时间不太够,看论文都是粗读了,记点关键信息。
| keywords | face restoration |
|---|---|
| release time | 2020 |
| journal | |
| intorduction | |
| institution | |
| other |
Title
Progressive Semantic-Aware Style Transformation for Blind Face Restoration
Information
论文地址:https://arxiv.org/abs/2009.08709
github地址:https://github.com/chaofengc/PSFRGAN
Summary
和PSP网络有点像,在渐进式生成图像(stylegan)的基础上引入原图的信息和原图的分割结果,实现有语义信息的人脸修复
Contribution(s)
作者认为关键是提出了两个结构。
- 引入的原图特征是多尺度的
- 特征是由粗糙到精细的渐进式调制而成
Problem Statement
人脸修复Method(s)
network
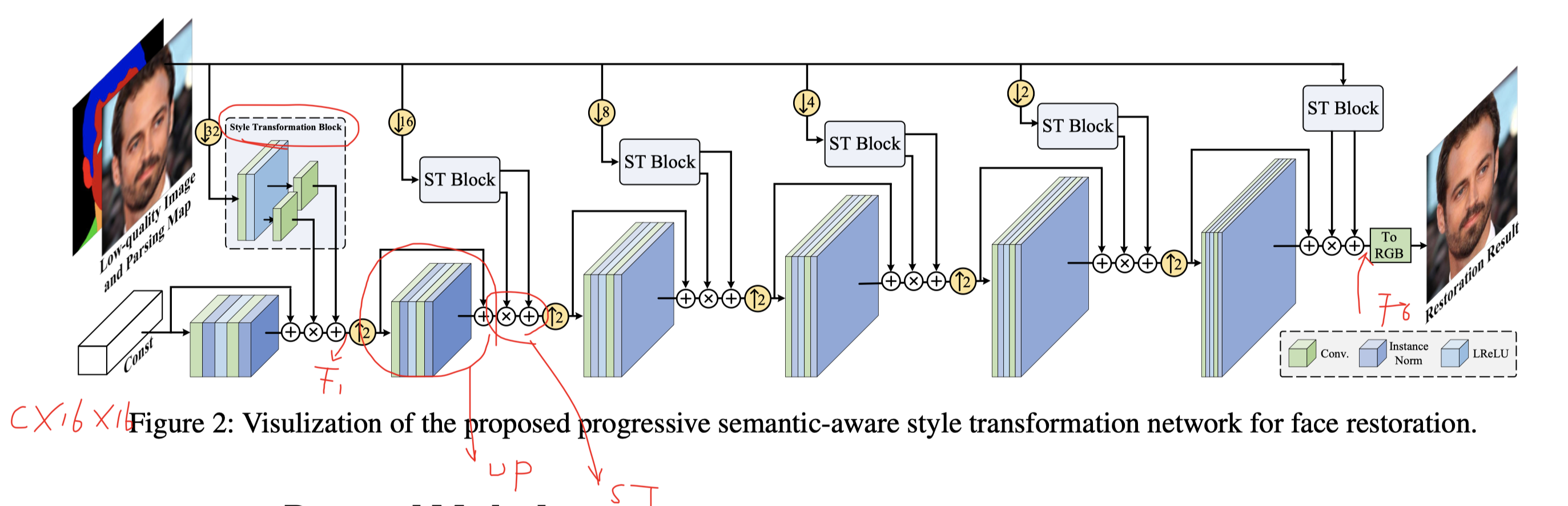
输入是c1616的随机变量,利用Resblock和upsample逐渐上采样,在这一过程中,通过作者自己提出的ST Block,实现多尺度提取yi = (yi_s, yi_b)(这个类似于stylegan中的style调制过程),将yi应用到图像的生成过程中从而得到最终图像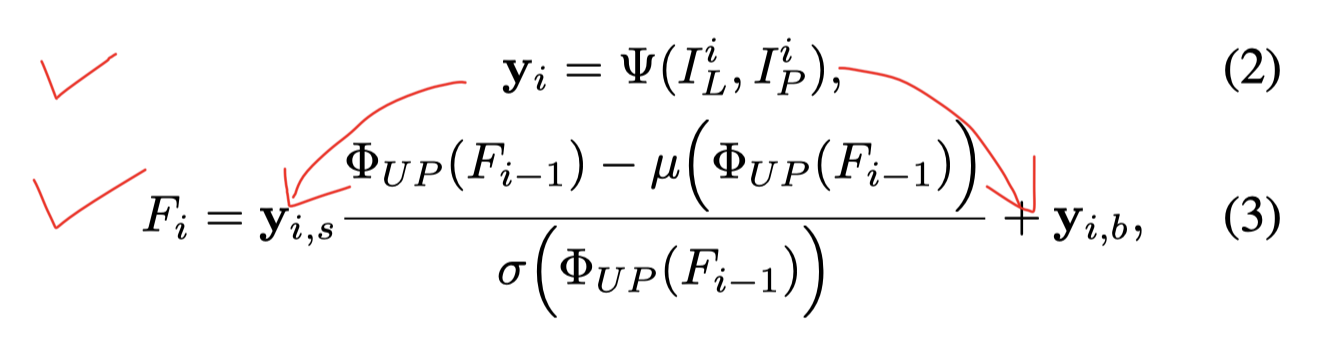
loss
