,1284040是后续会使用的字典维度,128是通道数,40*40是左眼的特征图大小)2. DFT Block
2.1. CAdaIN
全称为component AdaIN,用来构造每个组成成分的AdaIN。adaIN还挺基础的,stylegan里面也用到了(stylegan里面叫调制参数/风格),简单来说就是通过控制 output = scale * input + shift 里的(scale, shift)参数获得自己想要的效果。本文中,input由字典获得,(scale, shift)参数由输入特征获得,最后组合成挺复杂一式子:
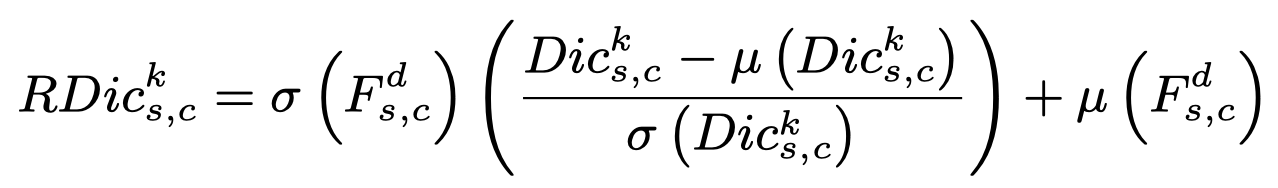
式子复杂,原理就是还是AdaIN的知识。从input component F中获得方差和均值,即σ和μ,从字典Dic里获得归一化后的input。这样,我们就能获得RDic,全称是Re-normed dictionaries。2.2 Feature Match
经过2.1,我们现在手上有俩东西:input component feature F(输入的成分特征),RDic(根据输入re-norm后的字典信息)。接下来需要衡量字典每个类别和输入的相似性,从而选择字典中和输入图像最匹配的类别。
相似性用的内积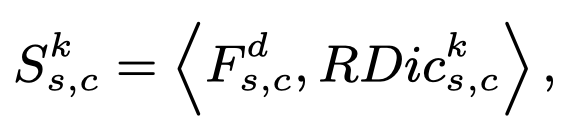 ,F和第K类特征有相同维度,因此内积操作也可以看作对RDic做bias = 0,weight = F的卷积操作。算完后挑出相似度最高的那个类别,记作RDic。这个RDic后续才会被使用到。
,F和第K类特征有相同维度,因此内积操作也可以看作对RDic做bias = 0,weight = F的卷积操作。算完后挑出相似度最高的那个类别,记作RDic。这个RDic后续才会被使用到。
2.3 Confidence Score
不同的输入图像对字典的依赖程度不高。如果图像本身质量还不错,其实是不怎么需要字典信息的,质量比较差的图像对字典的信息比较依赖。基于这一现象,作者引入了confidence score。confidence score是根据RDic*和F的残差得到的,得到后用来重新调整输入特征:
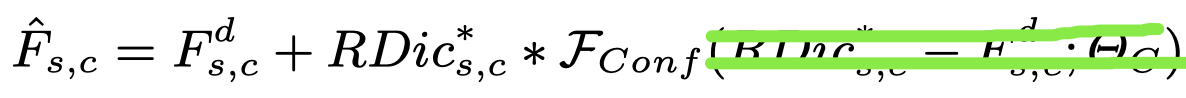 (把我认为会干扰的表达信息抹掉了)
(把我认为会干扰的表达信息抹掉了)
2.4 Reverse RoIAlign
现在每个成分的特征图都已经处理完毕,还需要把它放回原先的特征图上去,这样有助于背景等特征的保持和复原。放不是单纯的复制粘贴,还要考虑和其它部分的和谐程度,因此作者提出了SFT层,具体操作如下:
F通过reverse RoIAlign获得F^(特征缩放到原来的尺度上)
- 用两层卷积从F^获得alpha和beta
- 用仿射变换调整F^:
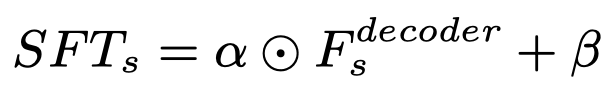
3. 损失函数
重建损失 + adversarial loss
重建损失 由 pixel loss(MSE) + perceptual loss构成
adversarial loss用的是多尺度判别器,判别网络用的是SNGAN(我也用的这个,里面有spectral normalization,训练会更稳定)。

