Title
Deep High-Resolution Representation Learning for Visual Recognition
代码:https://github.com/HRNet
TPAMI,2020,微软,Jingdong Wang(王井东)
Summary
作者放弃了encoder + decoder的类似UNet结构,利用多尺度特征并行处理+多尺度特征融合机制,打造了一个更强的backbone,在人体姿势估计、语义分割、目标检测等一些方面达到了sota。
Contribution(s)
- 多尺度特征并行处理,而非序列化处理
-
Problem Statement
high-resolution特征对于位置敏感的视觉任务是很重要的,比如人体姿势估计,语义分割,物体检测等。
现有的SOTA框架都是采用encoder + decoder + skip_connection模式,如下图所示:
作者提出了一个新框架high-resolution network(HRNet),相比之前的框架,它的优势在于语义信息更丰富,位置敏感,maintain high-resolution representations。它有广泛的应用,在人体姿势估计、语义分割、物体检测都是更强有力的backbone。Method(s)
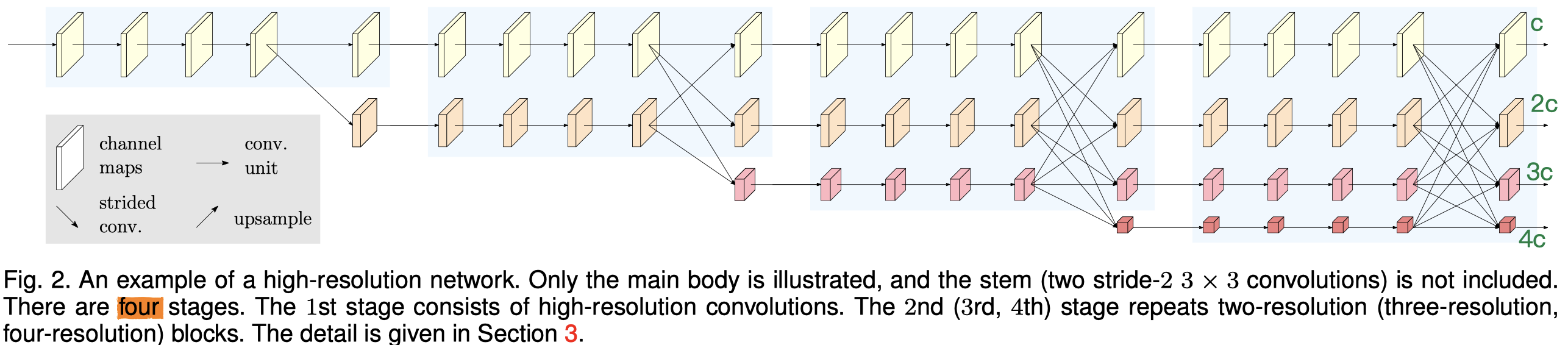
作者提出了两种HRNet HRNetV1,只输出高分辨率特征 ,可应用在人体姿势估计
- HRNetV2,会将所有尺寸的特征融合,可应用在语义分割
