Title
Learning Enriched Features for Real Image Restoration and Enhancement
代码:https://github.com/swz30/MIRNet
google + UAE, ECCV2020
Summary
作者提出了一个网络,兼顾了全分辨率下的细节特征信息和下采样后的语义信息,通过attention和信息交流的方式获得较好的图像生成效果,在去噪、超分、增强等方面都取得了SOTA结果。
Contribution(s)
- 一种特征提取模型,既保留高分辨率特征,又能融合多尺度下的语义信息
- 一种新的融合多尺度特征的方式,即下文介绍的selective kernel feature fusion(SKFF)
- 一种可递归的残差模式设计,可以逐步分解输入图像
Problem Statement
在图像分辨率上处理得不到足够的语义信息(作者定义它为spatial precise but contextually less robust),对图像做下采样处理容易缺失空间特征信息(semantically reliable but spatially less accurate)。此外图像在不同分辨率上一般是单独处理,各分辨率上没有信息交流。这导致了生成图像无法同时保持高准确度和丰富细节。
作者希望能同时兼顾spatial details和accurate details。Method(s)

网络的几个关键元素:
1、并行的多分辨率信息流(提取更好的语义信息,且保持更精确的空间信息)
2、多分辨率信息流间的信息交换
3、基于attention对多个信息流实现特征聚合
4、双重注意力机制,同时抓取通道和空间上的纹理信息
5、残差缩放模块,用来执行上采样和下采样操作
overall pipline
给定输入图像I,维度H×W×3,网络首先使用一个卷积层提取低层特征X₀,维度H×W×C。接着,X₀经过一组递归的残差组(RRGs),产生特征Xd,维度维度H×W×C。得到Xd后用一个卷积获得残差结果R,和输入图进行相加,相加结果即最终结果。
