- Paper : A Style-Based Generator Architecture for Generative Adversarial Networks
- Code : StyleGAN — Official TensorFlow Implementation
- Data : The FFHQ dataset
Note_StyleGAN.pdf
2020.6.8:看styleGAN2时候发现好多细节没看懂,所以回头看styleGAN,这回精读论文
Abstract
作者从网格迁移文章中学习,提出了GAN的新生成结构。新结构自动学习,无监督地分离高级特征、实现生成图像中特征的随机变化。它允许直观的、特定尺寸的合成控制。
为了量化插值质量和特征解缠,作者提出两个新的自动化方便可适用于任何生成结构。
最后,作者介绍了一个新的、区别度大的高质量人脸数据集。
Introduction
作者重设计了一个生成结构,能够控制图像综合生成的过程。生成器从一个可学习的常数输入开始,每一个卷积层通过latent code调整网格,因此在不同的尺寸可以直接控制图像特征的强度。有不同的noise输入网络,生成器可自动学习,无监督地分离高级特征、实现生成图像中特征的随机变化。
接着作者讨论latent code。latent space符合训练集的概率分布,导致了一定程度上的特征纠缠。使用中间的latent space脱离了这样的限制,能够实现特征解缠。由于之前用来评价latent space特征纠缠程度的标准在这里不适用,作者提出两个新的自动化标准,perceptual path length和linear separability。通过这些评价标准,作者将新的生成器和传统的生成结构做比较,作者提出的生成器拥有更线性、更解缠的变量表达。
网络结构
PDF已经尽量讲的很透彻了,但我仍然有未能理解的地方,需要配合其它资料进行阅读。(参考见图的水印)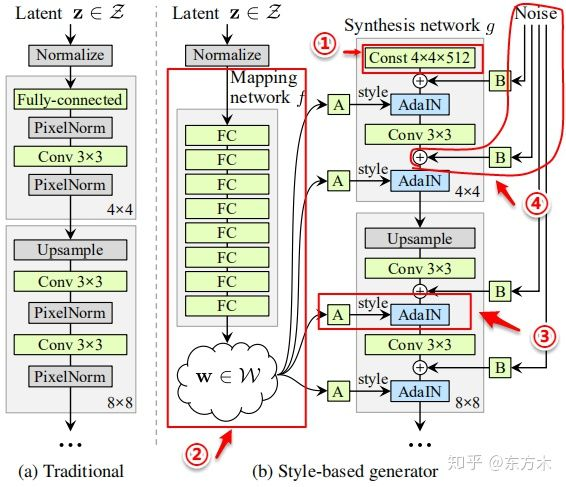
基于样式的生成器b)有18层,每个分辨率有两个卷积层(4,8,16…1024)。和传统生成网络的区别在于以下四点:
- ①移除了传统的输入(remove traditional input)
- 变成可学习的常量值(后续会加噪声随机变化生成不同结果)
- 传统的生成器a)使用latent code(随机输入)作为生成器的初始输入;StyleGAN抛弃了这种设计,让网络结果只依赖于w’而不依赖于纠缠的输入向量更容易学习。
- ②映射网络(Mapping Network)
- 8个全连接组成的网络
- 通过映射网络,该模型可以生成一个不需要跟随训练数据分布的向量w’,并且可以减少特征之间的相关性(解耦,特征分离)
- ③样式模块(style modules,AdaIN,自适应实例归一化)
- 归一化,不改变局部特征的同时影响图像的全局信息
- w’通过每个卷积层的AdaIN输入到生成器的每一层中。图中的A代表一个可学习的仿射变换。计算方法:
- ①首先每个特征图xi(feature map)独立进行归一化 。特征图中的每个值减去该特征图的均值然后除以方差
$$(x_i - \mu(x_i))/\sigma(x_i)$$ - ②一个可学习的仿射变换A(全连接层)将w转化为style中AdaIN的平移和缩放因子y =(ys,i,yb,i),
- ③结合①②,对每个特征图分别使用style中学习到的的平移和缩放因子进行尺度和平移变换。
- ①首先每个特征图xi(feature map)独立进行归一化 。特征图中的每个值减去该特征图的均值然后除以方差
- 归一化,不改变局部特征的同时影响图像的全局信息
- ④随机变化(Stohastic variation,通过加入噪声为生成器生成随机细节)
- 加入噪声,变化更丰富
- 噪声是由高斯噪声组成的单通道图像,将一个噪声图像提供给合成网络的一个特征图。在卷积之后、AdaIN之前将高斯噪声加入生成器网络中。B使用可学习的缩放参数对输入的高斯噪声进行变换,然后将噪声图像广播到所有的特征图中(分别加到每个特征图上,每个特征图对应一个可学习的scale参数)
Trick
截断技巧
考虑到训练数据的分布,低密度区域很少被表示,因此生成器很难学习该区域。通过对隐空间进行截断可以提升生成影像的平均质量,虽然会损失一些变化。对中间隐码W进行截断,迫使W接近平均值,即使隐空间趋向于高密度区域,以变换为代价来换取图像质量的改进。度量标准
感知路径程度、线性可分性
https://www.cnblogs.com/cx2016/p/12101652.html


若有收获,就点个赞吧
0 人点赞