- HRNetV2还可引申出HRNetV2p,拥有多尺度的特征表达,在目标检测等方面达到SOTA
作者首先通过2个stride=2的3×3卷积,将输入图像的尺寸直接降到1/4,直接main body都是在1/4上处理的。
main body包含三个要素:(1)并行的多尺度卷积,(2)重复的多尺度特征融合,(3)多尺度特征的最终输出(文中称之为representation head,下文我也会这么称呼)
Parallel Multi-Resolution Convolutions
作者采用了4个stage的形式,每过一个stage,就会加入一个新的尺寸特征并行处理。图里已经画得很清楚了
Repeated Multi-Resolution Fusions
这块的设计主要是为了特征交流。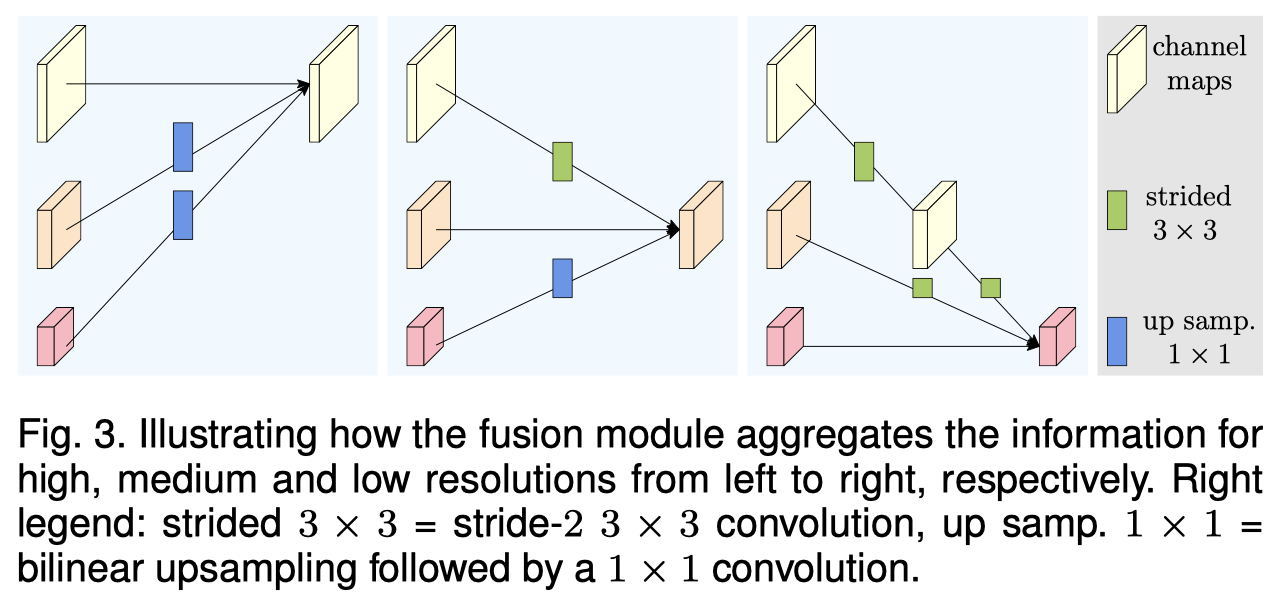
这张图体现了所有和新尺度生成、多尺度融合的操作。
对于编号为R1,R2,R3的三个输入,我想得到R^o
尺寸相同的输入特征就原样输出
尺寸不同的输入特征就对应地做上采样(bilinear+1×1 conv)/下采样(stride=2的3×3 conv)
Representation Head
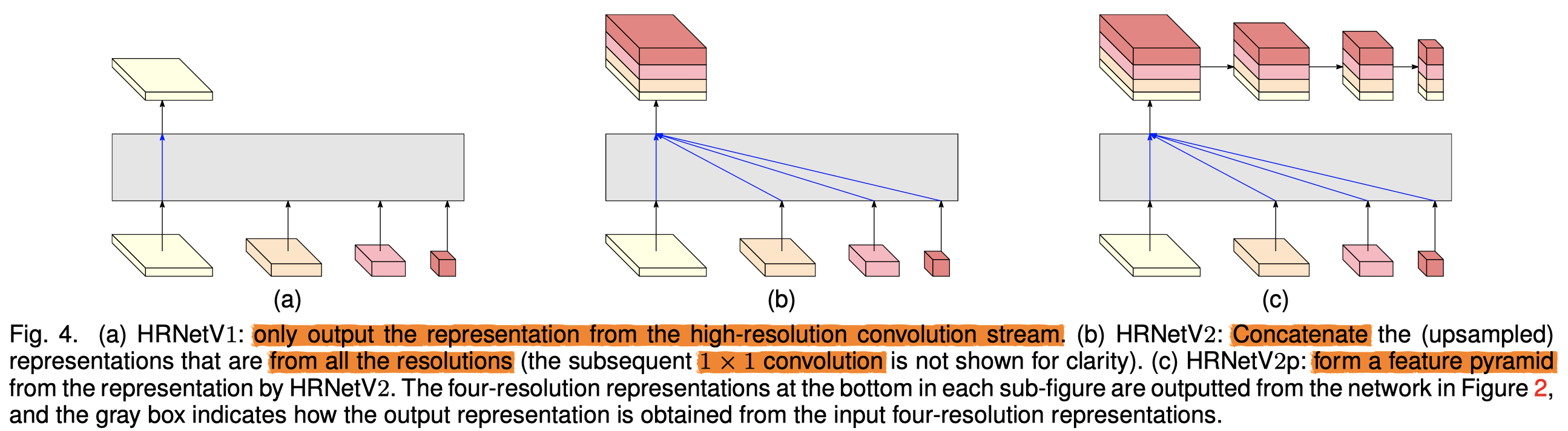
作者提出了三种representation head,分别对应上文提到的HRNetV1, HRNetV2, HRNetV2p,
Evaluation
人体姿势估计
4个V100的瞳,HRNet-W32训了60个小时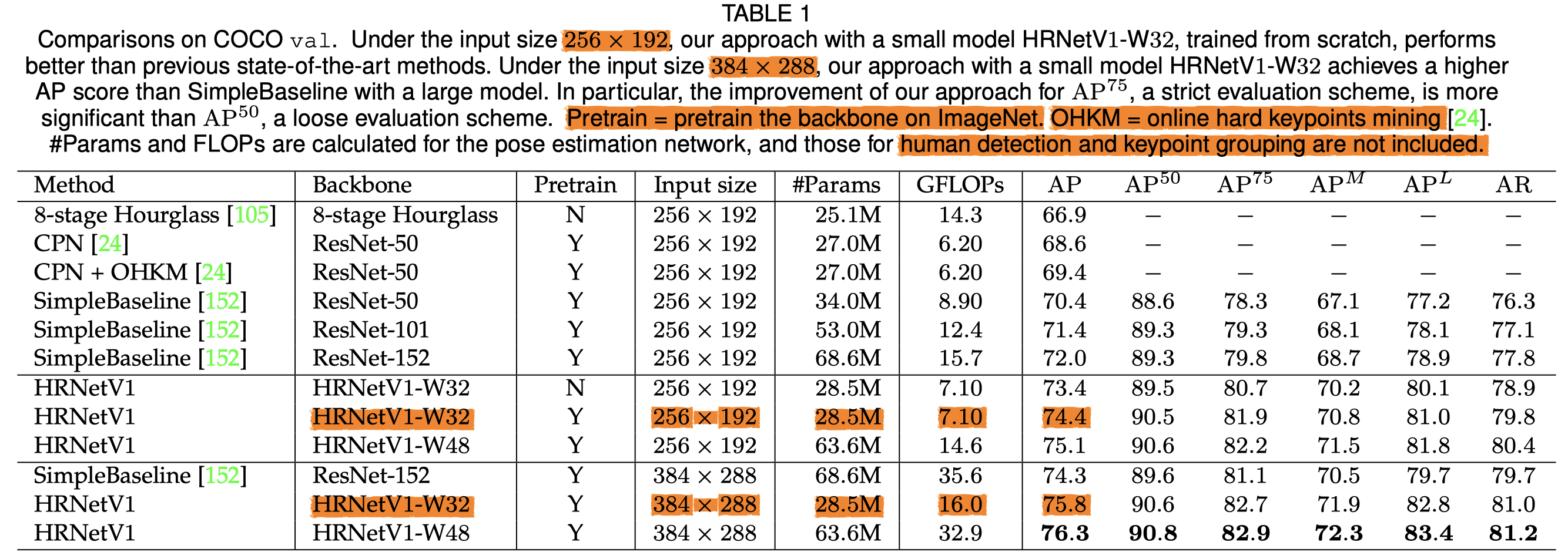