网络优化使用的Charbonnier loss(这个Loss可以理解为高级点的L1 loss)
RRG包含了几个多尺度残差块MRB,里面即本文的重点
multi-scale residual block(MRB)
CNN需要多种尺度下的空间信息,因此作者提出MGB,期望既保留高分辨率下的空间,又能获得低分辨特征中的纹理信息。MRB包含了三个全卷积信息流,它们并行并交换信息,最终通过低分辨率特征巩固高分辨率特征。
当然,MRB中依然包含很多模块,接下来会依次讲解。
selective kernel feature fusion(SKFF)
传统的concat和sum没有足够的表达能力。MRB中使用了SKFF来非线性、自注意力地融合多尺度特征。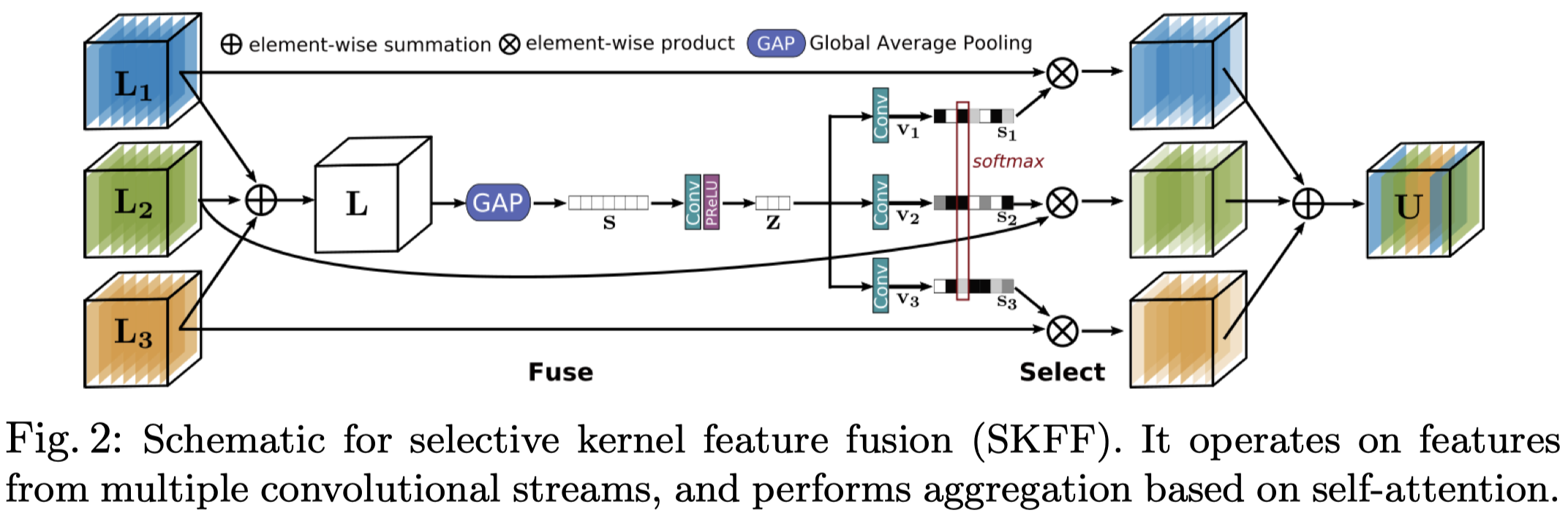
Fuse: 融合特征的过程
- L1、L2、L3是三个不同分辨率下的特征,将其相加(这儿相加的逻辑没有说,具体还需要看代码),得到L,维度H×W×C
- 使用GAP(global average pooling)将L进行空间上的压缩,得到s,维度1×1×C
- 用一个卷积+relu将s变为更紧凑的特征表达z,维度1×1×r, r=C/8
- 将z用三个并行的卷积变为三个不同尺度下的特征表达,v1, v2, v3,维度均为1×1×C
Select: 特征再校准的过程
- 对v1, v2, v3做softmax,其结果即为L1,L2, L3对应的权重
- U = s1L1 + s2L2 + s3*L3
简单的concatenation,SKFF的参数量少6倍,但结果更可信
Dual attention unit(DAU)

这是论文里的图,后来发现有个推文里重画了这张图,细节更多一些,因此也将它贴过来了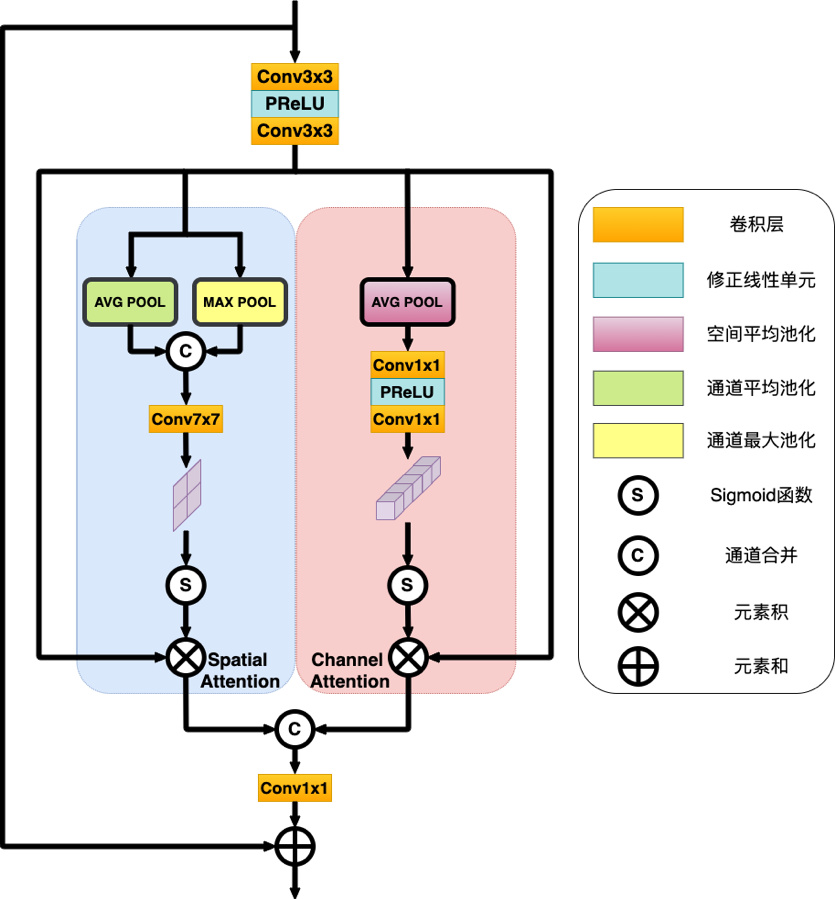
