train时定义如下。
criterion = MultiboxLoss(config.priors, iou_threshold=0.5, neg_pos_ratio=3, center_variance=0.1, size_variance=0.2, device=DEVICE)
获取时使用如下。
regression_loss, classification_loss = criterion(confidence, locations, labels, boxes)
MultiboxLoss则是另写了一个类来实现
初始化就是设置了一些参数,包括:
- 事先规定好生成的anchor框
- iou阈值
- neg_pos_ratio,正负样本的比例
- 中心点偏差
- 尺寸偏差
- 计算设备
class MultiboxLoss(nn.Module):def __init__(self, priors, iou_threshold, neg_pos_ratio,center_variance, size_variance, device):"""Implement SSD Multibox Loss.Basically, Multibox loss combines classification lossand Smooth L1 regression loss."""super(MultiboxLoss, self).__init__()self.iou_threshold = iou_thresholdself.neg_pos_ratio = neg_pos_ratioself.center_variance = center_varianceself.size_variance = size_varianceself.priors = priorsself.priors.to(device)
计算过程如下。
参数包括四个:计算得到的class confidence和predicted locations,真实标注的labels和gt_locations.
confidence符合(img, -1, classes)的格式,location符合(img,-1, 4)的格式
首先hard_negative_mining用来确定哪些正负样本用来计算loss
classification_loss 通过confidence和labels[mask]计算cross entropy
location_loss通过smooth_l1_loss来计算的
最后要除以数量算平均值
Smooth L1
- 相比于L1损失函数,可以收敛得更快。
- 相比于L2损失函数,对离群点、异常值不敏感,梯度变化相对更小,训练时不容易跑飞。
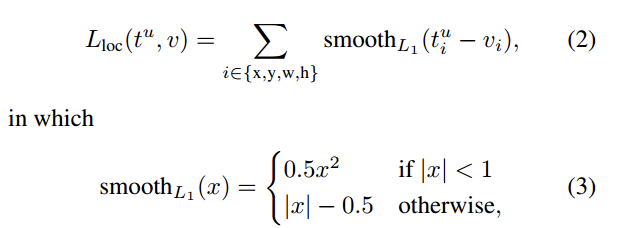
def forward(self, confidence, predicted_locations, labels, gt_locations):"""Compute classification loss and smooth l1 loss.Args:confidence (batch_size, num_priors, num_classes): class predictions.locations (batch_size, num_priors, 4): predicted locations.labels (batch_size, num_priors): real labels of all the priors.boxes (batch_size, num_priors, 4): real boxes corresponding all the priors."""num_classes = confidence.size(2)with torch.no_grad():# 不需要反向传播# derived from cross_entropy=sum(log(p))loss = -F.log_softmax(confidence, dim=2)[:, :, 0]mask = box_utils.hard_negative_mining(loss, labels, self.neg_pos_ratio)confidence = confidence[mask, :]classification_loss = F.cross_entropy(confidence.reshape(-1, num_classes), labels[mask], size_average=False)pos_mask = labels > 0predicted_locations = predicted_locations[pos_mask, :].reshape(-1, 4)gt_locations = gt_locations[pos_mask, :].reshape(-1, 4)smooth_l1_loss = F.smooth_l1_loss(predicted_locations, gt_locations, size_average=False)num_pos = gt_locations.size(0)return smooth_l1_loss/num_pos, classification_loss/num_pos
box_utils.hard_negative_mining定义如下。SSD里面有正负样本1:3的说法,不然负样本就太多了。这个就是用来抑制负样本数量的。对于每张图片,做1:3的抑制。这里有点问题,注释说是对每张图做1:3,但实际看输入应该还是基于batch做的
def hard_negative_mining(loss, labels, neg_pos_ratio):"""It used to suppress the presence of a large number of negative prediction.It works on image level not batch level.For any example/image, it keeps all the positive predictions andcut the number of negative predictions to make sure the ratiobetween the negative examples and positive examples is no morethe given ratio for an image.Args:loss (N, num_priors): the loss for each example.labels (N, num_priors): the labels.neg_pos_ratio: the ratio between the negative examples and positive examples."""pos_mask = labels > 0 # 选取的正样本,格式为(batch_size, num_priors)num_pos = pos_mask.long().sum(dim=1, keepdim=True)num_neg = num_pos * neg_pos_ratioloss[pos_mask] = -math.inf_, indexes = loss.sort(dim=1, descending=True)_, orders = indexes.sort(dim=1)neg_mask = orders < num_negreturn pos_mask | neg_mask #只要你在我划分的正样本或负样本中,我就返回1,其余就返回0,返回的是一个01的串,标志着到底该样本用不用来计算loss

若有收获,就点个赞吧
0 人点赞