语义分割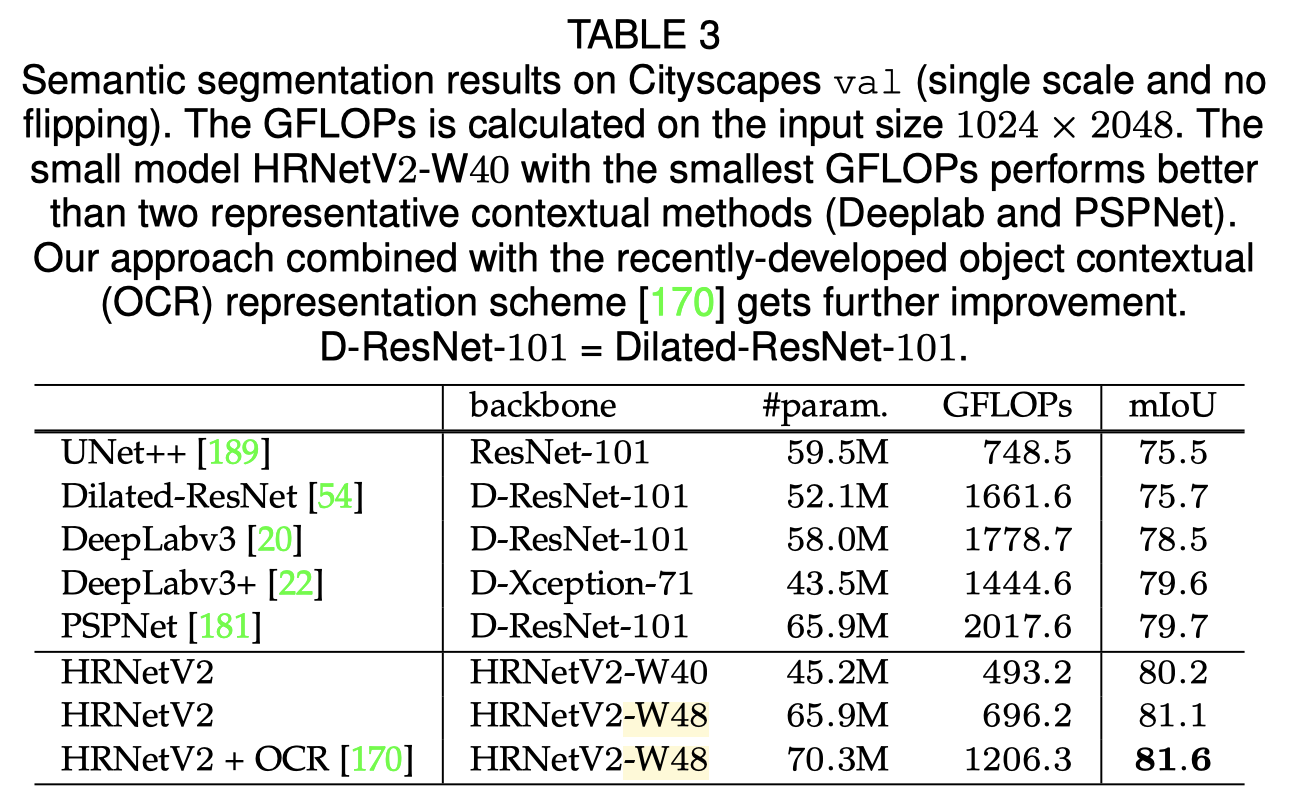
目标检测
这是GFLOPs和params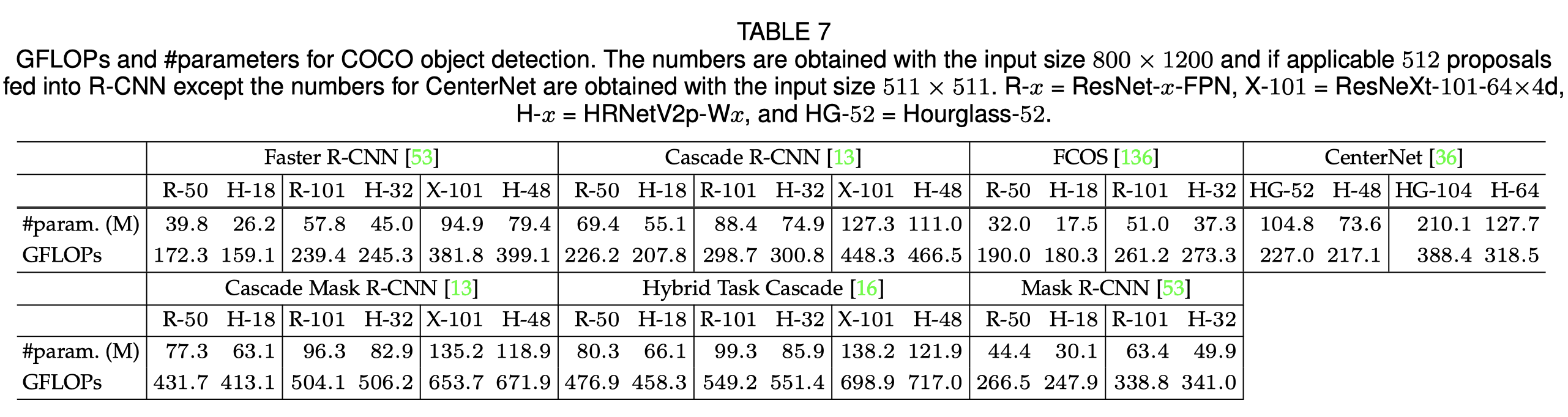
这是效果,对小目标检测更好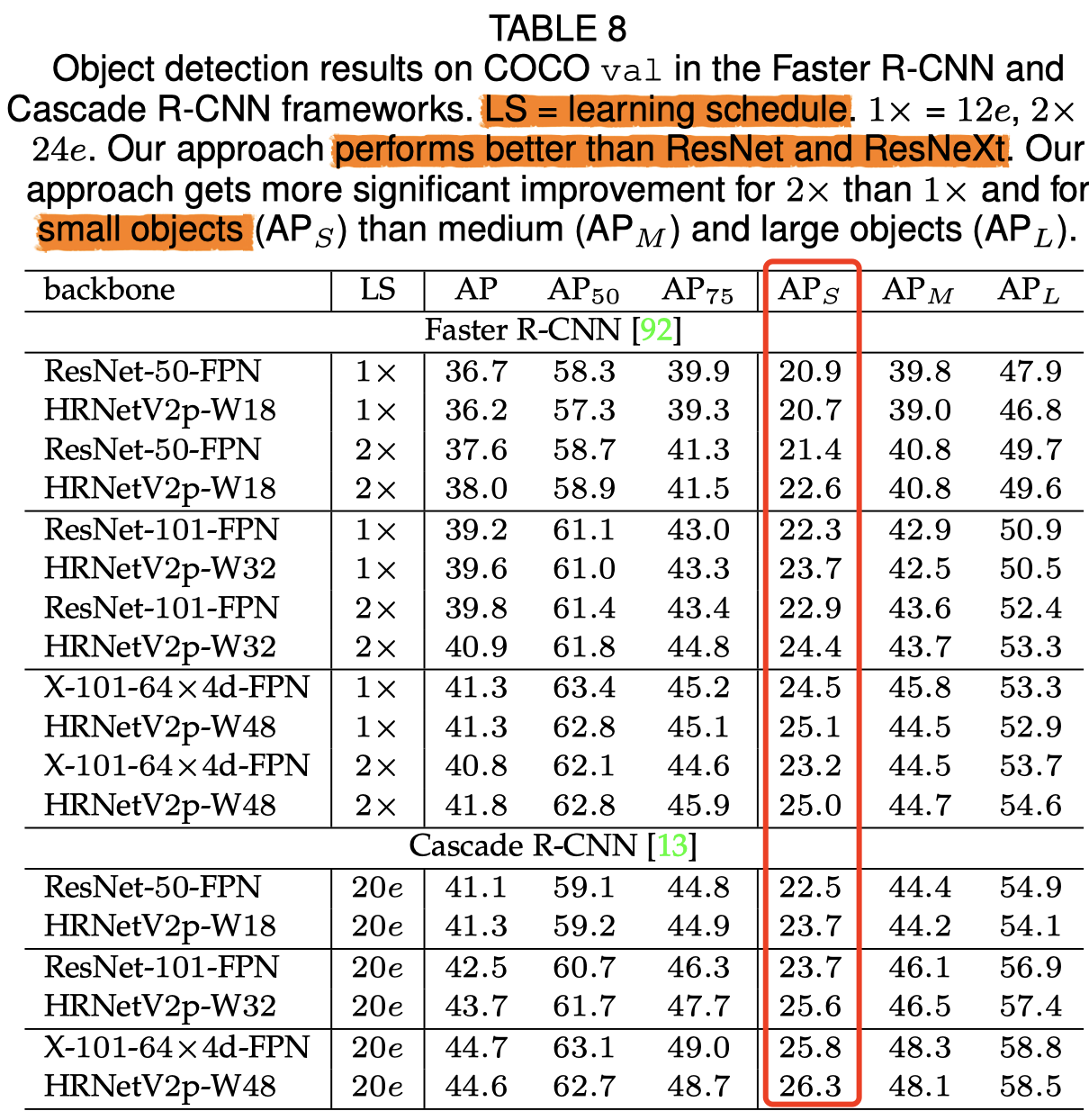
Criticism
文中有很明显的表述错误,像3.3节对于图4的文字描述有不匹配的地方。
这篇文章其实也是加强多尺度特征交流,和MIRNet很像,类似的还有很多文章。
总的来说,这篇文章是有独到之处的,实验也相当充分,是篇好文章。应用在我的项目中,涉及到计算量,我会在越大的尺寸上用越少的卷积,和文中相反。

若有收获,就点个赞吧
0 人点赞