Residual resizing modules
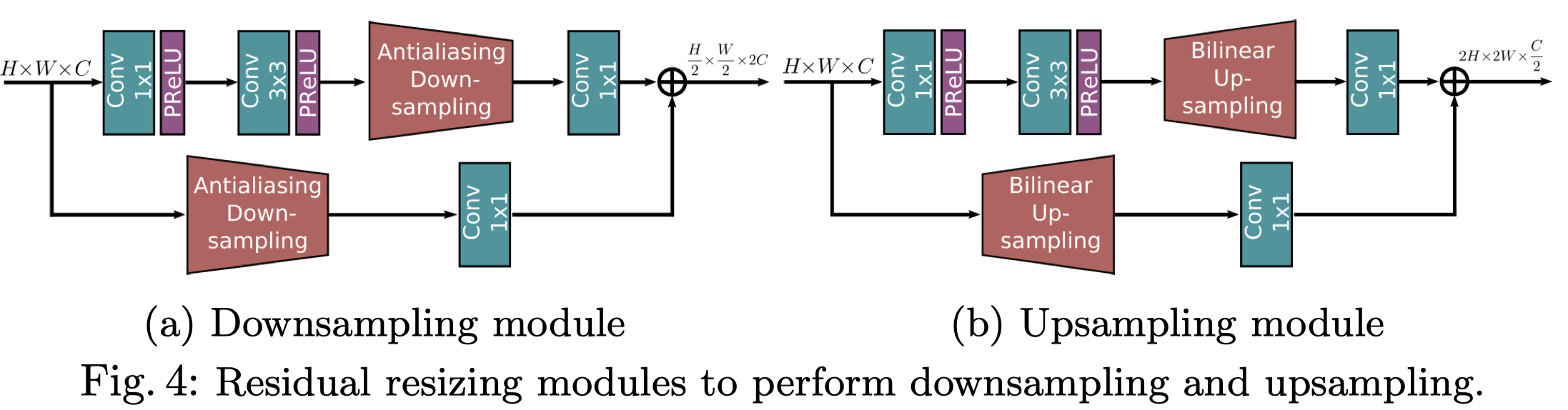
关注一下这里的Anti-aliasing Downsampling,抗锯齿下采样,去google后没有找到放在网络中的写法,看看具体怎么实现的。
答:简单来说是基于stride=2的conv做了些操作,具体内容参考论文:Zhang, R.: Making convolutional networks shift-invariant again. In: ICML (2019) 7
Evaluation
数据集
- Image denoising
- DND
- SIDD
- Super-resolution
- RealSR
- Image enhancement
- LoL
- MIT-Adobe FiveK
实验细节
3个RRG,每个RRG中包含2个MRB,每个MRB包含三个维度64, 128, 256。每个维度的信息流上包含2个DAU。
优化方法用的Adam(β1 = 0.9, β2 = 0.999), 迭代7e5次,初始学习率为2e-4
训练时采用余弦退火(cosine annealing)的方式来降低学习率,先缓慢下降,再加速下降,再缓慢下降(这个我没用过,感觉对于之前模型收敛不稳定是个很好的方法)
实验效果



Ablation studies

skip connections加不加对效果影响非常大,其实是DAU(双重注意力机制),接着是位于中间位置的SKFF
Notes
Criticism
作者在Residual resizing modules章节的内容含糊、指代不明,对整体框架的描述略有脱节。虽然我理解了,但这块的质量比不上其它块。
作者的full resolution作为branch,muti-resolution融合的思路很棒,开拓了我的视野。
DAU作为注意力机制也是有可取之处的。
总的来讲可学习的点很多,是篇好paper。
Code
作者的代码逻辑也太棒了,非常赞!
