Title
RepVGG: Making VGG-style ConvNets Great Again
代码:https://github.com/DingXiaoH/RepVGG
PS:重参数化是一个无痛涨点的大趋势~有很多神奇的应用,比如我的项目中用了sobel + conv的形式。
和RepVGG类似的文章还有ACNet
Notes
作者的博客写得很好
https://zhuanlan.zhihu.com/p/344324470
总结下来是:
- train时的架构和inference的架构不是同一个(解耦训练时和推理时架构)
- train时使用多分支模型(类似inception,对于x,用不同的卷积核得到不同感受野的信息再相加)
- inference时,将train时的33卷积核,11卷积核和恒等映射和其后的BN推理为一个3*3卷积核

重参数化的实现细节
Code
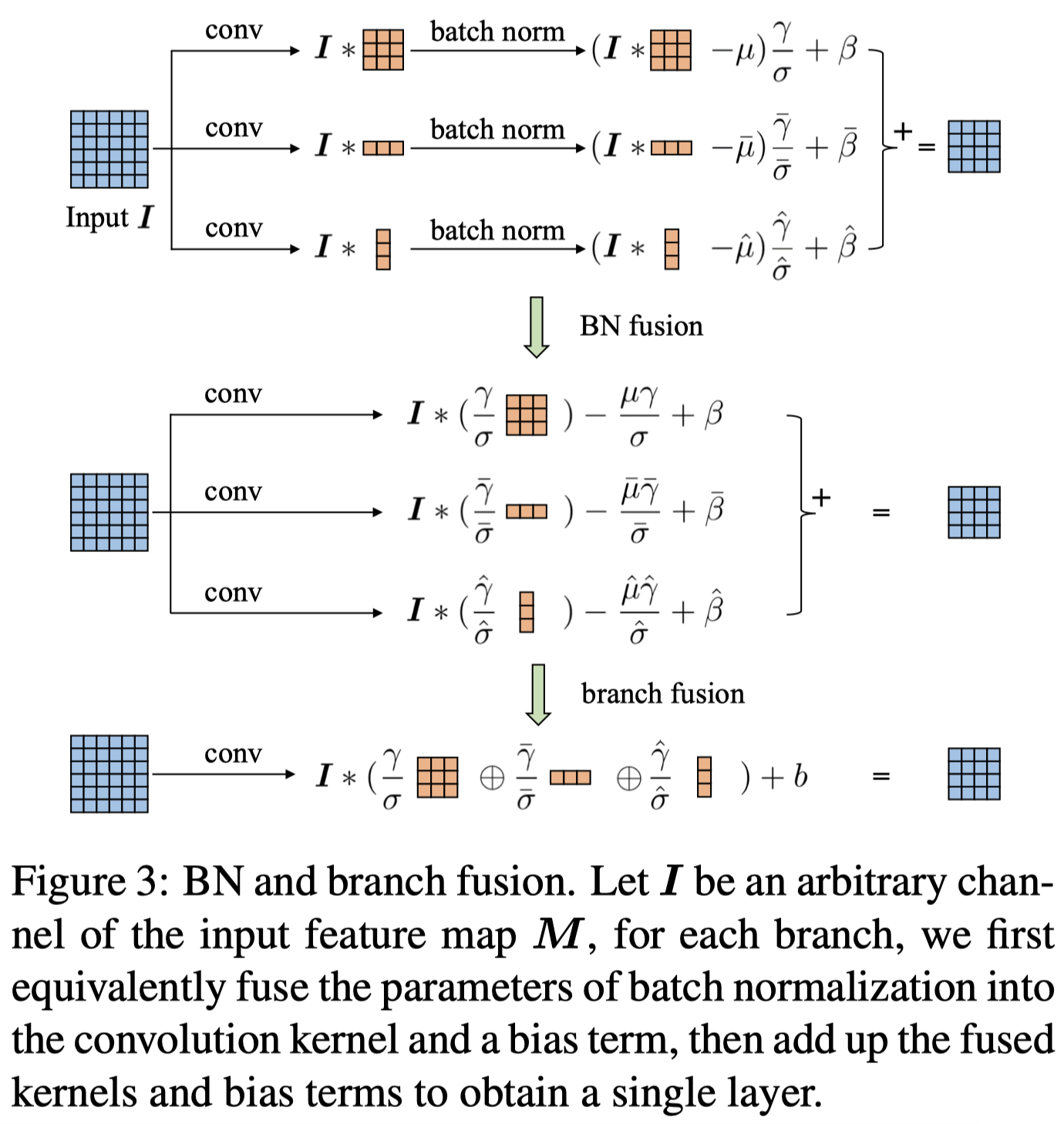
网络结构
在训练时,如上图(B)所示,输出特征是由三个分支的特征相加得到的
https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py line33
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else Noneself.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)return nn.ReLU()(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
在推断时,这三个分支的卷积会合并成一个
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)return nn.ReLU()(self.rbr_reparam(inputs))
参数合并
11卷积的权重通过填0变成33卷积的权重
# 1*1卷积通过填0变成3*3卷积def _pad_1x1_to_3x3_tensor(self, kernel1x1):if kernel1x1 is None:return 0else:return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
将conv + bn的数据取出来变成3*3卷积的权重和bias
def _fuse_bn_tensor(self, branch):if branch is None:return 0, 0if isinstance(branch, nn.Sequential):kernel = branch.conv.weightrunning_mean = branch.bn.running_meanrunning_var = branch.bn.running_vargamma = branch.bn.weightbeta = branch.bn.biaseps = branch.bn.epselse:assert isinstance(branch, nn.BatchNorm2d)if not hasattr(self, 'id_tensor'):input_dim = self.in_channels // self.groupskernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)for i in range(self.in_channels):kernel_value[i, i % input_dim, 1, 1] = 1self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)kernel = self.id_tensorrunning_mean = branch.running_meanrunning_var = branch.running_vargamma = branch.weightbeta = branch.biaseps = branch.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta - running_mean * gamma / std
先取出conv的weight(如果没有conv,就直接置0), 再取出bn的参数
新卷积核的权重:
原conv的weight (gamma/std)
新卷积核的偏置:
beta - running_mean gamma/std
(上面两个公式还挺好理解的,把BN的inference公式写一遍就能得到)
三分支合一分支,re-parameterization
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')

若有收获,就点个赞吧
0 人点赞
