Title
Coordinate Attention for Efficient Mobile Network Design
代码:https://github.com/Andrew-Qibin/CoordAttention
National University of Singapore
没好好看,但觉得这个适应性挺广的,2021年的CVPR,记录一下关键结构
Summary
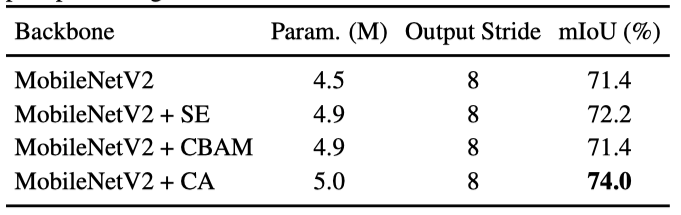
提出了一个轻量化的注意力机制coordinate attention,在通道信息的基础上融入了空间位置上的信息,显著提高了分类、检测、分割等模型的效果。
Method(s)
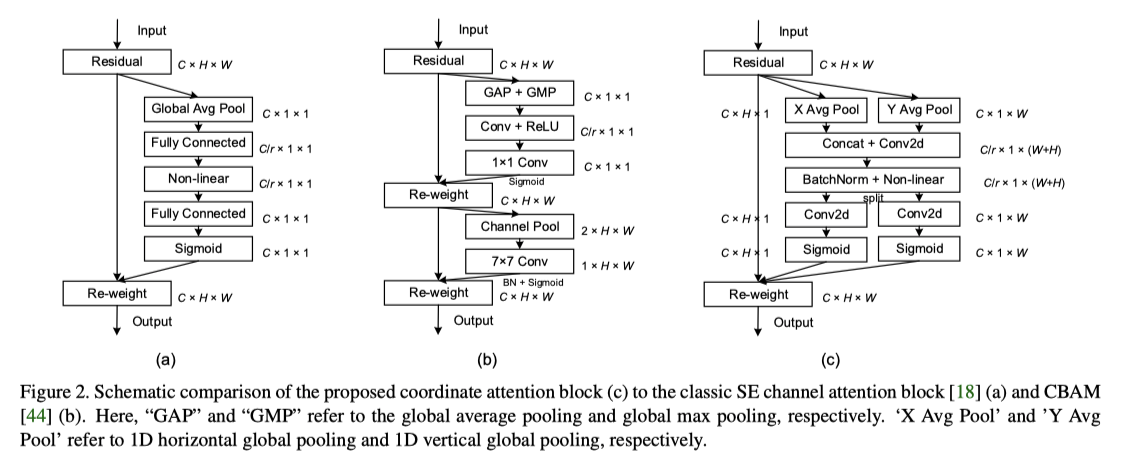
(a)是SE block中的channel attention结构
(b)是CBAM方法(一篇18年的paper,这篇paper其实也是希望空间位置+通道信息,但对于空间信息的编码上不如本文方法有优势)
(c)是本文提出的结构,和a相比关键在于它利用到了H方向和W方向的avg pool,在原有通道注意力的基础上拿到了位置注意力。
如果上图的(c)看了有疑问的话可以重点看下面这版:
可以看出,和(a)的区别主要在:H、W通道分别的avg pool以及对应的concat和split操作
Evaluation

Code
挺好理解的
class CoordAtt(nn.Module):def __init__(self, inp, oup, reduction=32):super(CoordAtt, self).__init__()self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, inp // reduction)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.act = h_swish()self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)def forward(self, x):identity = xn,c,h,w = x.size()x_h = self.pool_h(x)x_w = self.pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)y = self.conv1(y)y = self.bn1(y)y = self.act(y)x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)a_h = self.conv_h(x_h).sigmoid()a_w = self.conv_w(x_w).sigmoid()out = identity * a_w * a_hreturn out

若有收获,就点个赞吧
0 人点赞