Evaluation
评价标准:PSNR、SSIM、LPIPS
数据构造方式:
基于FFHQ,
超参:没啥特别的



Criticism
FFHQ里黄种人少,如果我想用的话,需要依据黄种人的数据去重新构造字典,不能直接使用作者提供的checkpoint
Code
字典内容是什么
字典直接从保存好的checkpoint读取。读取后,整个字典由四个小字典组成,对应了四个尺寸
- Dict_256
- Dict_128
- Dict_64
- Dict_32
每个字典中又有四个关键字:left_eye, right_eye, nose, mouth,每个关键字对应的数据会被排列成(512, channel, size, size)的大小,这儿的channel和size都是预设好的。
网络的细节实现
这个代码质量还是很高的,看起来舒服。文章的精华部分主要浏览networks.py中UNetDictFace的Forward函数、StyledUpBlock函数、adaptive_instance_normalization_4D函数(这个函数其实就是CAdaIN的内容)。我将其中重要的代码摘出来写注释以供学习
class UNetDictFace(nn.Module):def __init__(self, ngf=64, dictionary_path='./DictionaryCenter512'):super().__init__()# 获取字典中的特征并进行reshape操作self.Dict_256 = ...self.Dict_128 = ...self.Dict_64 = ...self.Dict_32 = ...# 定义了网络小模块self.le_256 = AttentionBlock(128) # 很简单的结构算尺寸256下左眼的confidence_scoreself.MSDilate = MSDilateBlock(ngf*8, dilation = [4,3,2,1]) # 用膨胀卷积定义了个类似resblock结构self.up0 = StyledUpBlock(ngf*8,ngf*8) # 拿到DFT block中处理好的字典信息应该怎么做,这儿文章中没细讲,但其实也是用了一个类似AdaIN的结构,将处理好的字典信息作为style,获得scale和shiftdef forward(self,input, part_locations):""" 以下均为DGF Block的内容 """# 提取人脸信息VggFeatures = self.VggExtract(input) # VggFeatures里包含四个尺寸下的输入人脸特征for 某个尺寸:cur_feature = VggFeatures[i] # 当前的输入特征update_feature = cur_feature.clone() #* 0 # 用来存放更新后的特征# 获取字典信息,这里只以左眼为例LE_Dict_feature = dicts_feature['left_eye'].to(input)# 获取左眼在当前尺寸下的位置le_location = (part_locations[0][b] // (512/f_size)).int()# 获取输入图像左眼的特征图并RoIAlignLE_feature = cur_feature[:,:,le_location[1]:le_location[3],le_location[0]:le_location[2]].clone()LE_feature_resize = F.interpolate(LE_feature,(LE_Dict_feature.size(2),LE_Dict_feature.size(3)),mode='bilinear',align_corners=False)# CAdaINLE_Dict_feature_norm = adaptive_instance_normalization_4D(LE_Dict_feature, LE_feature_resize) # 从输入特征中获得scale和shift,将dic特征作为input,得到Re-norm后的Dict# 算相似度并找到相似度最高的那个字典特征LE_score = F.conv2d(LE_feature_resize, LE_Dict_feature_norm) # 用卷积算相似度LE_score = F.softmax(LE_score.view(-1),dim=0)LE_index = torch.argmax(LE_score) # 找字典中和输入相似度最高的类别LE_Swap_feature = F.interpolate(LE_Dict_feature_norm[LE_index:LE_index+1], (LE_feature.size(2), LE_feature.size(3))) # 找字典中和输入相似度最高的特征# 算confidence scoreLE_Attention = getattr(self, 'le_'+str(f_size))(LE_Swap_feature-LE_feature)LE_Att_feature = LE_Attention * LE_Swap_feature# 将字典中处理好的特征贴到update_featureupdate_feature[:,:,le_location[1]:le_location[3],le_location[0]:le_location[2]] = LE_Att_feature + LE_feature # 右边的+实际就是confidence score那一节的内容""" DFT Block的内容到此结束 """""" 剩下就是类似UNet的网络主体结构 """fea_vgg = self.MSDilate(VggFeatures[3]) # 理解成简单的ResBlock即可fea_up0 = self.up0(fea_vgg, UpdateVggFeatures[3]) # 和__init__中的结构对应一下,一种使用AdaIN的上采样结构fea_up1 = self.up1( fea_up0, UpdateVggFeatures[2]) #fea_up2 = self.up2(fea_up1, UpdateVggFeatures[1]) #fea_up3 = self.up3(fea_up2, UpdateVggFeatures[0]) #output = self.up4(fea_up3)return output

若有收获,就点个赞吧
0 人点赞
