Title
FormNet: Formatted Learning for Image Restoration
代码:https://bitbucket.org/JianboJiao/formnet
Summary
作者不直接学习退化图像到干净图像的映射,而是强迫网络去学残差(退化图像和干净图像间的差距),用Formatting layer去规范化这个残差使网络更易学。损失函数中用了梯度损失(sobel损失)。
Problem Statement
先前的很多图像复原工作都是Task-specific的,作者想实现一个优秀的适应多场景的图像复原网络
Method(s)
Ic: 损坏图像,可理解为input image
I: 干净的图像,可理解为target image
最开始的尝试:DiffResNet
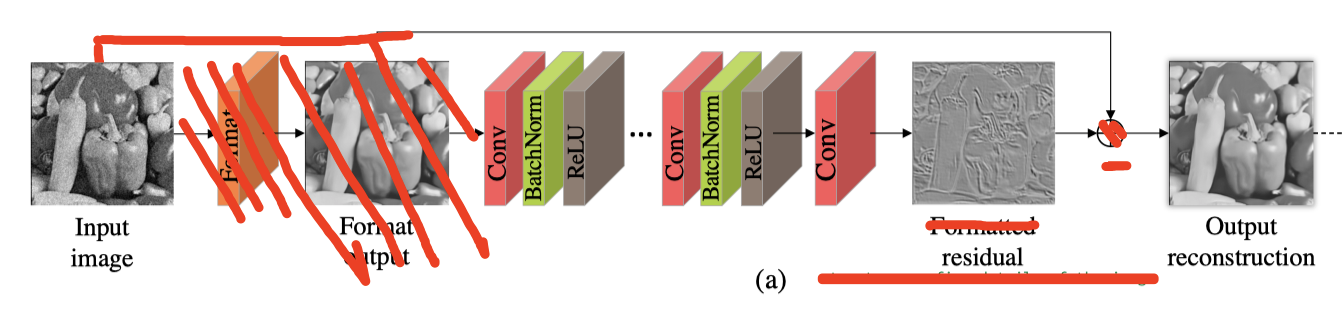
(一个粗浅的示意图,学差异,期望用损坏图像-差异获得目标图像)
传统深度学习算法直接学损坏图像和干净图像间的映射,容易导致梯度消失或下降。
因此作者认为可以学稀疏的残差映射。hat(C) = f(Ic),即输入是损坏图像,输出是残差(即作者期望学习的是损坏图像和目标损坏间的差异)(输出如Fig2(b)所示,包括Noise和高频结构区域)。
损失函数为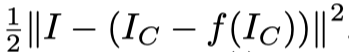
学difference效果更好收敛更快,这样使用DiffResNet的作用其实就相当于一个低通滤波器,保留低频信息,过滤掉高频伪影(如噪声),但也因此过滤掉了结构化信息(结构、边缘),而这些高频结构区域(如Fig2(c))是很难修复的。
学习结构化残差:FormResNet
相比DiffResNet,增加了residual formatting layer(Fig4中的橙色部分),这个format操作也可以理解成损坏图像的预处理。
这样一来,相当于DiffResNet学习残差,即损坏图像和干净图像间差异,而FormResNet学习改进后的残差,空间上更具有结构感和边缘信息,即预处理后的损坏图像和干净图像间的差异。因此,这个预处理步骤的作用在于formats the residual。
预处理步骤用传统算法(BM3D)或CNN网络均可。经过预处理后,高频损坏被移除,网络更侧重于学习图像细节,而非随机分布的噪声,如Fig2(d)所示。这样一来FormResNet就兼具了高通滤波器和低通滤波器的优点,其网络结构如下图所示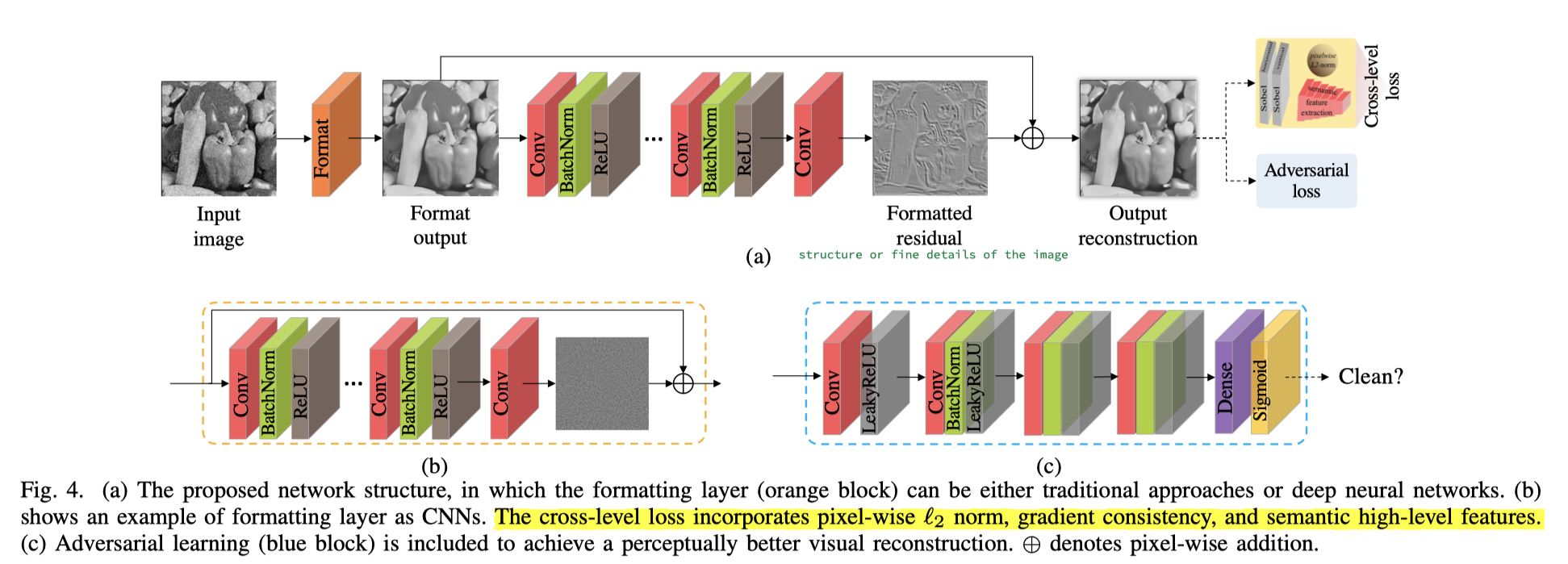
PS:看论文的时候这个递归表达式困扰了我非常久,明明其它都理解了,这段就感觉究极难懂。后来去看了代码,感觉这个表达式有误导人的嫌疑,就是代码逻辑很简单,就是把Fig4(b)中的部分用在(a)中橙色块上。
