论文和思路理解
行人重识别(Person Re-ID)【四】:论文笔记——Beyond Part Models: Person Retrieval with Refined Part Pooling 这篇写的很棒
简单地梳理一下主要思想
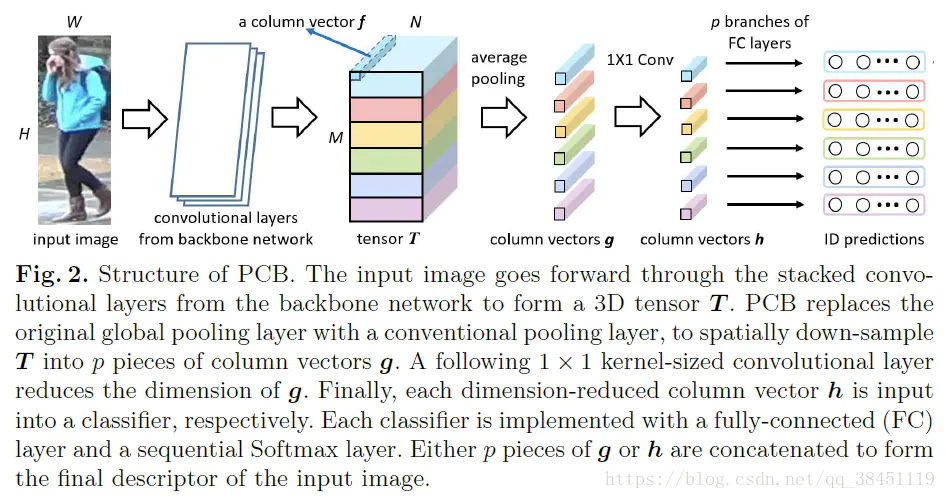
PCB(Part-based Convolutional Baseline)
image
这是个基础baseline,backbone使用的是resnet50, 到global average pooling之前完全一样。
- 假定输入是H,经过backbone之后得到三维的Tensor T
- 定义T中每个channel axis为column vectors, 即f
- 将T分成P个horizontal stripes(水平块),对p个horizontal stripes做Average pooling得到p个局部特征g
- 用1*1 conv降低g的维度到256维,为新的局部特征h
- 每个h经过一个全+分类器进行训练(分类器实质上是p个n分类的softmax, n为训练集的ID数目)
特点:减少降采样
训练:loss为交叉熵损失函数的sum(p个分类器,p个loss)
测试:串联向量g和h作为特征表示
Part内部信息不一致
这部分类似triplet loss或者像cornernet中的embedding
同一个part中的f应相似,不同part间应有差异
因此我们需要训练PCB到收敛后,测量f和g的相似程度(余弦距离),找到离每一个f最近的part,根据f的距离情况进一步改进
image
RPP(Rifined Part Pooling)
目标:解决上一模块说的要改进的东西,通过f和与其最相似的part来对齐所有f,让f回到自己属于的part去
具体做法:
- 测量f与每一个part的相似程度:

- f根据S重采样到最相似的part上
- 重复1、2直到收敛
- 用p个classifier去预测
 的值,预测公式为
的值,预测公式为
PCB部分的第三步即可用上述RPP取代,即RPP后,得到每个part对应的attention map权值,后续的降采样等步骤一致。
如何训练RPP中calssifier的权重
这个权重就是上一部分第4步中的
- 将图像等分,训练PCB至收敛
- 将T后面的Average pooling替换为一个p分类的part classifier
- 固定PCB其它层的参数,只训练part classifier至收敛
- 放开全部参数,fine tune
代码阅读
看了好几份代码,在最后检测部分都有点含糊。找到一份好像有点写清楚了,打算分析一下。
test.py代码逻辑
- 输入
- gallery_XXs:候选行人的图像库
- query_XXs:待查询输入
- gallery_XXs:候选行人的图像库
- 输出
- mAP
- CMC
- 步骤针对每一个query:
- 去gallery_labels中找同label的索引
- 去gallery_cams中找同cam的索引
- postive_index: 找到不同cams下同一label的索引,即为正样本的索引(标注信息)
- junk_index: 找到label==-1及同一cam下同一label的索引,即为无效的索引
- sufficient_index: 找到所有有效的索引(所有index-junk_index)
- y_true: 得到sufficient_index中的每一个图像是否是正样本(标注信息)
- y_score: 预测得到的sufficient_index中的每一个的分值(预测信息)
-
代码知识
setdiff1d(ar1, ar2, assume_unique=False)1.功能:找到2个数组中集合元素的差异。2.返回值:在ar1中但不在ar2中的已排序的唯一值。3.参数:- ar1:array_like 输入数组。
- ar2:array_like 输入比较数组。
- assume_unique:bool。如果为True,则假定输入数组是唯一的,即可以加快计算速度。 默认值为False。
- ar1:array_like 输入数组。
numpy.intersect1d
返回两个数组的交集,已排序的唯一值numpy.append(arr,values,axis=None)
就是往numpy数组中加数元素。和list.append()的区别在于:list.append()只能添加一个元素,而numpy.append()可以添加多个元素,Append values to the end of an array.numpy.in1d(ar1, ar2, assume_unique=False, invert=False)
Test whether each element of a 1-D array is also present in a second array.
Returns a boolean array the same length as ar1 that is True where an element of ar1 is in ar2 and False otherwise.sklearn.metrics.average_precision_score(y_true, y_score, average=’macro’, pos_label=1, sample_weight=None)source
Compute average precision (AP) from prediction scores.
AP summarizes a precision-recall curve as the weighted mean of precisions achieved at each threshold, with the increase in recall from the previous threshold used as the weight:
where and
and  are the precision and recall at the nth threshold.
are the precision and recall at the nth threshold.
Retures: average_precision(float)- CMC曲线
假如我们训练好了一个3分类的模型,分别为类别c1,c2,c3。每个样本输入模型后会得到对应的3个匹配分数,匹配分数最高的那个类别即是预测的类别数。