##---------- Multi-Scale Resiudal Block (MSRB/MRB) ----------class MSRB(nn.Module):def __init__(self, n_feat, height, width, stride, bias):super(MSRB, self).__init__()# height可以理解为:不同尺寸的数量,paper中即在三个尺寸上提取特征# width可以理解为:DAU的数量self.n_feat, self.height, self.width = n_feat, height, width# self.blocks是一个二维数组,维度(height, width),每个元素都是一个DAUself.blocks = nn.ModuleList([nn.ModuleList([DAU(int(n_feat*stride**i))]*width) for i in range(height)])INDEX = np.arange(0,width, 2)FEATS = [int((stride**i)*n_feat) for i in range(height)]# 下采样的倍数,分别是2, 4SCALE = [2**i for i in range(1,height)]self.last_up = nn.ModuleDict()for i in range(1,height):self.last_up.update({f'{i}': UpSample(int(n_feat*stride**i),2**i,stride)})self.down = nn.ModuleDict()self.up = nn.ModuleDict()# 下面self.down是在定义下抗锯齿下采样。它是字典形式,关键词:{feat}_{scale}, scale每/2,通道数feat就*2。# 这儿的scale不是真的scale, 2**scale表示下采样的倍数i=0SCALE.reverse()for feat in FEATS:for scale in SCALE[i:]:self.down.update({f'{feat}_{scale}': DownSample(feat,scale,stride)})i+=1# 下面self.up是在定义下bilinear upsampling。它是字典形式,关键词:{feat}_{scale}, scale每*2,通道数feat就/2i=0FEATS.reverse()for feat in FEATS:for scale in SCALE[i:]:self.up.update({f'{feat}_{scale}': UpSample(feat,scale,stride)})i+=1self.conv_out = nn.Conv2d(n_feat, n_feat, kernel_size=3, padding=1, bias=bias)# 针对三个尺寸下的特征使用的SKFF,其中SKFF[0]会被使用两次self.selective_kernel = nn.ModuleList([SKFF(n_feat*stride**i, height) for i in range(height)])def forward(self, x):inp = x.clone()#col 1 onlyblocks_out = []'''inp不断地下采样,每次下采样后都做一个DAU最终blocks_out得到了三个尺寸DAU后的特征'''for j in range(self.height):if j==0:inp = self.blocks[j][0](inp)else:inp = self.blocks[j][0](self.down[f'{inp.size(1)}_{2}'](inp))blocks_out.append(inp)#rest of gridfor i in range(1,self.width):#Mesh# Replace condition(i%2!=0) with True(Mesh) or False(Plain)# if i%2!=0:if True:tmp=[]for j in range(self.height):TENSOR = []nfeats = (2**j)*self.n_feat# 下采样至三个尺寸for k in range(self.height):'''用self.select_up_down将三个不同的尺寸统一到一个尺寸上j=0时,第一个SKFF模块会将三个尺寸都统一到[bs, ch, 512, 512]j=1时,第二个SKFF模块会将三个尺寸都统一到[bs, ch*2, 256, 256]j=2时,第三个SKFF模块会将三个尺寸都统一到[bs, ch*4, 128, 128]'''tensor_tmp = self.select_up_down(blocks_out[k], j, k)TENSOR.append(tensor_tmp)selective_kernel_fusion = self.selective_kernel[j](TENSOR)tmp.append(selective_kernel_fusion)#Plainelse:tmp = blocks_out# 三个尺寸执行完SKFF后再接一个DAUfor j in range(self.height):blocks_out[j] = self.blocks[j][i](tmp[j])# 用上采样方法将三个尺寸的特征统一到一个维度上[bs, ch, 512, 512]out=[]for k in range(self.height):out.append(self.select_last_up(blocks_out[k], k))# selective_kernel[0]的权重是共享的out = self.selective_kernel[0](out)out = self.conv_out(out)out = out + xreturn outdef select_up_down(self, tensor, j, k):if j==k:return tensorelse:diff = 2 ** np.abs(j-k)if j<k:return self.up[f'{tensor.size(1)}_{diff}'](tensor)else:return self.down[f'{tensor.size(1)}_{diff}'](tensor)def select_last_up(self, tensor, k):if k==0:return tensorelse:return self.last_up[f'{k}'](tensor)
Anti-aliasing Downsampling
没看Making convolutional networks shift-invariant again的论文,这部分代码理解有点困难,我先不复制代码放这儿了,有需要可以去链接里取
https://github.com/swz30/MIRNet/blob/ca72762abe5d7b03c68332cc5738984d7102a682/utils/antialias.py#L19

若有收获,就点个赞吧
0 人点赞