Adversarial Learning
简单来说就是用了GAN的思想,有个判别器,即图中的蓝色部分。这块儿没啥好说的。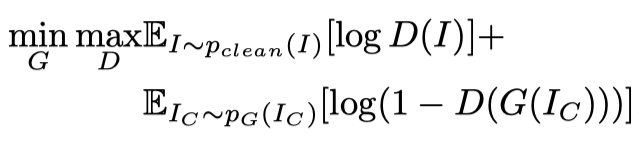
Cross-level Loss
思想是既考虑pixel-level的损失(作者用的是L2损失),也考虑high-level的语义损失。
pixel-level:普通的L2损失
high-level:普通的vgg loss(vgg16的relu2_2层特征图算L2差距)
gradient domain:这个第一次见,用了两个Sobel layers,得到竖直方向和水平方向上的梯度(具体代码我放到Code章节了)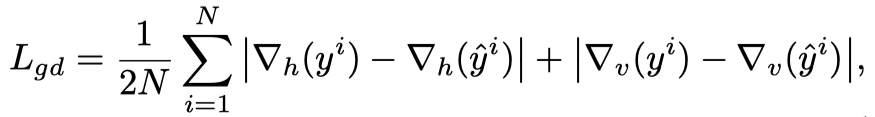
Criticism
把一些很常用简单的东西写得很复杂高端,真正的亮点有两个:
- 网络结构的设计思路很棒
- sobel loss这个之前没有接触过,觉得比我自己使用的高频LOSS要好(感觉sobel loss会比高频loss在清晰度上更好)
Code
Sobel算子的使用方法(或者可以说gradient domain loss的写法)
# Sobel loss--a=np.array([[1,0,-1],[2,0,-2],[1,0,-1]])SobelX=nn.Conv2d(1,1,3,1,1,bias=False)SobelX.weight=nn.Parameter(torch.from_numpy(a).float().unsqueeze(0).unsqueeze(0))b=np.array([[1,2,1],[0,0,0],[-1,-2,-1]])SobelY=nn.Conv2d(1,1,3,1,1,bias=False)SobelY.weight=nn.Parameter(torch.from_numpy(b).float().unsqueeze(0).unsqueeze(0))# 这里就很奇怪,不懂为啥要自己写,不就是torch.nn.L1Loss的内容么# torch.nn.L1Loss: https://pytorch.org/docs/stable/generated/torch.nn.L1Loss.html#l1lossdef critL1(input,target):return torch.sum(torch.abs(input-target))/input.data.nelement()loss_Sobel=critL1(SobelX(out_train),SobelX(img_train))+\critL1(SobelY(out_train),SobelY(img_train))loss_Sobel=loss_Sobel / 2

若有收获,就点个赞吧
0 人点赞