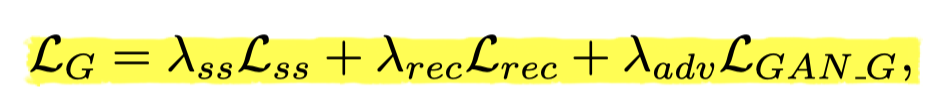
(1) Lss
作者提出了Semantic-Aware Style Loss,其实就是引入分割后的脸部区域每一块的style loss和(比如眼睛算一下,头发算一个等等)
(2) Lrec
重建loss,用的MSE,算的全图
(3)Lgan_g
gan loss,用了一个多尺度判别器,不知道这儿的多尺度是怎么实现的,到时候看一下代码
Evaluation
Conclusion
本文的生成过程大概是这样:
先纹理、再颜色啥的,有个很明显的渐进式过程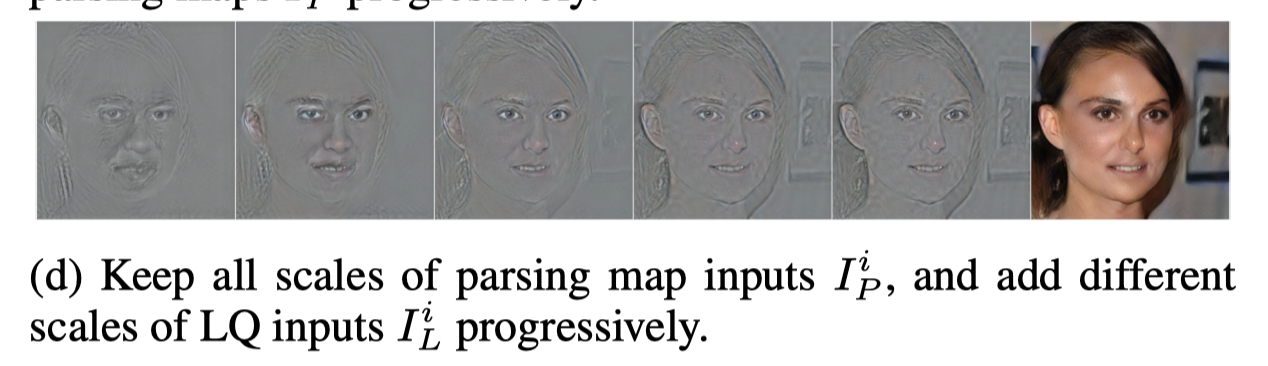
Criticism
整个过程看下来,思路和PSP其实很像。
PSP的结构: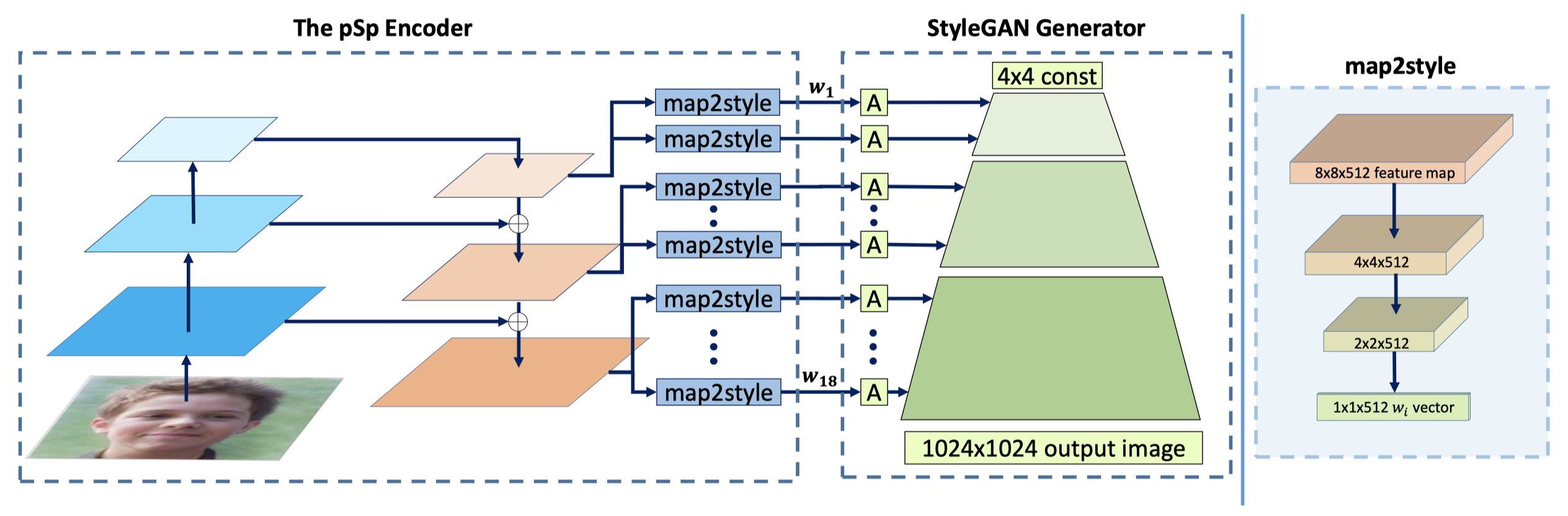
PSP也是期望从图像中获取不同的w和b用于渐进式生成中的style调制过程。
比较了一下区别:
(1)PSP对原图的操作有先下采样再上采样的过程,等于PSP Encoder自己尝试去获取语义信息; PSFR用了一个分割网络将分割结果和原图一起送进去,变相减少了获取语义信息的难度。
(2)PSP是三尺度获取style调制信息,PSFR是六尺度
(3)PSP的style调制信息是11512维的,而PSFR中的调制信息维度是随着生成图像尺度的变化而变化的。
(4)PSP直接使用了stylegan作为生成网络,PSFR自己搭了一个生成网络。
这两篇论文的关键是一样的:
在图像渐进式生成的过程中,从原图尽可能多地获取信息用来辅助生成,保留原图的信息。

若有收获,就点个赞吧
0 人点赞