源码分析
# ---------------------- Evaluation ----------------------# query:待查询输入,gallery:候选行人框# query和gallery的features, labels, cams均为已知信息,features是通过网络提取到的特征def evaluate(query_features, query_labels, query_cams, gallery_features, gallery_labels, gallery_cams):"""Evaluate the CMC and mAPArguments:query_features {np.ndarray of size NxC} -- Features of probe imagesquery_labels {np.ndarray of query size N} -- Labels of probe imagesquery_cams {np.ndarray of query size N} -- Cameras of probe imagesgallery_features {np.ndarray of size N'xC} -- Features of gallery imagesgallery_labels {np.ndarray of gallery size N'} -- Lables of gallery imagesgallery_cams {np.ndarray of gallery size N'} -- Cameras of gallery imagesReturns:(torch.IntTensor, float) -- CMC list, mAP"""CMC = torch.IntTensor(len(gallery_labels)).zero_()AP = 0sorted_index_list, sorted_y_true_list, junk_index_list = [], [], []for i in range(len(query_labels)):# 对每一个要查询的图像,获取一下信息query_feature = query_features[i]query_label = query_labels[i]query_cam = query_cams[i]# Prediction score# 对要查询的图像获取一个score,但这个score为什么能这么获取没搞明白score = np.dot(gallery_features, query_feature)# 去gallery_labels里找和query_label相对应的数据索引(即找到这些数据在哪儿)match_query_index = np.argwhere(gallery_labels == query_label)# 去gallery_cams里找和query_cam相对应的数据索引(即找到这些数据在哪儿)same_camera_index = np.argwhere(gallery_cams == query_cam)# Positive index is the matched indexs at different camera i.e. the desired result# 在match_query_index中但不在same_camera_index中的已排序的唯一值positive_index = np.setdiff1d(match_query_index, same_camera_index, assume_unique=True)# Junk index is the indexs at the same camera or the unlabeled image# Junk index是同一camera下同一label的照片或未标注的图像,不要的索引junk_index = np.append(np.argwhere(gallery_labels == -1),np.intersect1d(match_query_index, same_camera_index)) # .flatten()index = np.arange(len(gallery_labels))# Remove all the junk indexs# 从gallery中去掉junk index的元素sufficient_index = np.setdiff1d(index, junk_index)# compute AP# y_true返回一个结果,判断sufficient_index中的每一个元素是否在positive_index中y_true = np.in1d(sufficient_index, positive_index)# y_score是根据特征算到的结果y_score = score[sufficient_index]# 用库函数算APAP += average_precision_score(y_true, y_score)# Compute CMC# Sort the sufficient index by their scores, from large to small# sorted_index: y_score从大到小排序后得到的索引sorted_index = np.argsort(y_score)[::-1]# 与sorted_index排序一致的正负样本真实情况sorted_y_true = y_true[sorted_index]# 得知sorted_y_true中哪些是正样本match_index = np.argwhere(sorted_y_true == True)# 累计CMC的值if match_index.size > 0:first_match_index = match_index.flatten()[0]CMC[first_match_index:] += 1# keep with junk index, for using the index to show the img from dataloaderall_sorted_index = np.argsort(score)[::-1]all_y_true = np.in1d(index, match_query_index)all_sorted_y_true = all_y_true[all_sorted_index]sorted_index_list.append(all_sorted_index)sorted_y_true_list.append(all_sorted_y_true)junk_index_list.append(junk_index)CMC = CMC.float()CMC = CMC / len(query_labels) * 100 # average CMCmAP = AP / len(query_labels) * 100return CMC, mAP, (sorted_index_list, sorted_y_true_list, junk_index_list)

若有收获,就点个赞吧
0 人点赞
